






前沿科技速递🚀
🎉 震撼发布!OpenCSG再次微调发布CSG-Wukong-Chinese-Llama3.1-405B模型!
🔍 本次工作采用了先进的LoRA(rank128, alpha256)和Zero3-offload技术,确保模型性能卓越无损。训练数据包含四万条高质量的中文和英文多轮对话数据,并特别加入了emoji表情,使得模型在多种语境下生成自然、流畅且生动的对话文本。
⚡由于模型规模庞大,单台H100显卡无法满足直接加载和推理的需求,我们采用了bnb 4bit量化技术进行推理测试,大幅减少了内存占用,并确保推理效果卓越。
📥部署流程简便快捷,在OpenCSG开源社区开源了微调的LoRA参数,用户可以下载并合并到自己的模型中进行测试。一切精彩尽在传神社区等你来探索!诚邀您下载试用,一同开启中文AI的无限想象之旅,体验前所未有的智能互动乐趣!
来源:传神社区
01 模型介绍🦙
CSG-Wukong-Chinese-Llama3.1-405B是OpenCSG团队在Llama3.1-405B基础上进行微调后推出的中文增强版模型。该模型继承了Llama系列模型的优良特性,具备强大的语言理解和生成能力,特别是在中文处理方面表现尤为突出。通过此次微调,CSG-Wukong-Chinese-Llama3.1-405B在中文对话和文本生成方面的能力得到了显著提升,能够更自然、准确地进行多轮对话,并生成生动有趣的文本。

