






 近期,人工智能领域取得了一系列重要进展,包括超大规模预训练模型、针对特定任务的高效算法和优化策略。大语言模型在自然语言处理中的主导地位被强调,同时研究人员探索了在神经压缩文本上训练模型的新方法和表示性微调技术。此外,论文还关注了模型优化、剪枝策略和安全挑战,这些成果推动着AI技术的应用边界。
近期,人工智能领域取得了一系列重要进展,包括超大规模预训练模型、针对特定任务的高效算法和优化策略。大语言模型在自然语言处理中的主导地位被强调,同时研究人员探索了在神经压缩文本上训练模型的新方法和表示性微调技术。此外,论文还关注了模型优化、剪枝策略和安全挑战,这些成果推动着AI技术的应用边界。
在人工智能领域的快速发展中,不断看到令人振奋的技术进步和创新。近期,开放传神(OpenCSG)传神社区发现了一些值得关注的成就包括开源社区推出的具有超大规模参数的AI模型,以及针对特定问题解决能力提升的高效算法。例如, 预训练的大型语言模型(LLM)在大多数自然语言处理任务中是当前的最新技术。同时,研究者们还开发出了新的策略,如参数高效微调(PEFT)方法等,这些策略针对特定领域的问答性能进行了优化,显著提高了模型在特定任务上的表现。这些研究成果不仅加深了对人工智能的理解,也为AI技术在各行各业的实际应用提供了强有力的支持。对于对AI和大模型感兴趣的读者来说,这些进展无疑是值得关注和学习的。传神社区本周也为AI和大模型感兴趣的读者们提供了值得一读的研究工作的简要概述和它们各自的论文推荐链接。
01 Advancing LLM Reasoning
预训练的大型语言模型(LLM)在大多数自然语言处理任务中是当前的最新技术。传神社区注意到这篇文章中有以下亮点:这是一篇介绍了Eurus的论文,这是一套专为推理优化的大型语言模型(LLMs)。Eurus模型经过Mistral-7B和CodeLlama-70B的微调后,在涵盖数学、代码生成和逻辑推理问题的多样化基准测试中,取得了开源模型中的最先进结果。
论文推荐链接:
https://portal.opencsg.com/daily_papers/WfRummN2gcqH
02 Evolutionary Optimization of Model Merging Recipes
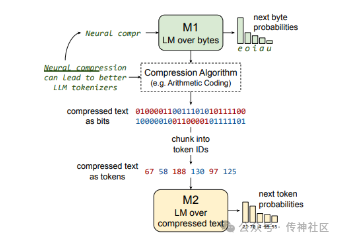
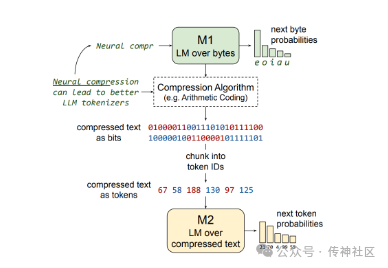
传神社区注意到这篇文章中有以下亮点:这是一篇关于训练大型语言模型(LLMs)的学术论文,论文探讨了直接在神经压缩文本上训练LLMs的可能性和优势,以及面临的挑战和解决方案。论文的主要贡献包括:概述了在神经压缩文本上训练的优势和挑战。比较了使用不同分词器训练的LLMs在比特/字节和浮点运算/字节两个维度上的表现。展示了标准的LLMs无法学习模拟简单的AC(算术编码)压缩文本。展示了GZip压缩文本可以被标准的LLMs学习,但在竞争中并不占优势。提出了一种名为Equal-Info Windows的压缩技术,并展示了它使得在神经压缩文本上的学习成为可能。
论文推荐链接:
https://portal.opencsg.com/daily_papers/RbM7mTkmGHFS
03 Representation Finetuning for LMs
传神社区注意到这篇文章中有以下亮点:这是一篇关于语言模型的参数高效微调(PEFT)方法的研究文章。文章提出了一种新的微调方法,称为表示微调(ReFT),它通过在冻结的基础模型上学习特定于任务的干预来操作隐藏表示。文章特别介绍了ReFT家族中的一个强实例,称为低秩线性子空间ReFT(LoReFT),它比现有的PEFT方法更具参数效率,同时在多个标准基准测试中实现了最先进的性能。
论文推荐链接:
https://portal.opencsg.com/daily_papers/2ZY1LsuVxWuF
04 The Unreasonable Ineffectiveness of the Deeper Layers
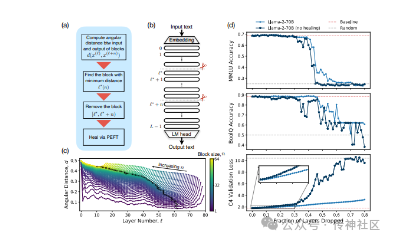
传神社区注意到这篇文章中有以下亮点:这是一篇关于大型预训练语言模型(LLMs)的剪枝策略的研究文章。文章通过实证研究,探讨了一种简单的层剪枝策略,用于减少LLMs的层数,直到移除大部分(高达一半)的层,而对不同问答基准测试的性能影响最小。研究者们通过计算层之间的相似性来确定最佳的剪枝块,并在剪枝后进行少量的微调以“修复”损伤。他们使用了参数高效的微调(PEFT)方法,特别是量化和低秩适配器(QLoRA),以确保实验可以在单个A100 GPU上完成。
论文推荐链接:
https://portal.opencsg.com/daily_papers/qGEarGvQfwpw
05 Visualization-of-Thought
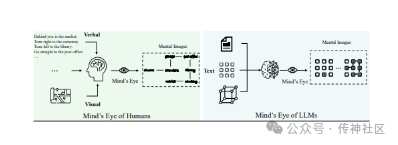
