




14.6倍效率提升!AWorld框架如何破解智能体训练的数据生成瓶颈?
本文将深入解析开源框架AWorld——一款专为智能体(Agentic AI)“从实践中学习”设计的基础设施。它通过分布式架构突破经验生成效率瓶颈,使基于Qwen3-32B的智能体在GAIA基准测试中pass@1准确率达32.23%,超越GPT-4o(27.91%),为复杂任务下智能体的规模化训练提供了可落地的完整方案。
论文标题: AWorld: Orchestrating the Training Recipe for Agentic AI
来源: arXiv:2508.20404 [cs.AI],链接:http://arxiv.org/abs/2508.20404
PS: 整理了LLM、量化投资、机器学习方向的学习资料,关注同名公众号 「 亚里随笔」 即刻免费解锁
文章核心
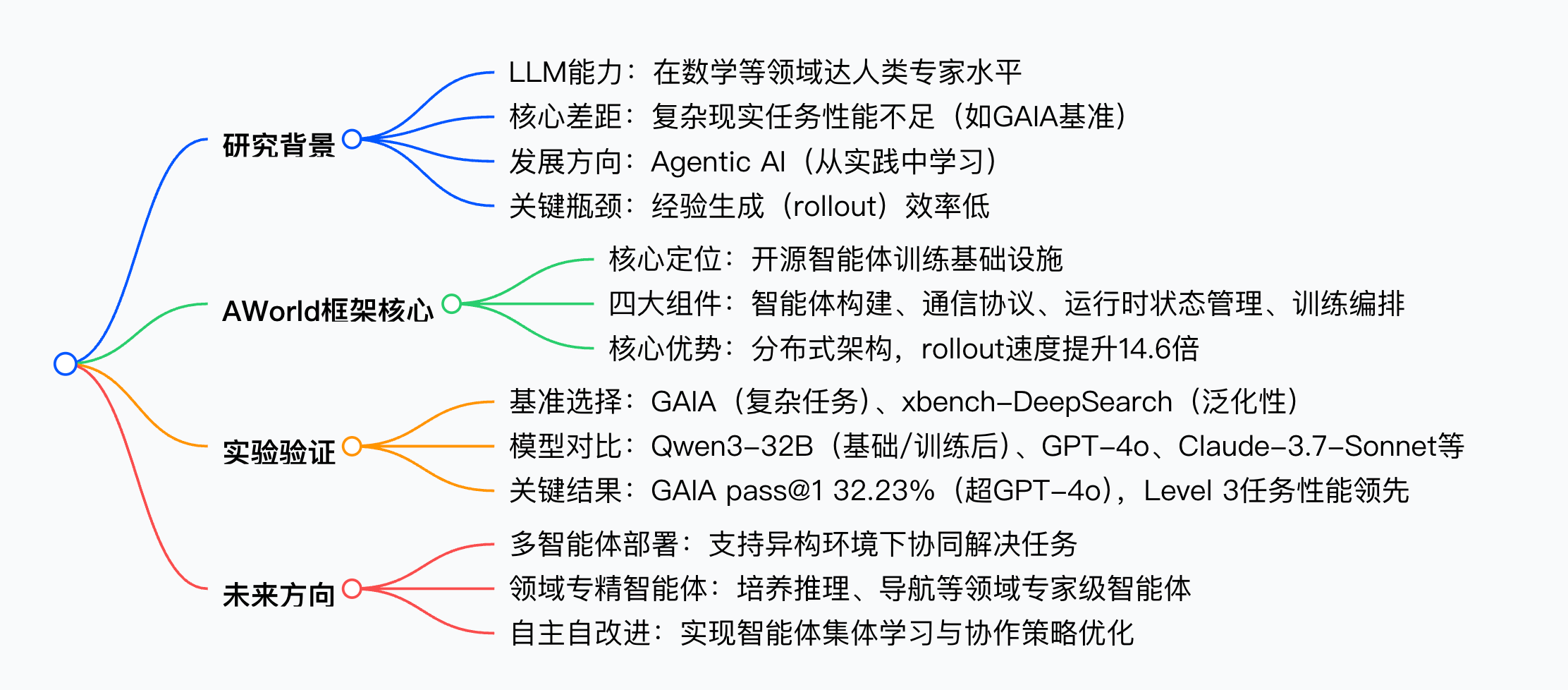
研究背景
自ChatGPT发布以来,大型语言模型(LLMs)在数学、推理等领域展现出接近人类专家的能力,但现有AI系统在解决现实世界复杂任务时仍存在显著差距。例如,在挑战性基准GAIA上,即使是GPT-4这类闭源模型,pass@1准确率也仅为3.99%。
未来AI的发展方向是智能体(Agentic AI),其核心是“从实践中学习”——通过与环境的多轮交互、长轨迹决策解决复杂任务。该范式的训练需依赖三大核心要素:算法(学习机制)、环境(交互场景)、先验(LLM基础能力)。然而,当前面临数据稀缺(如GAIA验证集仅165题)、交互环境部署难、智能体-环境交互效率低等问题,其中经验生成(rollout)效率低下已成为制约智能体性能提升的核心瓶颈。