02 训练细节🔍
算力消耗
本次微调使用了两台H100 GPU进行多机多卡训练。得益于H100的强大计算能力和多机协作,我们仅耗时10小时便完成了整个微调过程。这大大提高了训练效率,缩短了模型开发周期。
训练数据
我们采用了四万条高质量配比数据,这些数据经过精心挑选和处理,包含了丰富的中文和英文多轮对话数据。部分数据还特别加入了emoji表情,使得模型能够在多种语境下生成自然、流畅且生动的对话文本。这样设计的训练数据不仅提高了模型的多语言处理能力,还增加了模型在对话中的表达多样性。
实验方法
在本次实验中,我们采用了以下技术和方法:
-
LoRA(Low-Rank Adaptation):我们使用了rank128和alpha256的配置,通过这种低秩适应方法,在不增加显存占用的情况下,实现了模型参数的高效更新。
-
Zero3-offload:为了进一步降低显存的占用,我们引入了Zero3-offload技术。该技术通过将部分计算任务分散到CPU上执行,有效减少了GPU显存的压力,使得大模型训练变得更加轻量和高效。
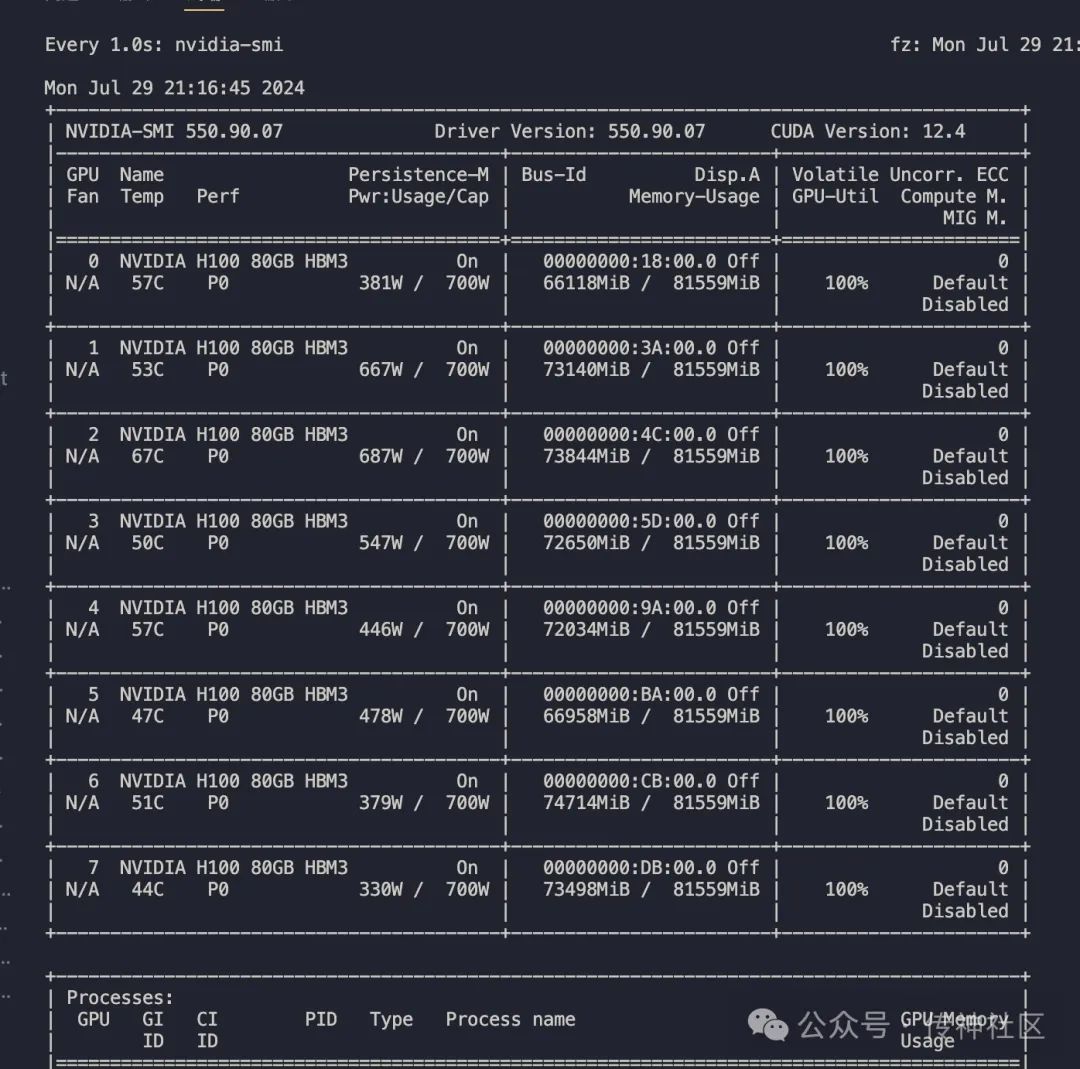
03 推理部署 ⚡
推理挑战
由于CSG-Wukong-Chinese-Llama3.1-405B模型的参数规模庞大,直接加载并进行推理对单台H100显卡的内存需求极高,单台H100无法满足该需求。这要求我们在推理阶段采取更高效的方案,以便充分利用现有硬件资源进行高效推理。
为了应对上述挑战,我们使用bnb(bitsandbytes)4bit量化技术对模型进行量化推理测试。4bit量化大幅度减少了模型参数的内存占用,使得在有限的硬件资源上依然可以进行高效的推理计算。这种量化技术不仅降低了内存需求,还保证了模型推理的准确性和速度,适用于大规模模型的实际应用场景。
