







 本文概述了视觉语言预训练(VLP)在视频文本任务中的应用,包括视频检索、视频问答和视频字幕生成。文章详细介绍了双编码器和融合编码器模型架构,以及视频编码器从离线特征提取到端到端学习的发展。同时,涵盖了预训练对象,如VTC、MLM、VTM和FOM等在视频-文本模型中的作用。
本文概述了视觉语言预训练(VLP)在视频文本任务中的应用,包括视频检索、视频问答和视频字幕生成。文章详细介绍了双编码器和融合编码器模型架构,以及视频编码器从离线特征提取到端到端学习的发展。同时,涵盖了预训练对象,如VTC、MLM、VTM和FOM等在视频-文本模型中的作用。
视频本质上包含多种形式,并且已被用作测试AI系统如何感知世界的缩影。在本章中,我们对视觉语言预训练(VLP)在视频文本任务中的应用进行了系统回顾。
我们从介绍流行的视频文本任务开始。我们回顾了典型视频文本模型的架构,该架构包括视频编码器、文本编码器和多模态融合模块。我们将代表性的视频语言模型分为两类:
(i)双编码器,其中视频和文本分别编码,使用轻量级的多模态融合层或操作(如点积)来融合视频和文本特征;
(ii)融合编码器,在视频编码器和文本编码器之上通常采用多个额外的Transformer层来捕捉视频和文本特征之间的深层交互。
1. 视频-文本任务
我们介绍了三种流行的视频-文本任务:文本到视频检索、视频问答和视频字幕生成。这些任务的示例如图1所示。

(ii) 视频问答,包括多项选择和开放式设置;(iii) 视频描述生成,包括单句描述和段落描述。
1.1 文本到视频检索
文本到视频检索任务是根据自然语言查询从大规模视频语料库中检索相关的视频或视频片段。该任务可以根据设置进一步分为三种类型。
• 视频检索(Video retrieval :VR)
从大规模视频语料库中检索相关视频。在这种设置下,文本查询应该对视频进行概述描述。以图1例子,“一个人和狗一起玩飞盘”总结了第一个视频中发生的事件。这类似于文本到图像检索,评估指标使用Recall@K(K=1, 5, 10, 100)。
• 单视频时刻检索(Single Video Moment retrieval:SVMR)
从给定视频中定位检索到视频中的视频片段。文本查询仅与整个视频的特定片段相关。在图1中,“一个狗拿着一个飞盘在跑”只能与第一个视频中t = 3, 4, 5的视觉内容相关联。同样,评估指标使用Recall@K(K=1, 5, 10, 100),并约束真实提议与预测提议之间的时间交并比(tIoU)(例如,tIoU≥0.5/0.7)。
• 视频语料库时刻检索(Video Corpus Moment Retrieval:VCMR)
将相关视频片段池从单个视频扩展到大规模视频语料库。它可以被视为VR和SVMR的组合。AI模型不仅需要从视频语料库中检索相关视频,还需要定位检索到视频中的视频片段,以便文本查询可以描述该视频片段。例如,给定查询“一个狗拿着一个飞盘在跑”,模型需要正确匹配到第一个视频,并将文本查询限定在t = 3到t = 5的视频片段中。类似地,VCMR使用Recall@K(K=1, 5, 10, 100)与tIoU≥0.5/0.7进行评估。
大多数VLP模型在VR上进行评估。流行的VR数据集包括(i)MSVD、MSRVTT、LSMDC、YouCook2和VATEX用于单句到视频的检索; (ii)DiDeMo和ActivityNet Captions用于段落到视频的检索。段落到视频检索数据集是通过转换更具挑战性的SVMR或VCMR任务收集的数据集。在DiDeMo和ActivityNet Captions中,每个段落的句子都带有相关的时间间隔注释。最近,提出了TVR和How2R,以引入额外的对话/描述信息来进行具有多通道视频输入的VCMR。
