










 本文汇总了近期图像处理领域的研究进展,包括通过层次风格解缠实现可控的图像到图像转换,探讨有效模型设计中通道维度的重要性,以及重新审视卷积操作并提出反卷积概念。这些工作旨在提升模型性能,增强转换的可控性和网络效率。同时,还介绍了预训练模型在Transformer和对象检测中的应用。
本文汇总了近期图像处理领域的研究进展,包括通过层次风格解缠实现可控的图像到图像转换,探讨有效模型设计中通道维度的重要性,以及重新审视卷积操作并提出反卷积概念。这些工作旨在提升模型性能,增强转换的可控性和网络效率。同时,还介绍了预训练模型在Transformer和对象检测中的应用。
/1 Image-to-image Translation via Hierarchical Style Disentanglement
通过层次风格解缠的图像到图像的转换
paper:https://arxiv.org/abs/2103.01456
code:https://github.com/imlixinyang/HiSD
多标签和多风格的图像到图像的转换显著发展,但是由于标签中未探索的独立性和排他性,现有的工作由于涉及对转换结果的不受控制的操作而失败。在本文中,我们提出层次风格解缠(HiSD)来解决这个问题。具体地说,我们将标签组织成一个分层的树结构,其中独立的标签、独占的属性和分离的样式从上到下被分配。相应地,设计了一个新的转换过程来适应上述结构,其中的风格被识别为可控制的转换。
(1)我们建议HiSD(Hierarchical Style Disentanglement)通过将标签组织成一个层次结构来解决最近的多标签和多样式图像到图像转换方法中的问题,其中独立标签、专有属性和纠缠的样式从上到下分配。
(2)要使标记和属性识别出样式,要重新设计模块、阶段和目标。对于无监督的样式分离,引入了两种体系结构改进,以避免全局操作和在转换过程中要操作的隐式属性。
!!!图像彩色化可以理解为彩色图像到灰度图像的转换,因此这个算法思想是可以借鉴的 。GAN的不稳定性和图像彩色化结果的多模态性,导致了结果的不确定性,一般的方法是加强GAN的稳定性和选择定性的数据集进行训练,但同时也可以根据上述思想重新设计网络结构。缺点在于整个网络架构的改动可能会导致效果的极差,结果不确定。
/2 Rethinking Channel Dimensions for Efficient Model Design(重新考虑通道尺寸以进行有效的模型设计)
paper:https://arxiv.org/abs/2007.00992
code:https://github.com/clovaai/rexnet
在有限的计算成本内设计一个有效的模型是具有挑战性的。轻量化模型的准确性受到了设计惯例的进一步限制:通道尺寸的stage-wise configuration分段配置,它看起来像网络阶段的分段线性函数。在本文中,我们研究了一种有效的通道维度构型,使其具有比常规的更好的性能。为此,我们通过分析输出特征的秩,实证研究了如何正确设计一层输出特征。然后,我们通过搜索网络结构来研究模型的信道配置在计算代价约束下的信道配置。在此基础上,我们提出了一种简单而有效的通道结构,可以通过层指数参数化。
- 关于单层设计的研究
- 网络架构的探索,涉及到一个简单而有效的参数化的通道配置
!!!当前深度学习中,轻量化模型一直是一个很热的研究方向,但同时网络越深,效果越好,所以二者需要有一个很好的平衡。有一个更好的设计思路,也会使得模型的性能更好。同样,缺点在于整个网络架构的改动可能会导致效果的极差,结果不确定。
/3 Inverting the Inherence of Convolution for Visual Recognition(颠倒卷积的固有性以进行视觉识别)
paper:https://arxiv.org/pdf/2103.06255.pdf
卷积一直是现代神经网络的核心要素,引发了视觉深度学习的浪潮。在这项工作中,我们重新考虑了视觉任务标准卷积的固有原理,特别是与空间无关和特定于通道的方法。取而代之的是,我们通过反转前述的卷积设计原理(称为卷积)提出了一种用于深度神经网络的新颖atomic操作。此外,我们还对最近流行的自注意力运算符进行了demystify处理,并将其作为复杂化的实例包含在我们的involution家族中。可以将提出的involution算子用作基础,以构建用于视觉识别的新一代神经网络。
https://blog.csdn.net/smile909/article/details/115257004
!!!设计一个新的操作模块,可以将其应用尝试有效性。
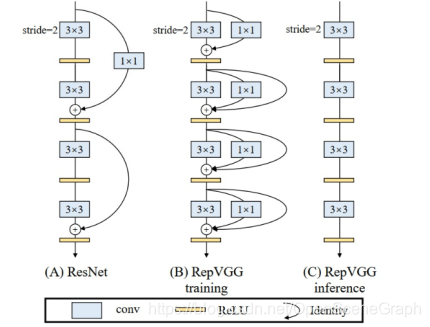
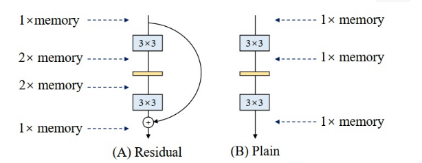
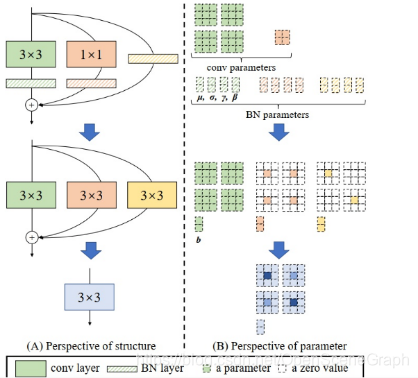
/4 RepVGG: Making VGG-style ConvNets Great Again
paper:https://arxiv.org/abs/2101.03697
code:https://github.com/megvii-model/RepVGG
RepVGG:极简架构,SOTA性能,让VGG式模型再次伟大
我们提出了一个简单但强大的卷积神经网络架构,该架构具有类似于VGG的主体,该主体仅由3x3卷积和ReLU的堆栈组成,而训练时间模型具有多分支拓扑。训练时间和推理时间架构的这种解耦是通过结构重新参数化(re-parameterization)技术实现的,因此该模型称为RepVGG。
!!!改动CNN架构,也可以将其应用尝试有效性
最近的计算机视觉方向,有关图像处理的论文:Transformer
Transformer Interpretability Beyond Attention Visualization(注意力可视化之外的Transformer可解释性)
paper:https://arxiv.org/pdf/2012.09838.pdf
code:https://github.com/hila-chefer/Transformer-Explainability
UP-DETR: Unsupervised Pre-training for Object Detection with Transformers
paper:https://arxiv.org/pdf/2011.09094.pdf
无监督预训练检测器:
https://www.zhihu.com/question/432321109/answer/1606004872
Pre-Trained Image Processing Transformer(底层视觉预训练模型)
paper:https://arxiv.org/pdf/2012.00364.pdf

















 2269
2269

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









