





 本文探讨了在深度学习中,批归一化(batch-norm)常用于缓解网络数值过大的问题,但在序列翻译任务中,由于样本长度不一,批归一化可能导致误差。层归一化(layer-norm)则能有效解决这个问题,确保每个序列内词语的向量规模一致,减少误差抖动,提高模型的稳定性和翻译质量。
本文探讨了在深度学习中,批归一化(batch-norm)常用于缓解网络数值过大的问题,但在序列翻译任务中,由于样本长度不一,批归一化可能导致误差。层归一化(layer-norm)则能有效解决这个问题,确保每个序列内词语的向量规模一致,减少误差抖动,提高模型的稳定性和翻译质量。
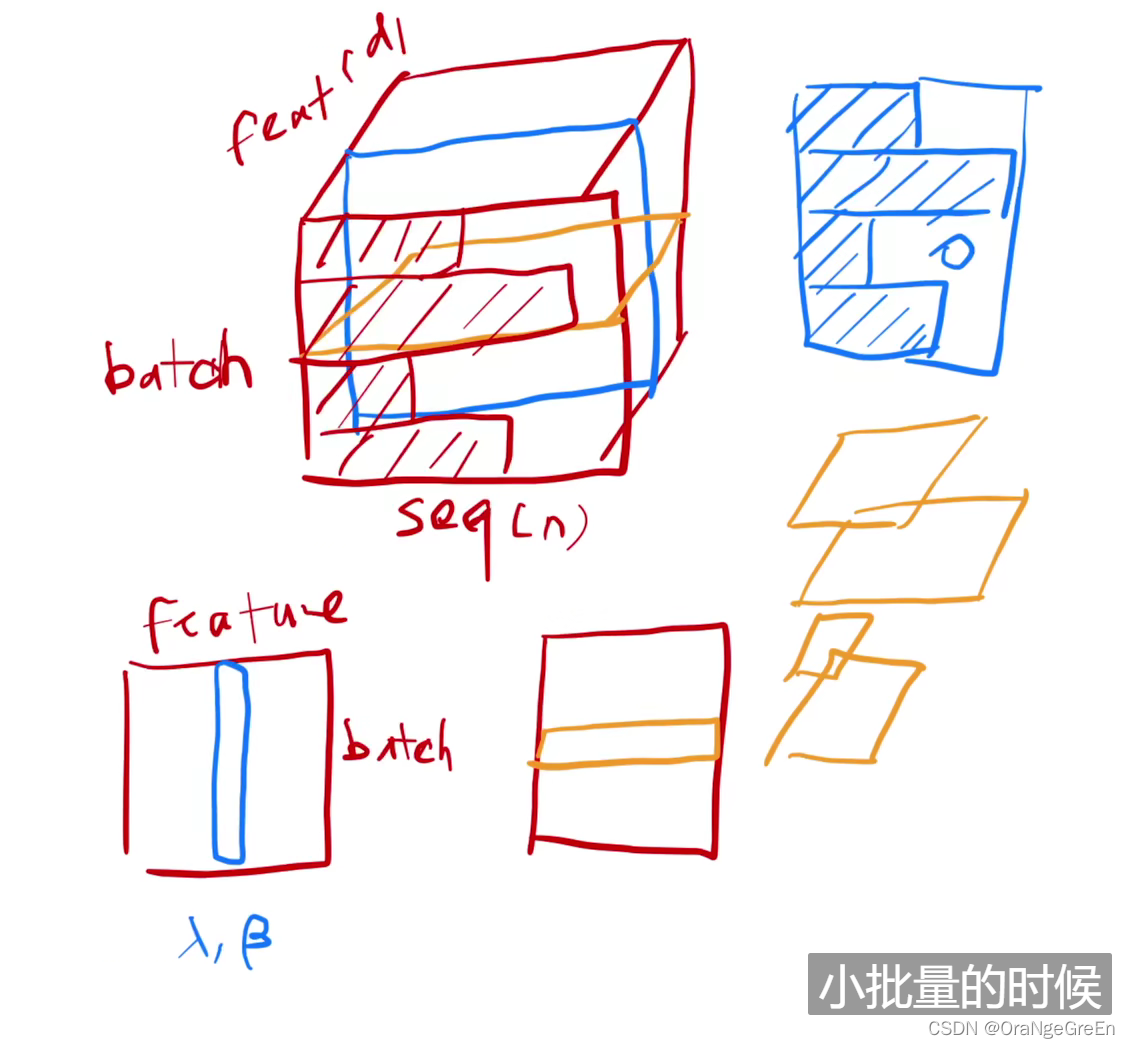
感谢沐神的讲解。
以往由于深度网络造成的网络数值偏大,担心梯度受此影响,使用batch-norm将其标准化减小较深位置的梯度下降受此大数字的影响。
时序的翻译任务中,样例长短不一,由词语翻译而成的含义向量应该都是在同一个规模水平的上向量,如果仍然使用batch-norm,由于为了补齐长短不一的样例而添加进去的0使得较长序列中词语的含义向量规模相对变小,较短序列中的词转换为含义向量的规模相对变大。平白无故增添了误差抖动。
使用layer-norm保证每个序列中词语转成的含义向量在同一规模上。

感谢沐神的讲解。
以往由于深度网络造成的网络数值偏大,担心梯度受此影响,使用batch-norm将其标准化减小较深位置的梯度下降受此大数字的影响。
时序的翻译任务中,样例长短不一,由词语翻译而成的含义向量应该都是在同一个规模水平的上向量,如果仍然使用batch-norm,由于为了补齐长短不一的样例而添加进去的0使得较长序列中词语的含义向量规模相对变小,较短序列中的词转换为含义向量的规模相对变大。平白无故增添了误差抖动。
使用layer-norm保证每个序列中词语转成的含义向量在同一规模上。
 4万+
8967
4万+
8967

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























