







大语言模型(LLMs)在众多领域表现出色,却在决策场景中 “折戟”。本文深入剖析其背后原因,并探索强化学习微调(RLFT)这一 “秘密武器” 能否助力 LLMs 逆袭。想知道研究成果如何吗?快来一探究竟!
论文标题 LLMs are Greedy Agents: Effects of RL Fine-tuning on Decision-Making Abilities
来源 arXiv:2504.16078 [cs.LG] + https://arxiv.org/abs/2504.16078
文章核心
研究背景
大语言模型(LLMs)在文本生成、语言理解等多领域成果斐然,基于其 “世界知识” 和思维链(CoT)推理能力,人们期望其在决策问题中发挥关键作用,但实际应用中却不尽人意。
研究问题
- LLMs 在决策时存在贪婪性,过度青睐当前表现最佳的行动,导致行动覆盖范围停滞,大量行动空间未被探索,影响决策效果。
- 存在频率偏差,倾向于重复选择上下文中出现频率最高的行动,即便该行动奖励低,这是监督预训练带来的问题。
- 存在知行差距,模型虽知晓任务解决方法,但行动时却难以有效运用知识,优先选择贪婪行动而非最优行动。
主要贡献
- 系统分析失败模式:首次系统研究小到中等规模 LLMs 在决策场景中的三种常见失败模式 —— 贪婪性、频率偏差和知行差距,量化分析其在不同规模模型中的表现,为后续改进提供方向。
- 验证 RLFT 有效性:提出基于自我生成 CoT 推理的强化学习微调(RLFT)方法,实验证明其能有效缓解 LLMs 的上述缺陷,提升决策能力,如在多臂老虎机(MAB)实验中降低累积遗憾值、增加行动覆盖范围。
- 评估多种探索机制:全面评估经典探索机制(如 ϵ -greedy)和 LLM 特定方法(如自我一致性)对 LLMs 探索能力的影响,发现 “尝试所有行动(try-all)” 策略和探索奖励机制能显著提升性能,为优化 LLMs 决策提供更多策略选择。
- 关键因素重要性研究:通过消融实验,明确 CoT 推理、专家数据以及 “思考时间”(生成令牌预算)在 LLMs 决策中的重要作用,为进一步优化模型提供理论依据。
方法论精要
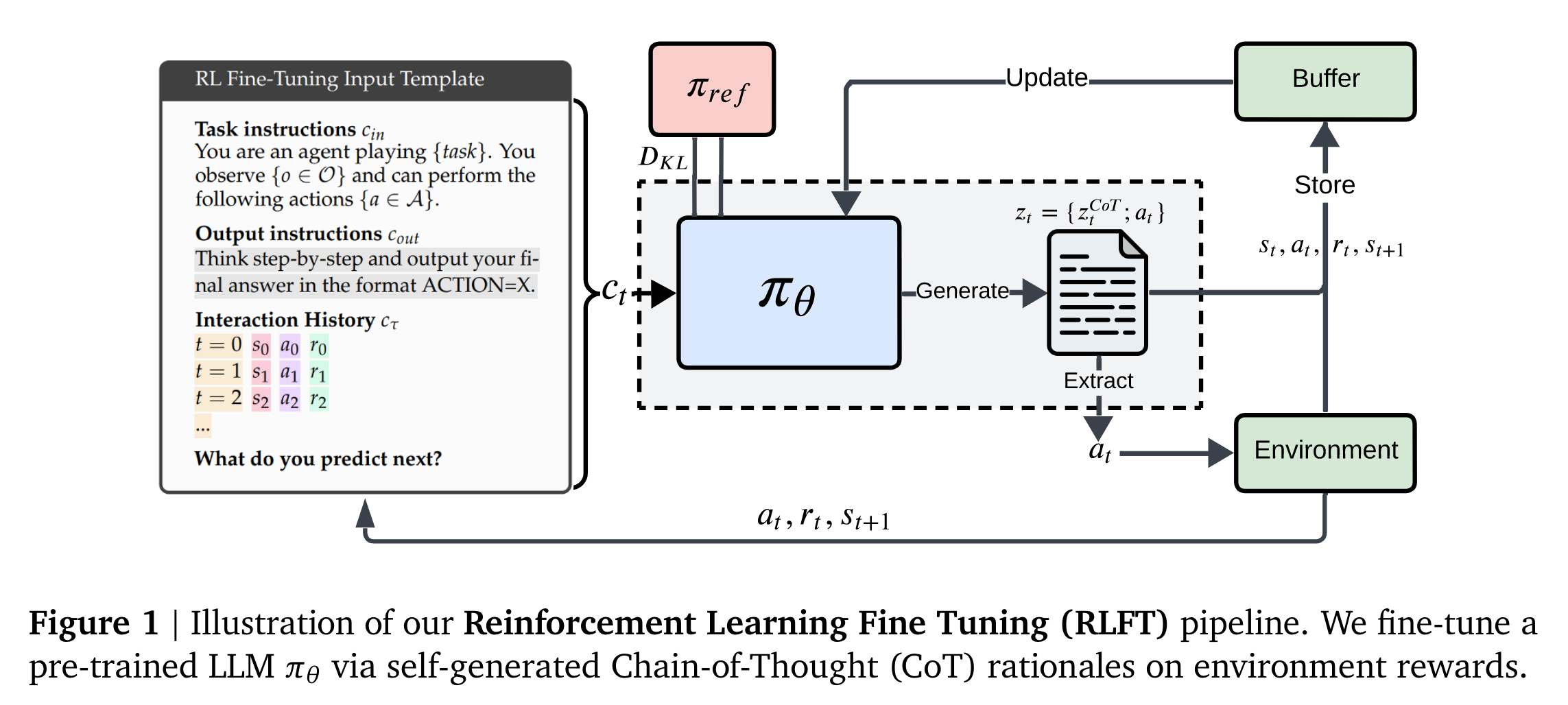
1. 核心算法/框架:采用强化学习微调(RLFT)框架,基于环境奖励对预训练的LLMs进行微调,让模型在自我生成的CoT推理基础上,学习能带来更高奖励的行动策略。在这个框架中,模型通过不断与环境交互,根据环境反馈的奖励信号,对自身的决策策略进行优化。
2. 关键参数设计原理:
- Context Representation:输入上下文包含输入指令、输出指令和最近交互历史,为模型提供决策信息。输入指令就像是老师给学生布置作业时的要求,告诉模型需要做什么;输出指令则规定了模型输出结果的格式;最近交互历史记录了模型之前与环境交互的情况,让模型可以参考过去的经验来做出当前的决策,就如同人在做决策时会回忆之前类似场景下的经历一样。
- Factorization of Action Tokens:行动令牌分解为CoT推理令牌和执行行动,通过正则表达式提取执行行动。这就像是把一个复杂的任务拆分成思考过程(CoT推理令牌)和实际执行步骤(执行行动),然后利用正则表达式这种文本匹配工具,从模型生成的内容中准确找到要执行的行动,保证模型的决策能够被正确执行。
- Reward Shaping for Valid Actions:设置奖励塑形项,对无效行动进行惩罚(如 -5的奖励惩罚),并进行奖励归一化,确保优化过程不受过度偏差影响。这类似于游戏中的奖惩机制,当模型做出无效行动时,就给予一定的惩罚,让模型知道这种行为不好;而奖励归一化则是为了避免某些奖励值过大或过小对模型学习产生不合理的影响,保证模型能够公平地评估不同行动的价值。
- Fine-tuning objective:采用带KL约束的剪裁目标进行微调,根据环境特点选择蒙特卡罗基线或状态值头估计优势值。带KL约束的剪裁目标可以限制模型更新的幅度,防止模型在训练过程中过度偏离原来的策略,就像给模型的学习加上了一个“安全绳”;而根据环境特点选择不同的优势估计方法,是为了更准确地评估模型行动的价值,在固定episode长度的环境(如多臂老虎机)中使用蒙特卡罗基线,在可变episode长度的环境(如井字棋)中学习一个单独的状态值头并使用广义优势估计,从而使模型能够更好地适应不同的环境。

