






## 说明
### EV_SDK的目标
开发者专注于算法开发及优化,最小化业务层编码,即可快速部署到生产环境,共同打造商用级高质量算法。
### 极市平台做了哪些
1. 统一定义算法接口:针对万千视频和图片分析算法,抽象出接口,定义在`include`目录下的`ji.h`文件中
2. 提供工具包:比如cjson库,wkt库,在`3rd`目录下
3. 应用层服务:此模块不在ev_sdk中,比如视频处理服务、算法对外通讯的http服务等
### 开发者需要做什么
1. 模型的训练和调优
2. 实现`ji.h`约定的接口
3. 实现约定的输入输出
4. 其他后面文档提到的功能
基础知识
1.mkdir -p /usr/local/ev_sdk/build 等Linux常用指令
# mkdir命令用来创建指定名称的目录,要求创建目录的用户在当前目录中具有写权限,并且指定的目录名不能是当前已有的目录
-m,--mode=模式,设定权限<模式>(类似chmod)。
-p,--parents 可以是一个路径名称。此时若路径中的某些目录尚不存在,加上此选项后,系统将自动建好那些尚不存在的目录,即一次可以建立多个目录。
-v,--verbose 每次创建目录都显示信息。
Linux中常用命令(更详细)_未名湖畔种千玺的博客-CSDN博客_linux常用命令
2..h 和 .cpp 文件详解
.h和.cpp差不多就像书和目录的关系吧,目录中对书中的章节和内容进行简单表示,真正的实现是在书里面的。
一般的数据,数据结构,接口,还有类的定义放在.h文件中,可以叫他们头文件,可以#include 到别的文件中。功能实现一般都放在具体的.cpp文件中,这样方便文件管理,节约时间,提高效率。
简单讲,一个Package就是由同名的.h和.cpp文件组成。当然可以少其中任意一个文件:只有.h文件的Package可以是接口或模板(template)的定义;只有.cpp文件的Package可以是一个程序的入口。
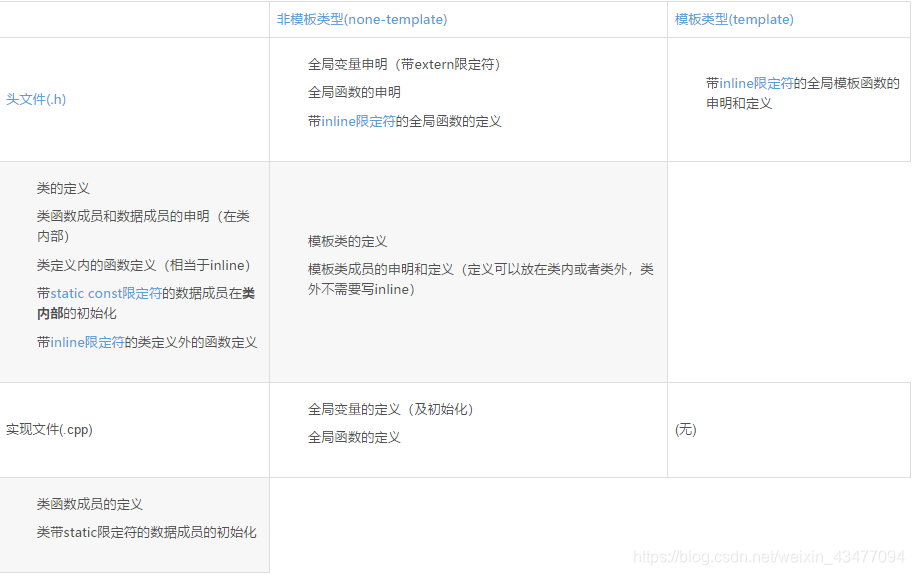
具体的.h和.cpp文件中应该些什么看下面的博文。
C++中头文件(.h)和源文件(.cpp)都应该写些什么_weixin_30740295的博客-CSDN博客
3.CMake的简单使用
CMake的简单使用_qzh_1234的博客-CSDN博客_使用cmake
一般会把源文件放到src目录下,把头文件放入到include文件下,生成的对象文件放入到build目录下,最终输出的elf文件会放到bin目录下,这样整个结构更加清晰。
实现一个简单程序的步骤就是
1.执行cmake . :生成了Makefile,还有一些cmake运行时自动生成的文件。
2.make :elf文件main也成功生成了。
3.运行./main :执行main.cpp中的函数实现。
如果想重新生成main,输入make clean就可以删除main这个elf文件。
4.C++中的<<和>>分别代表了左移和右移。
<< 和 >> 在 C++ 里面是什么意思_小菜鸡加油吧的博客-CSDN博客_c++中<<
5.Username for 'https://github.com':的验证问题
6.bash:command not found
7.std::string args;
std是一个类(输入输出标准),它包括了cin成员和cout成员,“using namespace std ;以后才能使用它的成员。std是命名空间,你所用到的很多函数或者类都是被放到命名空间里面的,命名空间是防止名字重复而使用的。
8.cv::Mat image;
Mat代表矩阵Mat(int rows, int cols, int type)rows代表行数,cols代表列数
type可以设置为 CV_8UC(n)、CV_8SC(n)、CV_16SC(n)、、CV_16UC(n)、CV_32FC(n)、*、CV_32SC(n)、CV_64FC(n)
其中8U、8S、16S、16U、32S、32F、64F前的数字代表Mat中每一个数值的位数
U代表uchar类型、S代表int类型、F代表浮点型(32F为float、64F为double)其他类似。
cv::mat表示申明一个矩阵
9.void *userData;
无类型指针
void关键字的使用规则:
1. 如果函数没有返回值,那么应声明为void类型;
2. 如果函数无参数,那么应声明其参数为void;
3. 如果函数的参数可以是任意类型指针,那么应声明其参数为void * ;
4. void不能代表一个真实的变量;
10.python封装(前面是C++封装过程的一些问题)
先在打榜项目的赛道说明中查看打榜项目关于SDK封装的说明,根据指示进行封装
Python接口
用户需要按照要求实现如下函数接口,发起测试时,系统会调用文件/project/ev_sdk/src/ji.py,并将测试图片逐次送入process_image接口,需要实现的程序接口:
import json
def init ():
"""Initialize model
Returns: model
"""
return {}
def process_image ( handle = None , input_image = None , args = None , ** kwargs ):
"""Do inference to analysis input_image and get output
Attributes:
handle: algorithm handle returned by init()
input_image (numpy.ndarray): image to be process, format: (h, w, c), BGR
Returns: process result
"""
# Process image here
fake_result = { }
fake_result [ "algorithm_data"] = {
"is_alert": false,
"target_count": 0,
"target_info": []
}
fake_result [ "model_data"] = {
"objects": [{
"x": 716,
"y": 716,
"width": 646,
"height": 233,
"confidence": 0.999660,
"name": "flame"
}]
}
return json . dumps ( fake_result , indent = 4 )以上是打榜项目给出的示例,以下是我的封装代码
import argparse
import os
import platform
import shutil
import time
from pathlib import Path
import sys
import json
sys.path.insert(1, '/project/ev_sdk/src/')
import cv2
import torch
import torch.backends.cudnn as cudnn
from numpy import random
import numpy as np
import argparse
import time
import cv2
import torch
import torch.backends.cudnn as cudnn
from numpy import random