研究问题
- 数据稀缺与样本效率矛盾:高质量复杂任务数据难以获取(如GAIA数据集规模小),但现有算法需大量经验才能实现性能提升,样本效率不足。
- 交互环境 scalability 差:虽已出现浏览器导航、计算机控制等交互环境,但这些环境部署复杂、可扩展性低,难以支撑规模化训练。
- 经验生成效率低下:智能体与环境交互需消耗大量时间(如GAIA单条rollout耗时可达20分钟),单节点串行执行无法满足规模化训练需求,成为“从实践中学习”的核心瓶颈。
主要贡献
- 设计并实现AWorld框架:一款模块化、可扩展的开源基础设施,覆盖智能体构建、通信、分布式执行、训练编排全流程,支持“从实践中学习”的完整生命周期,解决复杂长周期任务的训练需求。
- 实证验证经验生成的瓶颈作用:在GAIA基准上证明,智能体性能与rollout数量正相关,但单节点串行执行效率极低;AWorld的分布式架构将rollout速度提升14.6倍,使规模化训练成为可能。
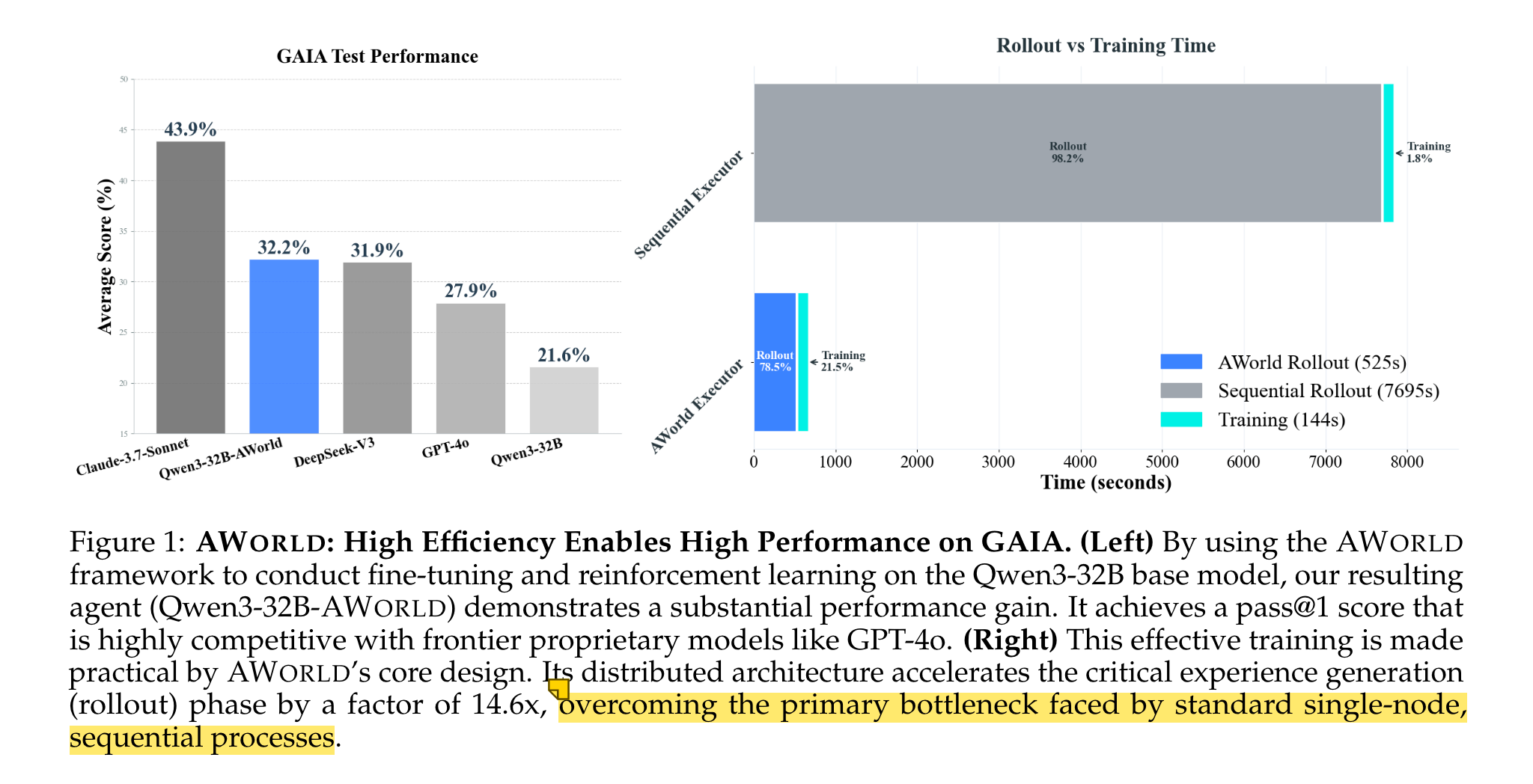
- 训练高性能开源智能体:基于AWorld训练的Qwen3-32B智能体,在GAIA测试集上pass@1准确率达32.23%,不仅显著超越基础模型(21.59%),还超越GPT-4o(27.91%),在GAIA最高难度Level 3任务上甚至优于Claude-3.7-Sonnet等闭源模型。
思维导图
方法论精要
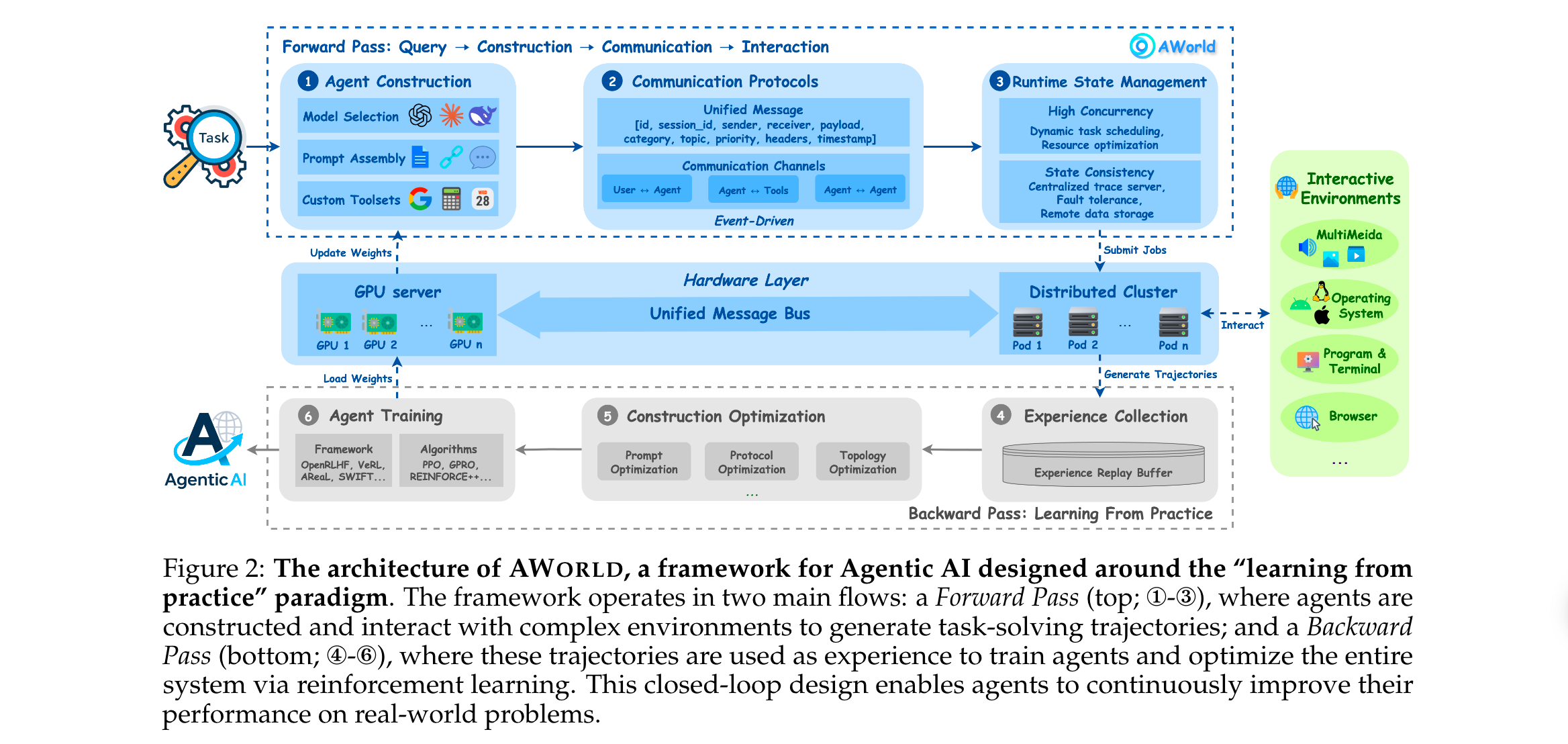
AWorld框架围绕“从实践中学习”设计,分为前向流程(智能体与环境交互生成经验) 和后向流程(利用经验训练优化智能体) 两大模块,核心包含四大组件:
1. 智能体构建(Agent Construction)
提供灵活的智能体实例化能力,支持单智能体与多智能体场景,核心功能包括:
- Prompt组装:用户可定义系统Prompt,引导智能体行为适配特定场景(如数学推理、浏览器导航)。
- 自定义工具集:支持为智能体配置多样化工具,涵盖代码执行、终端操作、数据处理等,具体工具及功能如下表:

- 智能体拓扑配置:支持多智能体系统的自动化或自定义拓扑设计,实现动态团队组建与协作策略(如任务 delegation、结果同步)。
2. 通信协议(Communication Protocols)
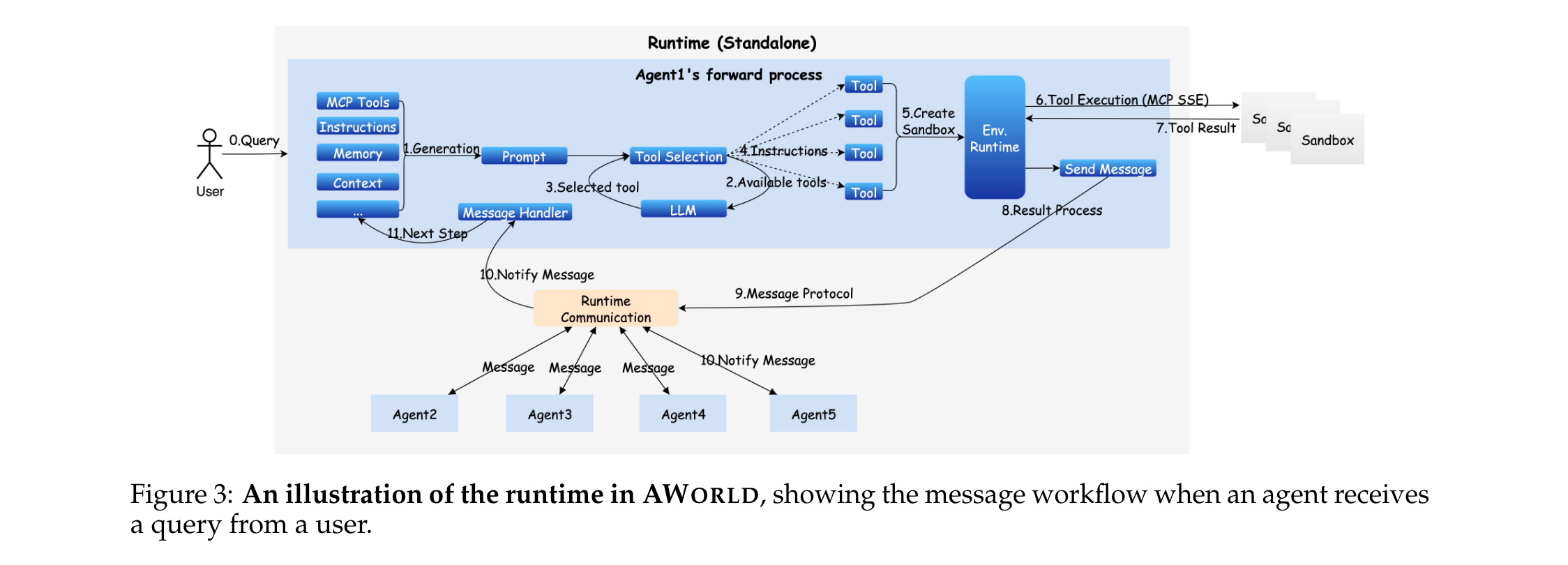
以Message对象为核心抽象,统一三类通信通道(用户-智能体、智能体-工具、智能体-智能体),确保交互的可靠性与一致性:
- Message对象结构:包含10个核心属性,覆盖身份标识、内容载体、路由控制等维度:
| 属性名 | 类型 | 描述 |
|---|---|---|
| id | str | 唯一消息标识(UUID) |
| session id | str | 任务/会话上下文标识 |
| sender | str | 发送方(智能体/工具) |
| receiver | Optional[str] | 接收方(可选,支持广播) |
| caller | Optional[str] | 调用链中的父发送方(用于嵌套调用) |
| payload | Any | 核心内容载体,支持ActionModel(动作)、Observation(观测)、TaskItem(任务) |