传神社区注意到这篇文章中有以下亮点:文章提出了一种名为“Visualization-of-Thought”(VoT)的提示方法,旨在通过可视化推理过程来激发LLMs的空间推理能力。这种方法受到人类通过“心智之眼”(Mind's Eye)创造未见物体和动作的心理图像的启发,有助于人类对未见世界的想象。研究者们使用VoT来处理多跳空间推理任务,包括自然语言导航、视觉导航和2D网格世界中的视觉铺砌任务。
论文推荐链接:
https://portal.opencsg.com/daily_papers/AxyVT3tEUMQA
06 Local Context LLMs Struggle with Long In-Context Learning
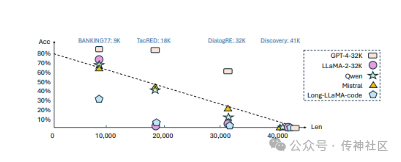
传神社区注意到这篇文章中有以下亮点:这是一篇关于大型语言模型(LLMs)在长上下文学习(Long In-context Learning,简称ICL)方面的研究文章。这篇文章介绍了一个专门的基准测试(LongICLBench),专注于极端标签分类(Extreme-label Classification)任务中的长上下文ICL。研究者们精心挑选了六个数据集,涵盖了从28到174个类别的标签范围,输入长度从2K到50K不等。这个基准测试要求LLMs理解整个输入,以识别庞大的标签空间并做出正确的预测。
论文推荐链接:
https://portal.opencsg.com/daily_papers/6TV59m7KSBxG
07 Mixture-of-Depths
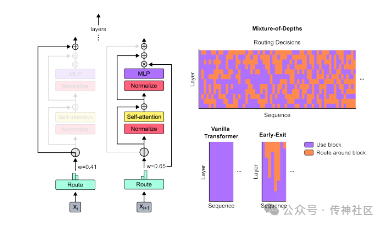
传神社区注意到这篇文章中有以下亮点:Mixture-of-Depths这项技术旨在改进基于Transformer的语言模型,通过动态地在序列的特定位置分配计算资源(FLOPs),从而优化不同层的计算分配。这种方法通过限制每层可以参与自注意力和多层感知机(MLP)计算的标记数量来强制执行总计算预算。被处理的标记是由网络使用一种顶部路由机制确定的。由于这种机制在训练前就定义好了,因此它使用的是静态计算图,与动态条件计算技术不同。MoD技术的一个关键特点是,它允许在保持总体性能的同时,减少每次前向传播所需的FLOPs,并且可以在训练后的采样中加快步进速度。
论文推荐链接:
https://portal.opencsg.com/daily_papers/SMK7pVuQ34mM
08 Many-shot jailbreaking
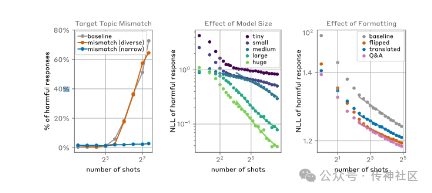
传神社区注意到这篇文章中有以下亮点:Many-shot jailbreaking这项技术可以被用来绕过大型语言模型(LLMs)开发者设置的安全防护措施。该技术通过在单个提示中包含大量特定配置的文本,可以迫使LLMs产生潜在有害的回应,即使它们被训练为不这样做。文章中提到,这种技术的基础是在LLMs的提示中包含一个假想的人类与AI助手之间的对话。这个假想对话描述了AI助手轻易地回答了用户的潜在有害问题。在对话的最后,提出一个最终的目标问题,希望得到答案。
论文推荐链接:
https://portal.opencsg.com/daily_papers/cvJqdRL8gvKy
09 Training LLMs over Neurally Compressed Text
传神社区注意到这篇文章中有以下亮点:本文研究了在神经压缩文本上训练大型语言模型的可能性,并提出了一个新颖的压缩技术“等信息窗口”来解决此难题。探讨了训练大型语言模型(LLMs)处理高度压缩文本的想法。标准子词分词器可以将文本压缩一小部分,而神经文本压缩器可以达到更高的压缩率。如果能直接训练处理神经压缩文本的LLMs,这将在训练效率、服务效率以及处理长文本中带来优点。难点在于强压缩通常产生不透明的结果,不适合学习。
论文推荐链接:
https://portal.opencsg.com/daily_papers/1bvTpiF4bCmu
10 ReFT: Representation Finetuning for Language Models
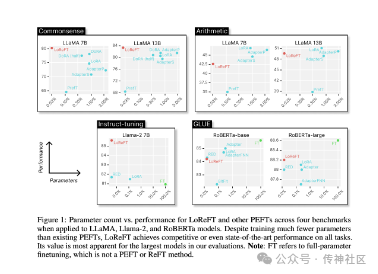
传神社区注意到这篇文章中有以下亮点:本文提供参数有效的微调(PEFT)方法寻求通过更新少量权重来适应大型模型。然而,许多先前的可解释性工作已经证明,表示方法可以编码丰富的语义信息,这表明编辑代表性可能是一个更强大的替代方案。在这里,我们通过开发一系列的表示性微调(ReFT)方法来追求这个假设。ReFT方法在冻结的基本模型上进行操作,并学习任务特定的隐藏表示干预。
论文推荐链接:
https://portal.opencsg.com/daily_papers/A5tnhzHNySBn


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