3. 创新性技术组合:
- CoT推理与RLFT结合:将自我生成的CoT推理与RLFT相结合,使模型能利用推理过程优化决策。传统的决策模型可能只是简单地根据经验或固定规则做出决策,而该研究让模型自己生成推理过程,再结合强化学习的反馈机制,就像一个人不仅有自己的思考能力,还能根据实践结果不断改进自己的想法,大大提高了决策的合理性和有效性。
- 多种技术辅助训练:在训练过程中,结合多种技术,如为模型提供任务特定指令、采用灵活的输出模板等,提高模型决策灵活性和适应性。采用灵活的输出模板则避免了模型受到固定格式的限制,能够更自由地表达自己的决策。这些技术相互配合,使模型在面对不同的决策场景时能够更加灵活地应对。
4. 实验验证方式:在多臂老虎机(MAB)、上下文老虎机(CB)和井字棋(Tic-tac-toe)等环境中进行实验。选择这些环境是因为它们代表了不同类型的决策场景。MAB实验基于BanditBench中Nie等人(2024)发布的场景,设置不同数量的臂(5、10、20)、奖励分布(高斯或伯努利)和随机水平(低/中/高),可以测试模型在不同复杂度和不确定性下的决策能力;CB实验利用基于MovieLens数据集的半合成环境,考察模型在利用上下文信息进行决策的能力;井字棋实验使用Ruoss等人(2024)发布的文本版本环境,检验模型在具有状态转移的复杂环境中的决策表现。对比基线包括Upper-confidence Bound(UCB)、随机代理、LinUCB等,通过对比评估模型性能。UCB被认为是最优策略,代表了模型性能的上限;随机代理则是随机选择行动,代表了最差的情况;LinUCB适用于上下文老虎机场景。与这些基线对比,能够清晰地看出RLFT方法的优势和不足,为进一步改进模型提供依据 。

实验洞察
- 性能优势:在 MAB 实验中,RLFT 显著降低了 Gemma2 2B 和 9B 模型的累积遗憾值(与随机基线相比),如在中等噪声$ \sigma = 1.0 $、20 臂的高斯 MAB 按钮场景中,RLFT 后的 Gemma2 2B 模型累积遗憾值大幅下降,缩小了与更大模型及 UCB 的差距;在井字棋实验中,RLFT 使 Gemma2 2B 模型胜率显著提升,对抗随机代理时平均回报率从 0.15 提升至 0.75,甚至能与最优的蒙特卡罗树搜索(MCTS)基线打成平手。
- 消融研究:去除 CoT 后,RLFT 在 10 臂高斯 MAB 实验中的性能几乎无法达到有 CoT 时的上下文学习(ICL)性能,证明 CoT 对决策至关重要;构建包含或不包含 CoT 的 UCB 专家数据集进行监督微调(SFT)实验,发现两种 SFT 变体都能成功模仿专家,达到与 UCB 专家相近的遗憾值,验证了专家数据在决策中的有效性;增加模型生成行动时的 “思考时间”(即增加生成令牌预算 G)能提升性能,如将 G 从 256 增加到 512,模型性能可提升至 Gemma2 9B + RLFT 的水平,但会增加训练时间和计算成本。
本文由 AI 辅助完成。


















 691
691

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