| category | str | 事件类型或消息类别(如“action_exec”“result_return”) |
| topic | Optional[str] | 基于主题的路由通道(支持发布-订阅模式) |
| priority | int | 发送方指定的执行优先级 |
| headers | Dict[str, Any] | 附加元数据(如任务ID、跟踪信息) |
| timestamp | float | 消息创建的时间戳( epoch 格式) |
- 鲁棒性保障:内置参数验证、错误处理、结果解析机制(如调用失效智能体时自动生成错误通知),提升分布式执行的稳定性。
3. 运行时状态管理(Runtime State Management)
基于Kubernetes实现分布式架构,核心解决高并发与状态一致性问题,支撑长周期任务交互:
- 高并发执行:通过Kubernetes动态任务管理模块,实现大规模任务的调度、分发与优先级排序,将任务分配到分布式集群的工作节点,最大化资源利用率,加速rollout样本生成。
- 状态一致性:通过同步远程数据存储与中心化跟踪服务器(trace server),确保分布式节点间的状态统一,支持任务中断后的快速恢复;同时系统会自动收集智能体轨迹(trajectories)与指标(metrics),为后续训练与评估提供数据支持。
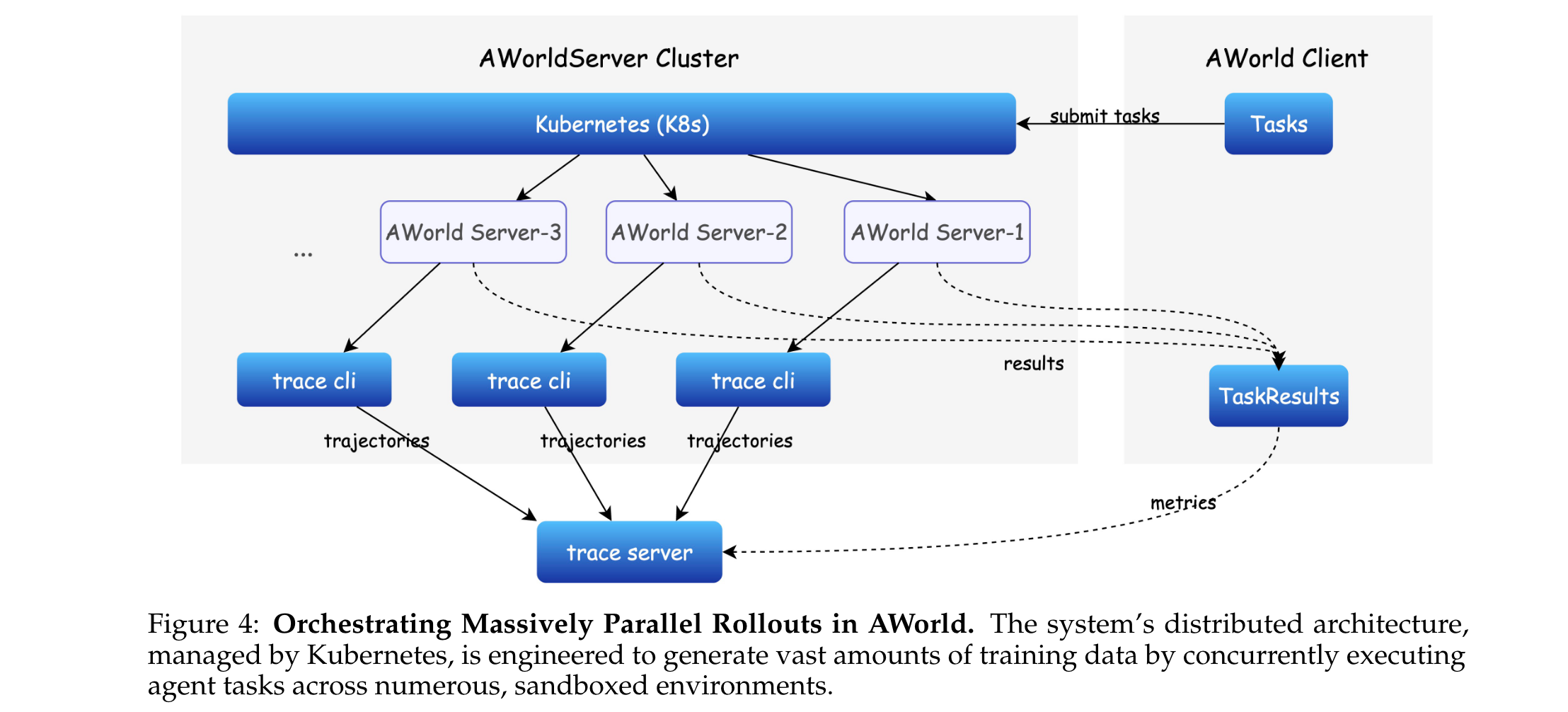
4. 训练编排(Training Orchestration)
采用“训练-推理解耦”架构,与外部强化学习(RL)框架无缝集成,解决经验生成与模型训练的衔接问题:
- 核心逻辑:替换传统RL框架中的rollout模块为AWorld Executor,形成“交互-反馈-更新”闭环:
- Rollout阶段:任务提交至AWorld Executor,Executor与RL框架的推理引擎交互,每一步查询动作并在环境中执行,收集反馈形成完整轨迹。
- 训练阶段:轨迹数据传入RL框架(如SWIFT、OpenRLHF),通过GRPO等算法计算梯度更新,更新后的模型参数同步至推理引擎。
- 兼容性:支持多种主流RL框架,包括OpenRLHF(Hu et al., 2024)、VeRL(Sheng et al., 2025)、AReaL(Fu et al., 2025)、SWIFT(Zhao et al., 2025),无需修改框架核心代码即可接入。
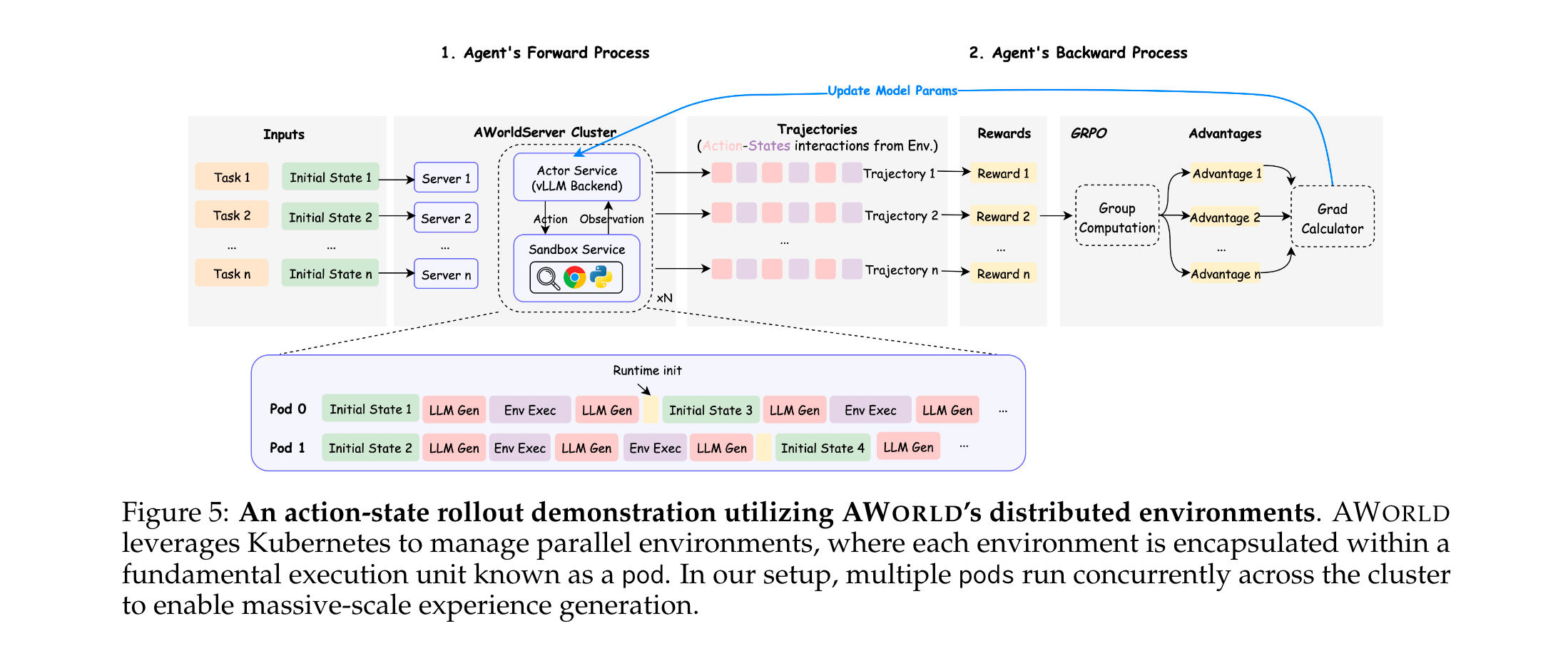
实验洞察
实验围绕“验证AWorld的效率优势”与“训练高性能智能体”两大目标展开,设计了基准分析、效率对比、性能验证三类实验,细节如下:
实验设置
(1)基准选择
- GAIA(Mialon et al., 2023):智能体评估核心基准,模拟现实世界复杂任务,特点是“大搜索空间”(工具与参数组合多、观测空间噪声大、需长轨迹推理)与“低搜索效率”(智能体易出现规划不足、动作冗余),适合验证智能体的复杂任务解决能力。
- xbench-DeepSearch(Chen et al., 2025):辅助基准,用于验证智能体的泛化能力(无直接训练数据)。
(2)模型与基础设施
- 基础模型:Qwen3-32B(Yang et al., 2025),开源大模型,作为训练起点。