from common import DetectMultiBackend
from utils.augmentations import letterbox
from models.experimental import attempt_load
from utils.dataloaders import LoadImages, LoadStreams
from utils.general import apply_classifier, check_img_size, check_imshow, check_requirements, check_suffix, colorstr, \
increment_path, non_max_suppression, print_args, scale_coords, set_logging, \
strip_optimizer, xyxy2xywh
from utils.plots import Annotator, colors
from utils.torch_utils import select_device, time_sync
####### 参数设置
conf_thres = 0.3
iou_thres = 0.2
prob_thres = 0.2
#######
imgsz = 480
weights = "/project/train/models/best_epoch50.pt"
device = '0'
stride = 32
names = ["smoke_white", "smoke_black", "flame"]
def init():
# Initialize
global imgsz, device, stride
set_logging()
device = select_device('0')
half = device.type != 'cpu' # half precision only supported on CUDA
# Load model
model = DetectMultiBackend(weights, device=device, dnn=False)
stride, pt, jit, engine = model.stride, model.pt, model.jit, model.engine
imgsz = check_img_size(imgsz, s=stride) # check img_size
model.half() # to FP16
model.eval()
model.warmup(imgsz=(1, 3, 480, 480), half=half) # warmup
return model
def process_image(model, input_image=None, args=None, **kwargs):
# Padded resize
img0 = input_image
img = letterbox(img0, new_shape=imgsz, stride=stride, auto=True)[0]
# Convert
img = img.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB
img = np.ascontiguousarray(img)
img = torch.from_numpy(img).to(device)
img = img.half()
# img = img.float()
img /= 255.0 # 0 - 255 to 0.0 - 1.0
if len(img.shape) == 3:
img = img[None]
pred = model(img, augment=False, val=True)[0]
# Apply NMS
pred = non_max_suppression(pred, conf_thres, iou_thres, agnostic=False)
fake_result = {}
fake_result["algorithm_data"] = {
"is_alert": False,
"target_count": 0,
"target_info": []
}
fake_result["model_data"] = {"objects": []}
# Process detections
cnt = 0
for i, det in enumerate(pred): # detections per image
gn = torch.tensor(img0.shape)[[1, 0, 1, 0]] # normalization gain whwh
if det is not None and len(det):
# Rescale boxes from img_size to im0 size
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], img0.shape).round()
for *xyxy, conf, cls in det:
if conf < prob_thres:
continue
cnt += 1
fake_result["model_data"]['objects'].append({
"xmin":int(xyxy[0]),
"ymin":int(xyxy[1]),
"xmax":int(xyxy[2]),
"ymax":int(xyxy[3]),
"confidence":float(conf),
"name":names[int(cls)]
})
fake_result["algorithm_data"]["target_info"].append({
"xmin":int(xyxy[0]),
"ymin":int(xyxy[1]),
"xmax":int(xyxy[2]),
"ymax":int(xyxy[3]),
"confidence":float(conf),
"name":names[int(cls)]
}
)
if cnt:
fake_result ["algorithm_data"]["is_alert"] = True
fake_result ["algorithm_data"]["target_count"] = cnt
return json.dumps(fake_result, indent = 4)
if __name__ == '__main__':
from glob import glob
# Test API
image_names = glob('/home/data/913/*.jpg')
predictor = init()
s = 0
for image_name in image_names:
# print('image_path:', os.path.join(image_dir, image_name))
img = cv2.imread(image_name)
t1 = time.time()
res = process_image(predictor, img)
print(res)
t2 = time.time()
s += t2 - t1
print(1/(s/100))完成以上封装后就可以进行测试了。















 2431
2431











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









