







一、问题背景
# ---------cat vs dog-------------
# https://michael.blog.csdn.net/
import tensorflow as tf
import pandas as pd
import numpy as np
import random
import os
num_epochs = 10
batch_size = 32
learning_rate = 1e-4
train_data_dir = "./dogs-vs-cats/train/"
test_data_dir = "./dogs-vs-cats/test/"
# 数据处理
def _decode_and_resize(filename, label=None):
img_string = tf.io.read_file(filename)
img_decoded = tf.image.decode_jpeg(img_string)
img_resized = tf.image.resize(img_decoded, [256, 256]) / 255.
if label == None:
return img_resized
return img_resized, label
# 使用 tf.data.Dataset 生成数据
def processData(train_filenames, train_labels):
train_dataset = tf.data.Dataset.from_tensor_slices((train_filenames, train_labels))
train_dataset = train_dataset.map(map_func=_decode_and_resize)
# train_dataset = train_dataset.shuffle(buffer_size=25000) # 非常耗内存,不使用
train_dataset = train_dataset.batch(batch_size)
train_dataset = train_dataset.prefetch(buffer_size=tf.data.experimental.AUTOTUNE)
return train_dataset
if __name__ == "__main__":
# 训练文件路径
file_dir = [train_data_dir + filename for filename in os.listdir(train_data_dir)]
labels = [0 if filename[0] == 'c' else 1
for filename in os.listdir(train_data_dir)]
# 打包并打乱
f_l = list(zip(file_dir, labels))
random.shuffle(f_l)
file_dir, labels = zip(*f_l)
# 切分训练集,验证集
valid_ratio = 0.1
idx = int((1 - valid_ratio) * len(file_dir))
train_files, valid_files = file_dir[:idx], file_dir[idx:]
train_labels, valid_labels = labels[:idx], labels[idx:]
# 使用 tf.data.Dataset 生成数据集
train_filenames, valid_filenames = tf.constant(train_files), tf.constant(valid_files)
train_labels, valid_labels = tf.constant(train_labels), tf.constant(valid_labels)
train_dataset = processData(train_filenames, train_labels)
valid_dataset = processData(valid_filenames, valid_labels)
# 建模
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(32, 3, activation='relu', input_shape=(256, 256, 3)),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Conv2D(64, 5, activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Conv2D(128, 5, activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(2, activation='softmax')
])
# 模型配置
model.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=learning_rate),
loss=tf.keras.losses.sparse_categorical_crossentropy,
metrics=[tf.keras.metrics.sparse_categorical_accuracy]
)
# 训练
model.fit(train_dataset, epochs=num_epochs, validation_data=valid_dataset)
# 测试 test
test_filenames = tf.constant([test_data_dir + filename for filename in os.listdir(test_data_dir)])
test_data = tf.data.Dataset.from_tensor_slices(test_filenames)
test_data = test_data.map(map_func=_decode_and_resize)
test_data = test_data.batch(batch_size)
ans = model.predict(test_data) # ans [12500, 2]
prob = ans[:, 1] # dog 的概率
# 写入提交文件
id = list(range(1, 12501))
output = pd.DataFrame({'id': id, 'label': prob})
output.to_csv("submission.csv", index=False)上面的这个代码块,是我在学CNN做图像分类过程中看到的,详见文章 。
其中的打包并打乱这一步的操作,属实把我看懵了,原来还有zip(*data)这种用法。
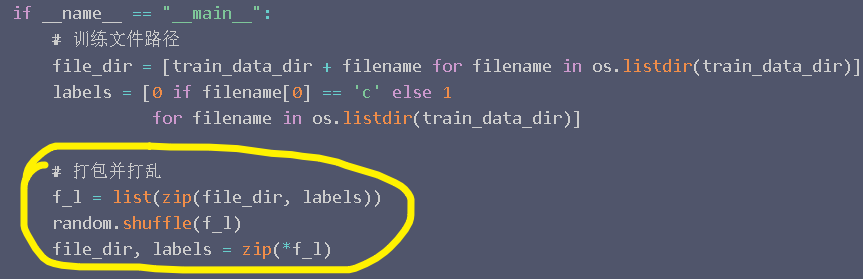
这个*解包搭配zip函数的应用,其实是非常巧妙的;因为首先shuffle函数只允许接收一个数据参数,而如果分别对file_dir和labels进行打乱,那么它们之间的对应关系就被破坏了。
(虽然,这个问题可以通过设置随机数种子来解决——seed,但是random模块的shuffle和numpy.random子模块下的shuffle,都不支持随机数种子,因此乱序的效果是无法复现的;现阶段只能用zip压缩成包的形式来打乱,然后再*搭配zip解包,也是可以的,只不过有点麻烦而已)
然后,我用下面的代码做了一个实验,想探究一下zip搭配*使用的效果。
languages = ['Java', 'Python', 'JavaScript']
versions = [14, 3, 6]
result = zip(languages, versions)
print(list(result))
print(list(zip(*result)))
# [('Java', 14), ('Python', 3), ('JavaScript', 6)]
# []但是,第二个输出竟然是一个空列表,我真的懵逼了。
二、问题的解决
查了官方文档对zip的描述,我发现这个函数是可接受变长度参数的,所以搭配*解包某一个列表/元组使用,完全合理。
那为什么我的结果输出这么奇怪呢?竟然是空列表。
我去网上搜索了一下,*解包能对所有可迭代对象进行。
下面这篇文章有稍微的介绍:Python - 解包的各种骚操作-51CTO博客
from collections.abc import Iterable
languages = ['Java', 'Python', 'JavaScript']
versions = [14, 3, 6]
result = zip(languages, versions)
print(isinstance(result, Iterable))
print(*result)
print(list(zip(*result)))
print(*range(9))上面的代码输出如下。可以看到单独解包zip对象然后输出是没有问题的,但是解包后再传入参数zip()就出了差错。
True
('Java', 14) ('Python', 3) ('JavaScript', 6)
[]
0 1 2 3 4 5 6 7 8我盘起代码观摩数遍,终于发现病因!
原来是result变量本身没有转换成一个列表或元组。
我讶异的是,这样使用*解包,竟然没有出现语法错误(强烈建议python官方在这方面强化语法纠察机制)。
改正的代码如下:
languages = ['Java', 'Python', 'JavaScript']
versions = [14, 3, 6]
result = list(zip(languages, versions))
print(list(result))
print(list(zip(*result)))
# [('Java', 14), ('Python', 3), ('JavaScript', 6)]
# [('Java', 'Python', 'JavaScript'), (14, 3, 6)]三、不堪回首
如下面的代码块所示,我以为本文第一部分中“老师”的代码有问题的时候(因为后面这个函数调用返回的结果不是一个列表嘛,怎么能用两个变量去接盘?)

我做了下面这个实验,竟然没出问题!
languages = ['Java', 'Python', 'JavaScript']
versions = [14, 3, 6]
result = list(zip(languages, versions))
print(list(result))
a, b = list(zip(*result))
c = list(zip(*result))
print(a)
print(b)
print(c)
# [('Java', 14), ('Python', 3), ('JavaScript', 6)]
# ('Java', 'Python', 'JavaScript')
# (14, 3, 6)
# [('Java', 'Python', 'JavaScript'), (14, 3, 6)]好吧,我又学到了一个知识点,原来列表(或元组)是可以赋给多个变量的,这时候列表(或元组)的长度必须要等于等号左边的变量数。















 2426
2426











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