- 对比模型:闭源模型(GPT-4o(Hurst et al., 2024)、Claude-3.7-Sonnet(Anthropic, 2025))、开源模型(DeepSeek-V3(Liu et al., 2024))。
- 硬件架构:训练-推理解耦,具体配置如下:
| 节点类型 | 硬件配置 | 功能 |
|---|---|---|
| 训练节点 | 8×NVIDIA A100(80GB)、96核CPU、1200GB内存 | 模型训练,支持DeepSpeed ZeRO3 |
| 推理节点 | 8×NVIDIA A100(80GB)、96核CPU、800GB内存 | 环境交互与rollout生成 |
- 工具链:rollout阶段用vLLM(Kwon et al., 2023)管理高吞吐量推理;训练阶段用SWIFT(Zhao et al., 2025)编排微调与RL更新。
关键实验与结果
(1)实验1:Rollout规模对性能的影响(验证瓶颈必要性)
- 实验设计:在GAIA验证集(165题)上,评估Claude-3.7-Sonnet、Gemini 2.5 Pro、GPT-4o三款模型,设置rollout数量从1到32,统计pass@k准确率。
- 核心发现:
- 所有模型的性能随rollout数量增加显著提升,且趋势一致:前10-15次rollout提升最明显,之后逐渐趋于平稳(接近模型性能上限)。
- 具体提升幅度:Claude-3.7-Sonnet从47.9%(pass@1)提升至76.4%(pass@32),提升28.5个百分点;GPT-4o从27.3%提升至65.5%,提升38.2个百分点。