1.2 视频问答(VQA)
给定一个视频-问题对,视频问答需要AI模型根据视频内容回答问题。有两种设置,两者均通过准确率进行评估。
• 多项选择视频QA
模型需要从一组固定的少量答案选项中识别正确答案(例如4-5个答案选项)。由于答案被限制在有限集合中,因此通常将该任务作为分类问题来公式化。在文献中,带有少量文本候选项的视频到文本检索任务通常被视为多项选择QA任务。
• 开放式视频QA
正确答案可以由整个词汇表中的单词自由构成。常见做法是首先从训练集中选择出最常见的答案,形成一个有限的答案词汇表,并将其公式化为分类任务。
1.3 视频描述
视频描述任务是针对给定的视频生成一段自然语言的描述,这是三个任务中唯一一个生成任务。期望生成的标题能够全面描述视频的内容,包括感兴趣的事件或物体、随时间变化的事件或物体的行为以及它们之间的关系。大多数流行基准要求生成一个单句标题来概括整个视频内容。虽然简短的视频可能只需要一个句子就可以概括发生的事件,但对于较长的视频,描述通常需要多个句子段落,就像密集标注基准一样。最近,提出了多模态视频标题数据集,其中包含描述视频中的视觉场景和对话/字幕的标题。标题生成性能使用标准文本生成指标进行评估。
2. 模型框架
概述:给定一对文本句子w和视频v,典型的视频-文本模型首先通过文本编码器和视频编码器分别提取文本特征序列和视觉特征
。其中,N是句子中的标记数,M是视频的视觉特征数,具体取决于所使用的特定视觉编码器。多模态融合模块将这些特征投影到共享嵌入空间中,以产生跨模态表示。我们广泛地将视频-文本模型分为两类,基于多模态融合模块的设计:
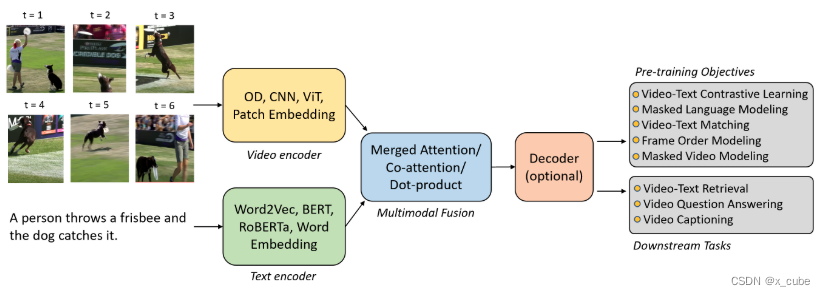
• 双编码器
其中视频和文本分别进行编码,使用轻量级操作(例如点积或余弦相似度)建模视频和文本特征之间的交互。这种设计在文本到视频检索中对于快速搜索非常有利,也广泛应用于通过对比视频-文本预训练来提高视频表示。然而,这种浅层跨模态交互对于视频问答和字幕生成任务来说不够有效,如Support-Set所示。因此,需要额外的文本解码器来进行字幕生成。
• 融合编码器
在视频编码器和文本编码器的顶部添加额外的Transformer层,以捕捉视频和文本特征之间的细粒度交互。具有深度融合编码器的杰出作品包括VideoBERT、UniVL、ClipBERT和MERLOT,它们在视频问答和解释生成任务上表现出色。虽然在文本到视频检索任务上也取得了竞争性的性能,但与双编码器相比,融合编码器的计算成本更高。
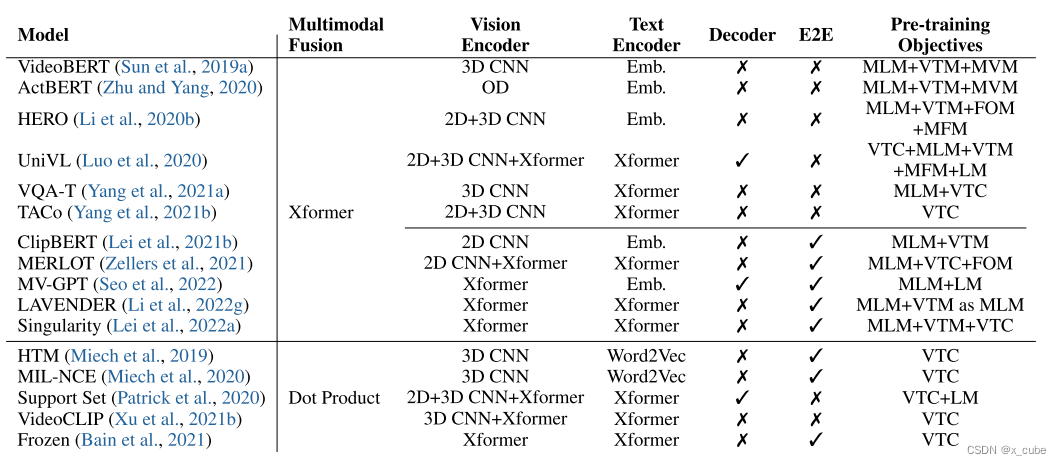
E2E:端到端。CNN:卷积神经网络。OD:目标检测器。Xformer:Transfoemer。Emb.:嵌入。 MLM/MFM/MVM:掩码语言/帧/视频建模。VTM:视频-文本匹配。VTC:视频-文本对比学习。FOM:帧顺序建模。LM:语言建模。
视频-文本模型的最终输出可以直接通过跨模态表示产生的多模态融合模块(对于仅编码器模型)或添加在多模态融合模块和输出层之间的解码器来生成。表1总结了用于视频-文本任务的代表性VLP模型,包括融合编码器模型(上方方块)和双编码器模型(下方方块)。接下来,我们将详细回顾每个组件。
2.1 视频编码器