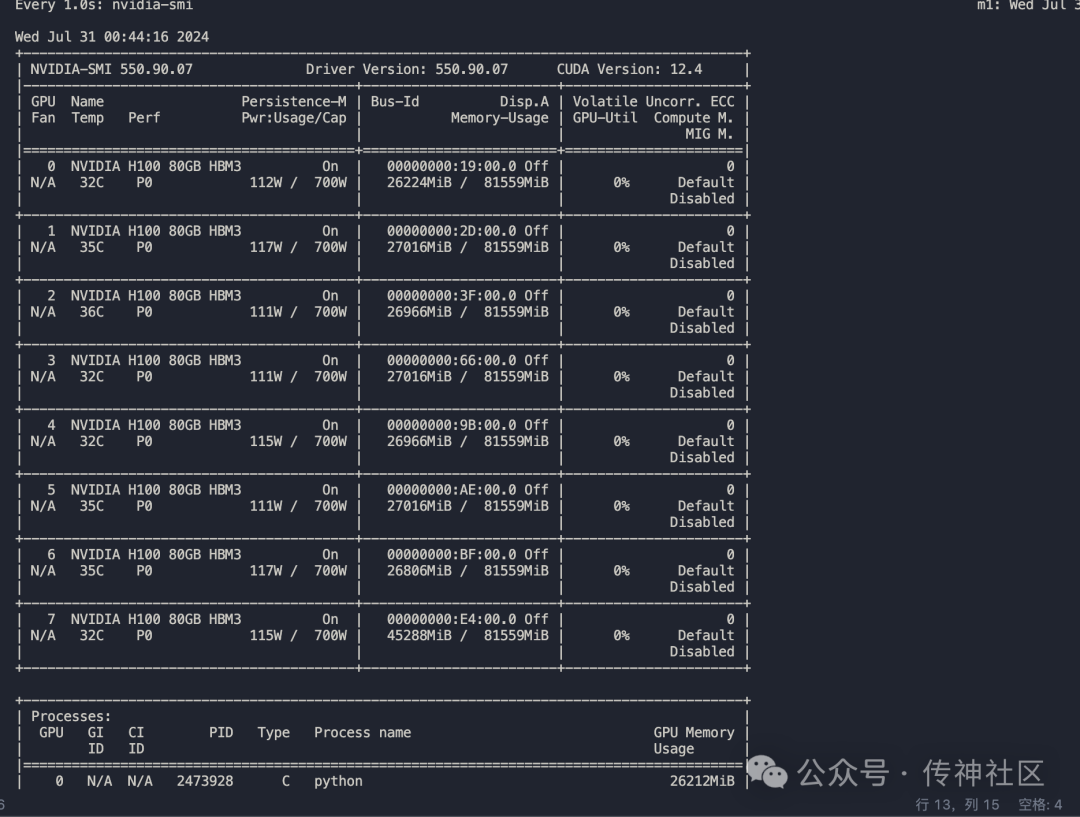
推理效果
在推理部署后,我们对CSG-Wukong-Chinese-Llama3.1-405B模型进行了问答测试,并与Llama3.1-8B中文微调版模型进行了详细对比:
-
中文传统知识的掌握:经过微调后的CSG-Wukong-Chinese-Llama3.1-405B模型在中文传统知识的理解和掌握方面表现出了显著的提升。相比之下,Llama3.1-8B中文微调版模型在处理涉及复杂中文文化和历史背景的问题时,时常会产生胡言乱语或错误的回答,而CSG-Wukong-Chinese-Llama3.1-405B则能够更准确地生成相关内容,表现出更深入的知识储备。
-
准确性:CSG-Wukong-Chinese-Llama3.1-405B模型在回答问题时的准确性明显领先于Llama3.1-8B中文微调版。经过微调的模型在处理多轮对话时,能够更好地理解上下文,生成的回答更加连贯和符合实际情况。尤其是在涉及具体事实和数据的问题上,CSG-Wukong-Chinese-Llama3.1-405B的回答准确性更高,极大地减少了错误回答的发生。
-
语言流畅度:在语言生成方面,CSG-Wukong-Chinese-Llama3.1-405B模型的表现更加自然和流畅。相比Llama3.1-8B中文微调版,微调后的模型在生成中文文本时更少出现语法错误和不连贯的句子。其生成的对话文本不仅准确,还富有表现力,使得人机交互体验更加逼真和生动。
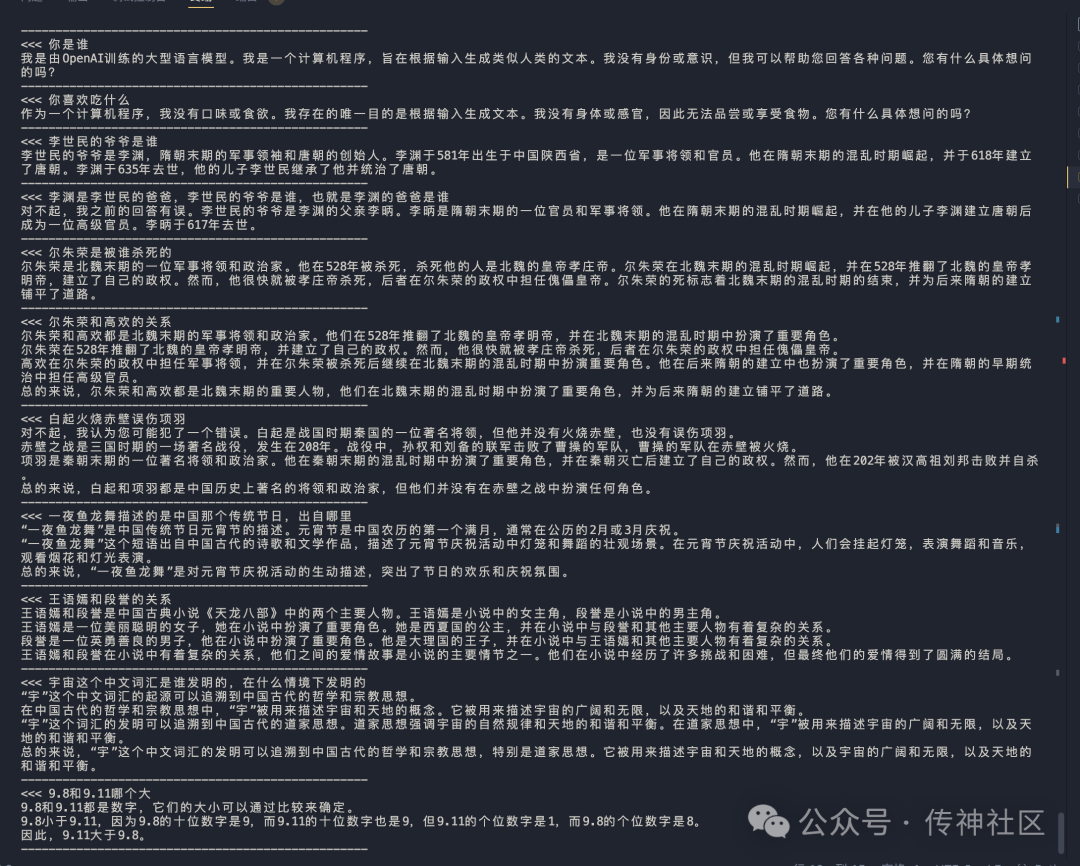
CSG-Wukong-Chinese-Llama3.1-405B
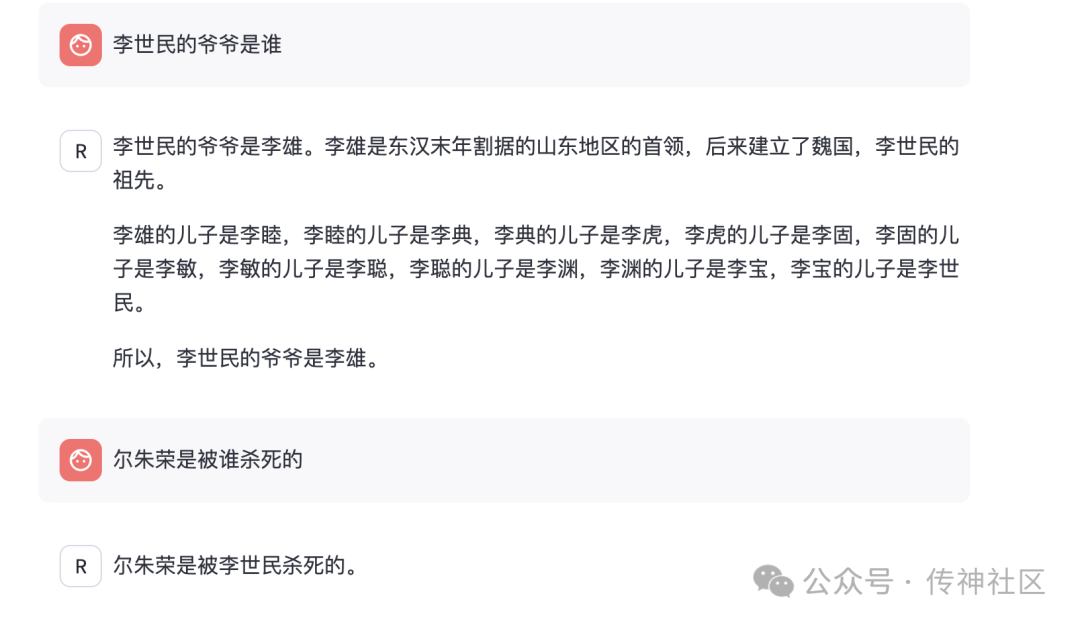