- 结论:足够的rollout数量是智能体学习成功案例的前提,而rollout效率直接决定训练可行性,验证了瓶颈的重要性。
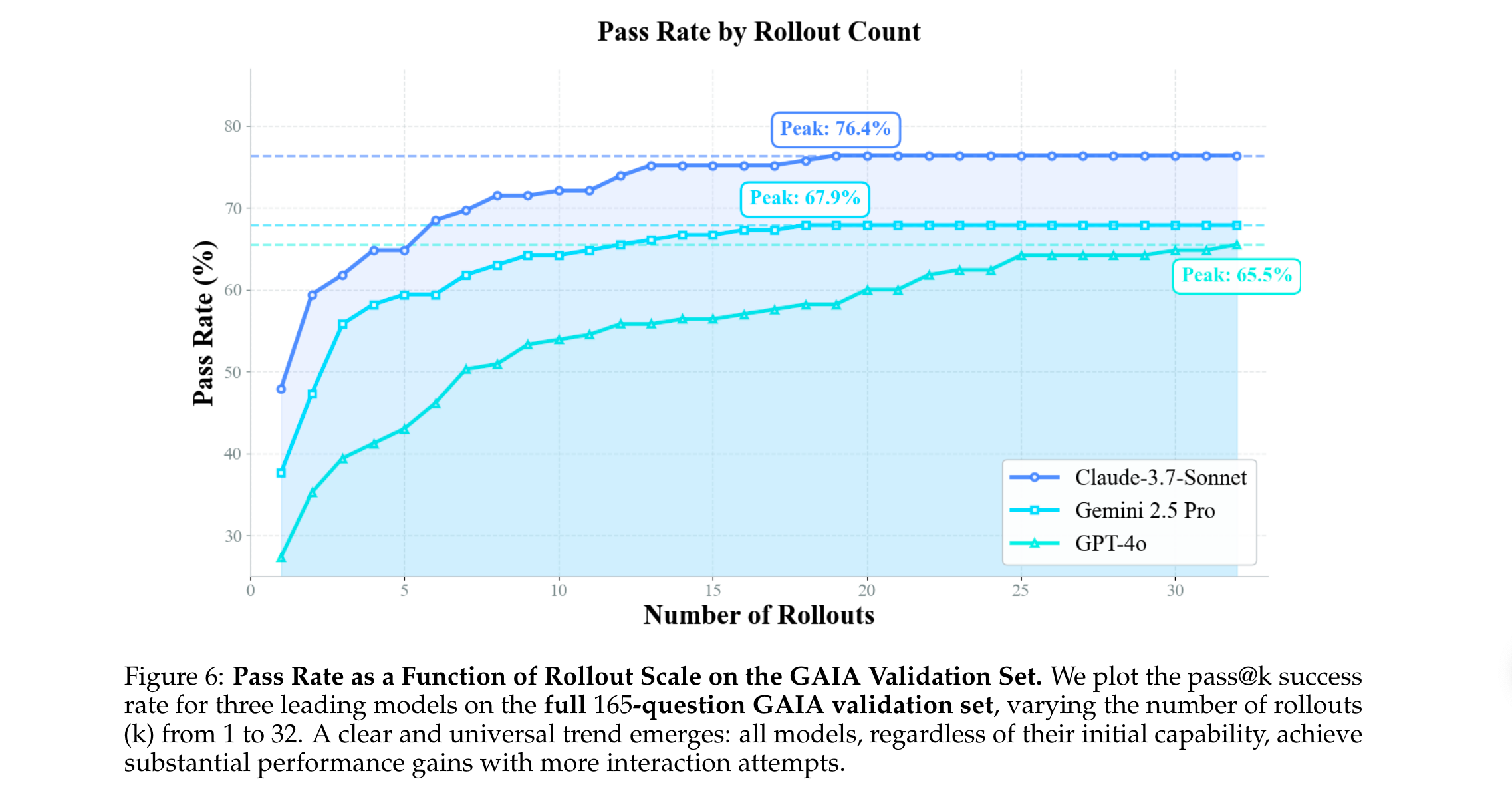
(2)实验2:AWorld分布式Rollout效率对比(验证框架效率)
- 实验设计:对比AWorld分布式执行(多节点并发)与单节点串行执行的“rollout+训练”全周期时间,其中训练时间为固定值(144s),rollout任务为GAIA标准任务。
- 核心结果:

- 关键说明:单节点无法实现有效并行——复杂环境(如浏览器引擎)对CPU/内存需求高,多rollout并发会导致资源竞争与进程崩溃,因此串行执行是单节点的唯一稳定方案,对比公平。
- 结论:AWorld将rollout效率提升14.6倍,使“大规模rollout生成”从“不可行”变为“可行”,彻底破解经验生成瓶颈。
(3)实验3:基于AWorld的智能体训练与性能(验证框架实用性)
- 训练流程:
- SFT预训练:用Claude 3.7 Sonnet生成的886条成功轨迹,对Qwen3-32B进行有监督微调,缓解冷启动问题,得到SFT模型。
- RL训练:基于AWorld执行3阶段循环:
- Rollout:每个任务设置32次rollout,AWorld Executor与vLLM交互生成轨迹,模型权重每步更新。
- 奖励计算:规则化奖励——答案与真值完全匹配得1分,否则得0分。
- 梯度更新:采用GRPO算法(Shao et al., 2024)计算优势估计与梯度,通过SWIFT框架执行更新,同步至vLLM服务器。
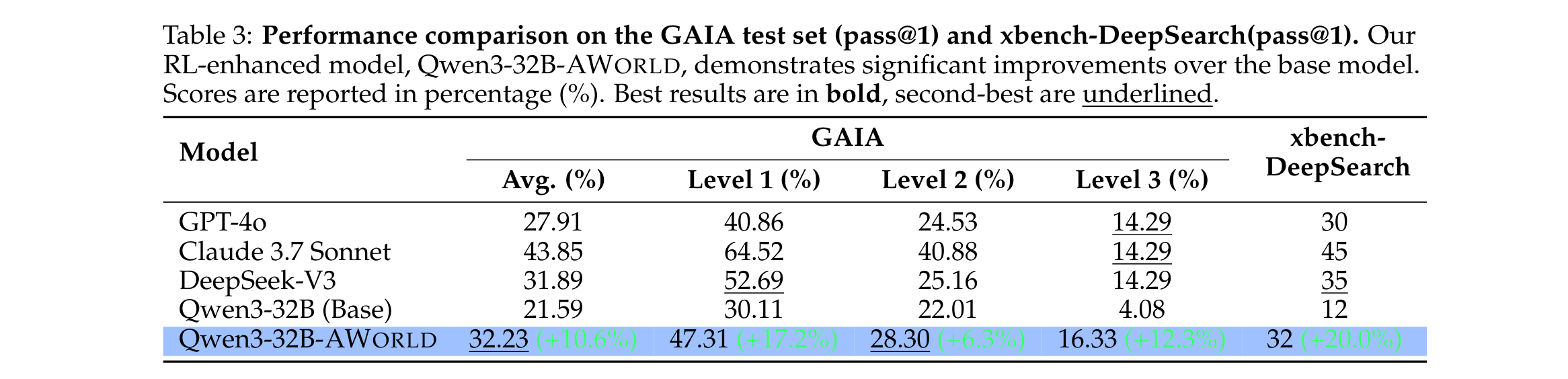