视频编码器与静态图像不同,视频片段由随时间演变的帧/图像序列组成。因此,视频编码器不仅需要捕获每一帧的空间信息,还需要捕获帧之间的时间动态。随着时间的推移,视频编码器从多个离线特征提取器发展为一个端到端学习的统一视频编码器。视频编码器的变化也反映了VLP在视频-文本任务中的一般趋势,即从两阶段预训练到端到端预训练
• 多离线特征提取器
早期的方法是使用固定视频特征提取器的组合,例如预先训练用于图像分类的2D CNNs(例如ResNet),预先训练用于动作识别的3D CNNs(例如I3D))和对象检测模型(例如Faster RCNN)。这些视频特征被进一步处理为与文本输入类似的格式或投影到与文本表示相同的高维空间中。
例如,VideoBERT通过将预先提取的视频特征进行分层向量量化来生成一系列“视觉标记”(类似于文本标记)。这些视觉标记来自S3D在Kinetics上预训练的层次化向量量化。ActBERT通过将来自3D CNN的动作特征序列和来自Faster R-CNN的区域对象特征序列组合来表示视频。然后,将特定标记([ACT]表示动作,[REGION]表示对象)的可学习嵌入添加到特征之前,再将其输入到多模态融合模块中。HERO 将3D Slowfast 特征和与视频表示相同帧速率提取的2D ResNet-101特征进行连接。通过全连接层将连接后的视频特征投影到一个隐藏空间中,然后添加一个位置嵌入,该嵌入编码输入帧特征的时间顺序。
• 以端到端方式学习的视频编码器
尽管基于预先提取的视频特征的模型取得了强大的性能,但这些固定特征与目标视频-文本任务/领域之间存在一定程度的不匹配。离线特征提取器通常在不同的领域中进行纯视觉任务的训练。为了解决这个问题,研究人员试图在视频-文本预训练期间以端到端(E2E)的方式优化视频编码器。与使用多个视频编码器相比,这需要更多的计算资源,因此使用单个视频编码器。
例如,HTM使用随机初始化的I3D从零开始学习视频表示。在ClipBERT中,使用预先训练用于对象检测的ResNet-50以及时间平均池化来生成视频表示。随着ViTs的发展,最近的端到端模型采用了完全基于Transformer的架构。Frozen将几个空时自注意力块插入到预先训练的ViT中,通过对比视频文本预训练学习全局视频表示。MV-GPT和LAVENDER直接通过视频视觉变压器(例如ViViT)和视频Swin Transformer。
2.2 文本编码
首先,文本输入被分词成一系列的标记以获得标记的嵌入。在BERT-like模型广泛采用视频-文本预训练之前,早期的双编码器模型(Miech等人,2019,2020)利用预先训练好的word2vec嵌入(Mikolov等人,2013a),然后进行最大池化操作以获得整体句子表示。最近的许多工作遵循BERT的标准文本预处理步骤,将文本分词成WordPiece序列(Wu等人,2016),并在序列的开头和结尾插入两个特殊标记([CLS]和[SEP])。由单词嵌入、位置嵌入和层归一化层组成的单词嵌入层用于将这些标记嵌入到高维连续空间中的向量中。对于双编码器模型,学习到的嵌入是深度Transformer网络产生的特征向量(Patrick等人,2020;Bain等人,2021;Xu等人,2021b)。对于融合编码器模型,它们可以直接输入到多模态融合模块(Tang等人,2021c;Xu等人,2021a),其中单词嵌入层是唯一的特定于文本的模型组件,或者在多模态融合之前通过几个Transformer层进行处理(Yang等人,2021a,b;Seo等人,2022)。
2.3 多模态融合
