










在深度学习的分类问题中,真阳性、真阴性、假阳性和假阴性是评估模型性能的重要指标。它们的定义和计算如下:
-
真阳性(True Positive, TP):
- 定义:模型预测为正类(阳性),且实际标签也是正类。
- 解释:模型正确地识别出了正样本。
-
真阴性(True Negative, TN):
- 定义:模型预测为负类(阴性),且实际标签也是负类。
- 解释:模型正确地识别出了负样本。
-
假阳性(False Positive, FP):
- 定义:模型预测为正类,但实际标签是负类。
- 解释:模型错误地将负样本预测为正样本。
-
假阴性(False Negative, FN):
- 定义:模型预测为负类,但实际标签是正类。
- 解释:模型错误地将正样本预测为负样本。
这些指标可以通过混淆矩阵(Confusion Matrix)来直观表示。混淆矩阵如下所示:
| 预测为正类(阳性) | 预测为负类(阴性) | |
|---|---|---|
| 实际为正类(阳性) | 真阳性(TP) | 假阴性(FN) |
| 实际为负类(阴性) | 假阳性(FP) | 真阴性(TN) |
评估指标
基于真阳性、真阴性、假阳性和假阴性,可以计算出多个评估分类模型性能的指标:
-
准确率(Accuracy):
- 公式:
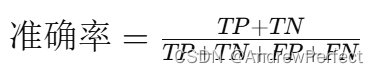
- 解释:模型预测正确的总体比例。
- 公式:
-
精确率(Precision):
- 公式:
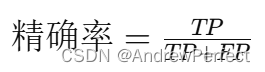
- 解释:模型预测为正类的样本中实际为正类的比例。(FP是假阳性,也就是预测为阳性)
- 公式:
-
召回率(Recall)或敏感性(Sensitivity):
- 公式:
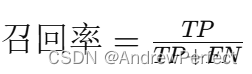
- 解释:实际为正类的样本中被正确预测为正类的比例。(FN是假阴性,实际就是阳性)
- 公式:
-
特异性(Specificity):
- 公式:
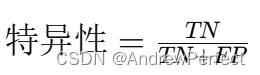
- 解释:实际为负类的样本中被正确预测为负类的比例。
- 公式:
-
F1 分数(F1 Score):
- 公式:

- 解释:精确率和召回率的调和平均。
- 公式:
实际应用中的考虑
在实际应用中,不同的应用场景对假阳性和假阴性的容忍度不同,因此需要根据具体需求选择合适的评价指标:
- 医疗诊断:假阴性通常更为严重,因为未能检测到疾病可能会导致严重后果。在这种情况下,召回率比精确率更重要。
- 垃圾邮件过滤:假阳性通常更为严重,因为误将正常邮件识别为垃圾邮件会影响用户体验。在这种情况下,精确率比召回率更重要。(这里要注意判断是不是被分类为垃圾邮件,所以是假阳性,本身不是垃圾邮件,却被识别成了垃圾邮件!!)
- 安全监控:在安全监控系统中,假阳性和假阴性都需要考虑,因为错误的报警(假阳性)和漏报(假阴性)都会带来问题。
如何减少假阳性和假阴性
- 改进模型:使用更复杂的模型(如深度学习模型)或结合多种模型(集成学习)以提高预测准确性。
- 优化阈值:调整分类阈值,以找到精确率和召回率之间的最佳平衡点。
- 数据增强:通过数据增强技术增加训练数据的多样性,提高模型的泛化能力。
- 特征选择和工程:选择和构建更具区分力的特征,以帮助模型更准确地分类。
通过理解假阳性和假阴性及其影响,可以更有效地评估和改进分类模型,提升实际应用中的性能和可靠性。

















 971
971

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









