






论文:https://arxiv.org/abs/1611.09326
代码:https://github.com/SimJeg/FC-DenseNet
摘要
典型的分割体系结构由下列部分组成:
(a)负责提取粗略语义特征的下采样路径;
(b)训练上采样路径以将模型输出的分辨率恢复至输入图像分辨率大小;
(c)处理模块(例如,条件随机场)来优化模型预测。(可选)
本文扩展DenseNet为全卷积网络来处理语义分割问题。在CamVid和Gatech等城市场景数据集上获得了最先进的成果,而无需任何进一步的后处理模块或预训练。
1 引言
DenseNet由密集块和池化操作构建而成,其中每个密集块是之前特征图的迭代级联。DenseNet有以下特点:
(1)参数效率,DenseNets在参数使用中更有效率;
(2)隐式的深度监督,DenseNets通过在体系结构中的所有特征图的短路径进行深度监督;
(3)特征重用,所有图层都可以很容易地访问它们之前的图层,从而可以轻松地重复使用之前计算的特征图中的信息。
DenseNets的这些特点使得它们非常适合语义分割,因为它们自然地引进跳过连接和多级监督。
在本文中,我们通过增加上采样路径来扩展DenseNets以作为FCNs,以恢复输入分辨率。简单地建立上采样路径会导致在softmax层之前具有非常高分辨率以及难以处理的数量的特征映射。
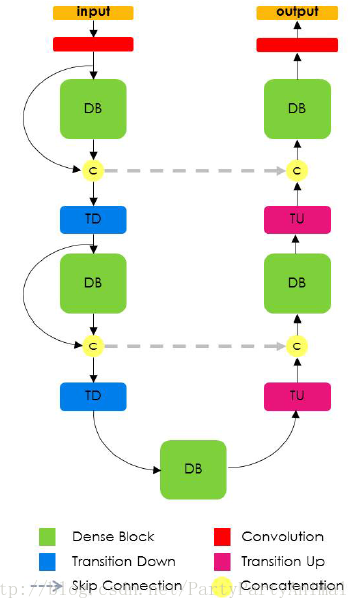
为了减轻这种影响,我们只对上一个密集块创建的特征映射进行上采样。这样做允许在上采样路径的每个分辨率下具有多个密集块,而与池层的数量无关。而且,考虑到网络架构,上采样的密集块将包含在其他密集块中具有相同分辨率的信息结合起来。较高分辨率的信息通过下采样和上采样路径之间的标准跳过连接来传递。提出的架构的细节如下图所示。
因此,本文的贡献可以总结如下:
(1)我们扩展DenseNet架构为全卷积网络用于语义分割,同时减轻特征图爆炸。
(2)从密集块建立的上采样路径比采用更多标准操作的上采样路径(U-Net等)更好。
(3)该网络可以超越当前最先进的城市场景理解结果,而不需要使用预训练参数,也不需要进一步的后处理。
2 最近的工作
最近在语义分割方面的模型结构改进思路有:
(1)改善上采样路径并增加FCN内的连通性;
(2)引入模块来进行更充分的上下文理解;
(3)赋予FCN架构提供结构化输出的能力。(可选)
首先,解决FCN上采样路径中的分辨率恢复问题的方案包括:
(1)简单的双线性插值;
(2)更复杂的运算符,包括unpooling和转置卷积等;
(3)下采样路径到上采样路径之间的跳过连接(skip connection);
(4)恒等映射和长跳过连接的结合。
其次,为语义分割网络引入更大上下文的方法:
(1)为特征图中的每个像素添加一个无监督全局图像描述符(论文:Unrolling loopy
top-down semantic feedback in convolutional deep networks)
(2)利用RNN网络在水平和垂直两个方向上扫描图像来检索上下文信息(论文:Reseg: A recurrent
neural network-based model for semantic segmentation)
(3)引入扩张卷积来替代后期的CNN池化层,以捕获更大的上下文而不降低图像分辨率(论文:Semantic image segmentation with deep convolutional nets and fully connected crfs)
(4)为FCNs提供一个上下文模块作为(built as)一个扩张卷积层的堆栈来扩大网络的视野(论文:Multi-scale context aggregation by dilated
convolutions)
第三,CRF用来强化分割输出的结构一致性。
值得注意的是,当前最先进的用于语义分割的FCN体系结构通常依靠预先训练的模型来改善其分割结果。
3 全卷积DenseNets
FCN是由下采样路径、上采样路径和跳过连接组成的。跳过连接可帮助上采样路径通过从下采样路径重用特征图来恢复空间详细信息。我们的模型的目标是通过扩展更复杂的DenseNet架构来进一步利用特征重用,同时避免网络上采样路径上的特征爆炸。
3.1 DenseNets回顾
第l层的输出定义为:

其中[…]表示连接操作。这种连接模式强烈地鼓励特征的重用,并使得体系结构中的所有层都能接收到直接的监督信号。每层的输出具有k个特征图,其中k(以下称为增长率参数)通常被设置为较小的值(例如,k = 12)。因此,DenseNets中的特征映射的数目随着深度线性增长(例如第l层之后输入将具有l*k个特征映射)。
transition down操作用来减少特征图的空间维度。这样的转换由1*1卷积(保存特征图的数量)和2*2池化操作组成。

上图为dense block的结构。从具有m个特征图的输入x0(输入图像或transition down部分的输出)开始,块的第一层通过应用H1(x0)来生成具有k个特征图数量的输出x1。这k个特征图通过级联([x1; x0])堆叠到先前的m个特征图并且被用作到第二层的输入。同样的操作重复n次,导致一个新的具有n*k个特征映射的密集块。(图中的n=4)
3.2 从DenseNets到FC-DenseNets
第3.1小节描述的DenseNets体系结构构成了全卷积密集网(FC-DenseNet)的下采样路径。在下采样路径中,特征数量的线性增长通过池化操作之后每个特征地图的空间分辨率的降低来补偿。下采样路径的最后一层被称为bottleneck。
为了恢复至输入空间分辨率,FCN引入了由卷积、上采样操作(转置卷积或unpooling操作)和跳过连接组成的上采样路径。在FC-DenseNets中,我们用密集块和上采样操作来代替卷积操作,称为transition up。transition up模块由一个对上一个特征图进行上采样的转置卷积组成。上采样后的特征通过跳过连接和之前的下采样路径中同分辨率的特征图连接起来,以形成新密集块的输入。由于上采样路径增加了特征映射空间分辨率,特征数量的线性增长对内存要求过高,特别是在softmax层之前的全分辨率特征。
为了克服这个限制,密集块的输入不与其输出串联。因此,转置卷积仅应用于由最后一个密集块获得的特征图,而不是所有到目前为止连接的特征图。最后一个密集块包含了之前所有同分辨率密集块中的信息。请注意,由于池化操作,早期密集块的一些信息在池化过程中丢失。尽管如此,这些信息在网络的下采样路径中是可用的,并且可以通过跳过连接来传递。因此,上采样路径的密集块使用给定分辨率下的所有可用特征图来计算。
3.3 语义分割结构
这部分讨论FC-DenseNet103网络。

上表定义了密集块层(卷积方式为SAME),transition down和transition up结构。

上表为Dense103的所有层,包括103个卷积层。所提出的上采样路径恰当地减轻了DenseNet特征图的爆炸,导致合softmax前的特征映射数为256。
通过最小化像素交叉熵损失。
4 试验
For a given class c,
predictions (oi) and targets (yi), the IoU is defined by:

4.1 结构和训练细节
我们使用HeUniform(均匀分布,范围为-scale~scale,其中scale=sqrt(6/f_in),f_in为待初始化的矩阵的行)初始化我们的模型,并用RMSprop对它们进行训练,初始学习率为1e-3,每个epoch后指数衰减为0.995。所有模型都训练随机裁剪和垂直翻转的数据。对于所有的实验,我们用全尺寸的图像和1e-4的学习率来微调我们的模型。
模型的权重衰减为1e-4和dropout=0.2。对于BN,在训练,验证和测试时间使用当前批量统计(current batch statistics)。
4.2 CamVid数据集
数据集网址:http://mi.eng.cam.ac.uk/research/projects/VideoRec/CamVid/
数据集细节:CamVid是用于城市场景理解的全分割视频的数据集。共701帧,其中367帧用于训练,101帧用于验证,233帧用于测试,共11类。 每帧图片大小为360*480。
模型:将原图裁剪为224*224,batchsize=3。最后,模型用全尺寸图像进行微调。
结果如下:

(1)FC-DenseNet56:每个密集块包含4层,增长率k=12;
(2)FC-DenseNet67:每个密集块包含4层,增长率k=16;
(3)FC-DenseNet103:增长率k=16;
CamVid中的图像对应于视频帧,因此数据集包含时间信息。一些最先进的方法,如(Feature space optimization for semantic video segmentation)将远距离时空正则化与FCN的输出相结合,以提高其性能。我们的模型能够超越这种最先进的模型,而不需要任何时间平滑。然而,任何后处理时间正则化都是对我们方法的补充,并可能带来额外的改进。
在分割结果中,树木,柱柱,人行道和行人显得非常清晰。然而,在树木中发现的细节可能会与列杆混淆,公交车和卡车可能会与建筑物混淆,而店铺标志可能与道路标志混淆。
4.3 Gatech 数据集
数据集网址:http://www.cc.gatech.edu/cpl/projects/videogeometriccontext/
数据集细节:Gatech是一个几何场景理解数据集,其中包括63个视频用于训练/验证和38个测试。每个视频有50到300帧(平均190)。为每帧提供了一个像素分割图。共8类。该数据集最初是为了学习户外视频场景的三维几何结构而建立的,该数据集的标准度量是平均全局精度。
我们使用在CamVid数据集上预训练的FC-DenseNet103模型,移除softmax图层,输入大小为224*224,batchsize=5,epoches=10。鉴于Gatech帧中的高冗余度,我们仅使用了10帧中的一帧用来训练模型并在所有全分辨率测试集框架上进行测试。