- 核心结果:
- 相对于基础模型的提升:
- GAIA测试集:Qwen3-32B-AWorld(训练后)pass@1准确率达32.23%,较基础模型(21.59%)提升10.6个百分点,且所有难度等级(Level 1-3)均有显著提升。
- 泛化能力:xbench-DeepSearch上pass@1准确率从12%提升至32%(提升20个百分点),证明未过拟合,习得通用问题解决能力。
- 与主流模型的对比:
- GAIA整体性能:Qwen3-32B-AWorld(32.23%)超越GPT-4o(27.91%),与开源模型DeepSeek-V3(31.89%)持平。
- 高难度任务优势:在GAIA Level 3任务(最复杂)上,pass@1准确率达16.33%,超越所有对比模型(包括Claude-3.7-Sonnet、GPT-4o),证明其复杂推理能力突出。
- 相对于基础模型的提升:
关键实验结论
- 效率是核心:经验生成(rollout)是智能体训练的核心瓶颈,AWorld的分布式架构可14.6倍提升效率,为规模化训练提供基础。
- “从实践中学习”有效:基于AWorld的RL训练能让Qwen3-32B显著突破基础能力上限,在复杂任务上超越多个闭源模型,验证了该范式的可行性。
- 泛化能力可靠:训练后的智能体在无训练数据的xbench-DeepSearch上表现优异,证明AWorld支持的训练流程能让智能体习得通用技能,而非仅适配单一基准。



















 125
125

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