对于HTM和MNCE这样的双编码器模型,从视频/文本编码器提取的全局视频/文本表示通过轻量级的内积在共同的语义空间中对齐。对于融合编码器模型来说,最受欢迎的设计是merged attention,其中文本和视频特征简单地连接起来,然后输入到一个单一的Transformer块中。在最近的一项研究中,作者在自注意力和前馈层之间的顶部几个Transformer层中插入了交叉注意力模块,以使文本特征能够关注可变长度的视觉特征序列。这类似于co-attention。但不同之处在于只使用了视频到文本的交叉注意力模块。
2.4 只有编码器 vs. 编码器-解码器
与图像文本模型类似,大多数现有的视频文本模型采用了编码器-仅的架构,直接通过输出层从跨模态表示生成最终输出。UniVL、MV-GPT、Support Set是具有编码器-解码器架构的典型作品,其中在编码器和输出层之间添加了一个解码器。在这些作品中,解码器经过预训练,并在下游任务中用于自回归生成视频解释。这种说明性的比较可以直接应用于视频-文本输入,只需将输入图像替换为一系列输入视频帧即可。
3. 预训练对象
3.1 和图文任务的预训练对象一样
仅仅将图像换成了图片,其他一样。
1.VTC:Video-Text Contrastive Learning 视频文本对比学习
2. MLM:Masked Language Modeling 掩码语言建模
3. VTM: Video-Text Matching 匹配关系
2. MVM:Masked Video Modeling 掩码视频建模
3.2视频文本特有的预训练对象
帧顺序建模(FOM)
FOM被提出来对视频中发生的事件或动作的时间顺序进行建模。在训练过程中,我们对随机选择的一定比例的输入帧(或帧特征)进行置乱,然后训练模型以显式恢复正确的时间顺序。探索了两种变体,包括如在HERO中重建这些混洗帧的绝对时间顺序(Li等人,2020 b),以及如在MERLOT中那样预测每对帧之间的相对顺序(Zellers等人,2021年)。在这两个作品中,FOM被应用于与时间接地文本配对的视频,例如字幕或ASR输出。
3.2.1 绝对时间顺序的FOM:在时间t,让我们将视频帧输入表示为vt,将时间接地句子表示为wt。FOM的输入是(i)所有字幕句子{wt};(ii)视觉帧{Vt};以及(iii)重排序索引r = {ri}R i=1 ∈ NR,其中R是重排序帧的数量,并且r是重排序索引的集合。在训练期间,随机选择15%的帧以进行混洗,并且目标是沿着时间维度重构它们的原始顺序,表示为t = {ti} Ri =1,其中ti ∈ {1,.,Nv}。FOM被公式化为一个分类问题,其中t是重排序帧的地面真值标签。最终目标是最小化负对数似然:LFOM(θ)= −艾德R i=1 log Pθ([ri,ti])。(5.4)
3.2.2 具有相对时间顺序的FOM:在训练过程中,40%的时间,整数n,指示要随机混洗的帧数,首先从[2,T]中随机选取,给定T个输入帧。然后,随机选择n个帧进行随机加扰。在混洗之后,帧与文本输入一起被馈送到模型中以学习联合视频语言表示。对于时间步长为ti和tj的一对帧(在混洗之后),我们将它们的隐藏状态连接起来,并将结果通过两层MLP,预测是否ti < tj or ti >tj。类似地,具有相对时间顺序的FOM可以使用交叉熵损失来优化。
参考:Vision-Language Pre-training: Basics, Recent Advances, and Future Trends

















 3423
3423

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