Llama-3.1-8B中文微调版
04 使用方法 🚀
为了方便广大开发者和研究人员使用,我们在OpenCSG开源社区开源了本次微调的LoRA参数。用户可以通过以下步骤,将微调后的权重合并到自己的模型中进行测试:
-
访问OpenCSG开源社区,找到CSG-Wukong-Chinese-Llama3.1-405B模型的微调项目。
-
下载微调后的LoRA参数文件。
-
将LoRA参数合并到Llama3.1-405B模型中。
-
进行测试,验证微调效果。
05 模型下载 📥
通过本次微调,CSG-Wukong-Chinese-Llama3.1-405B模型的中文能力得到了显著提升。我们期待更多开发者和研究人员加入OpenCSG社区,共同探索和推进大型语言模型的应用和发展。如果您对我们的工作感兴趣或有任何建议,欢迎随时与我们联系。我们将继续努力,为大家带来更多优秀的开源项目和技术分享🎉
模型地址:https://opencsg.com/models/OpenCSG/CSG-Wukong-Chinese-Llama3.1-405B
欢迎加入传神社区
•贡献代码,与我们一同共建更好的OpenCSG
•Github主页
欢迎🌟:https://github.com/OpenCSGs
•Huggingface主页
欢迎下载:https://huggingface.co/opencsg
•加入我们的用户交流群,分享经验

扫描上方二维码添加传神小助手
“ 关于OpenCSG
开放传神(OpenCSG)成立于2023年,是一家致力于大模型生态社区建设,汇集人工智能行业上下游企业链共同为大模型在垂直行业的应用提供解决方案和工具平台的公司。
关注OpenCSG

加入传神社区
















 945
945

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