网络定义部分:
class Network():
def __init__(self,
input_shape=(None, 3, None, None),
n_classes=11,
n_filters_first_conv=48,
n_pool=5,
growth_rate=16,
n_layers_per_block=[4, 5, 7, 10, 12, 15, 12, 10, 7, 5, 4],
dropout_p=0.2)
"""
This code implements the Fully Convolutional DenseNet described in https://arxiv.org/abs/1611.09326
The network consist of a downsampling path, where dense blocks and transition down are applied, followed
by an upsampling path where transition up and dense blocks are applied.
Skip connections are used between the downsampling path and the upsampling path
Each layer is a composite function of BN - ReLU - Conv and the last layer is a softmax layer.
:param input_shape: shape of the input batch. Only the first dimension (n_channels) is needed
:param n_classes: number of classes
:param n_filters_first_conv: number of filters for the first convolution applied
:param n_pool: number of pooling layers = number of transition down = number of transition up
:param growth_rate: number of new feature maps created by each layer in a dense block
:param n_layers_per_block: number of layers per block. Can be an int or a list of size 2 * n_pool + 1
:param dropout_p: dropout rate applied after each convolution (0. for not using)
"""
if type(n_layers_per_block) == list:
assert (len(n_layers_per_block) == 2 * n_pool + 1)
elif type(n_layers_per_block) == int:
n_layers_per_block = [n_layers_per_block] * (2 * n_pool + 1)
else:
raise ValueError
# Theano variables
self.input_var = T.tensor4('input_var', dtype='float32') # input image
self.target_var = T.tensor4('target_var', dtype='int32') # target
#####################
# First Convolution #
#####################
inputs = InputLayer(input_shape, self.input_var) # 224*224*3
#Inputlayer只用于接收数据,不对数据做任何处理,类似于tensorfolw里的placeholder功能
# We perform a first convolution. All the features maps will be stored in the tensor called stack (the Tiramisu)
stack = Conv2DLayer(inputs, n_filters_first_conv, filter_size=3, pad='same', W=HeUniform(gain='relu'),nonlinearity=linear, flip_filters=False) # 224*224*3
# The number of feature maps in the stack is stored in the variable n_filters
n_filters = n_filters_first_conv # 48
#####################
# Downsampling path #
#####################
skip_connection_list = [] #将下采样路径中每个dense block的结果存入skip_connection_list
for i in range(n_pool): # n_pool = 5
# Dense Block
for j in range(n_layers_per_block[i]):
#n_layers_per_block[0/1/2/3/4] = 4/5/7/10/12
# Compute new feature maps
l = BN_ReLU_Conv(stack, growth_rate, dropout_p=dropout_p) # 224*224*16
# And stack it : the Tiramisu is growing
stack = ConcatLayer([stack, l])
n_filters += growth_rate
# At the end of the dense block, the current stack is stored in the skip_connections list
skip_connection_list.append(stack)
# Transition Down
stack = TransitionDown(stack, n_filters, dropout_p)
skip_connection_list = skip_connection_list[::-1] #将顺序完全换过来
#####################
# Bottleneck #
#####################
# We store now the output of the next dense block in a list. We will only upsample these new feature maps
block_to_upsample = []
# Dense Block
for j in range(n_layers_per_block[n_pool]): #n_layers_per_block[5] = 15
l = BN_ReLU_Conv(stack, growth_rate, dropout_p=dropout_p)
block_to_upsample.append(l)
stack = ConcatLayer([stack, l])
#######################
# Upsampling path #
#######################
for i in range(n_pool):
# Transition Up ( Upsampling + concatenation with the skip connection)
n_filters_keep = growth_rate * n_layers_per_block[n_pool + i] # 16 *(15/12/10/7/5)
stack = TransitionUp(skip_connection_list[i], block_to_upsample, n_filters_keep)
# Dense Block
block_to_upsample = []
for j in range(n_layers_per_block[n_pool + i + 1]):
l = BN_ReLU_Conv(stack, growth_rate, dropout_p=dropout_p)
block_to_upsample.append(l)
stack = ConcatLayer([stack, l])
#####################
# Softmax #
#####################
self.output_layer = SoftmaxLayer(stack, n_classes)














 1658
1658











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









