






版权声明:本文为CSDN博主「青青大肥羊」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_31425127/article/details/80600241
今天介绍一篇文章,FCN和DenseNet的超强结合体,2017CVPR,一起来欣赏下吧!
文章地址:https://arxiv.org/abs/1611.09326
文章代码:文章摘要中给出了源码,是用Theano写的,github上有用Tensorflow写的,有需要可以去看看
1、 FC-DenseNet提出背景
FCN:FCN是首个在传统CNN的基础上解决像素级语义分割问题的网络。同过加入上采样层,使得输出图像尺寸和输入一样大小,也即网络的输入可以是任意大小的图像,不需要像AlexNet那样需要统一裁剪成28x28大小;通过加入跳跃连接层,解决了由下采样带来的分辨率损失问题,从而使得分割结果更为精细。详细内容可以参考我之前写的文章:https://blog.csdn.net/qq_31425127/article/details/80570373
ResNet:ResNet是为解决”训练非常深的网络会导致网络不收敛且效果退化”的问题而产生的,这也从侧面说明了ResNet网络都比较深,目前有ResNet-50、ResNet-101、ResNet-1020。ResNet网络的核心就是一个叫“残差块”的东西,是由一系列非线性转换及一个恒等映射(shortcut connection)组成的。整个ResNet可以看作是一个个残差块组合而成。大概模样长下面这样,截这个图主要是为了与后面的DenseNet做对比。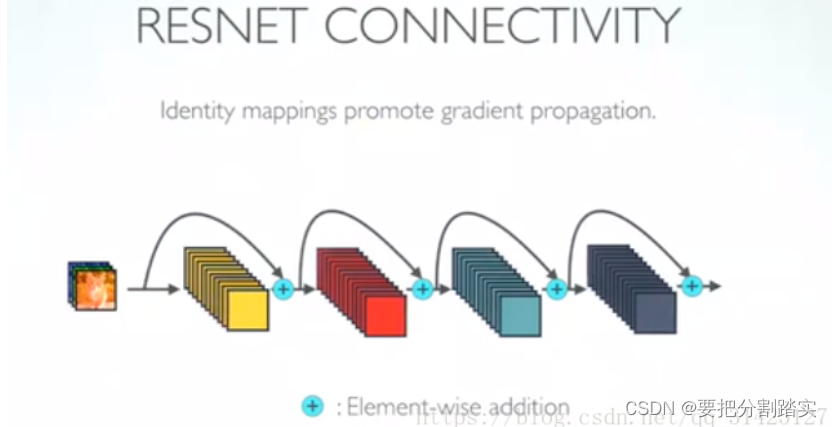
DenseNet:DenseNet主要是由一系列“稠密块”组成,这个“稠密块”与ResNet的“残差块”不同,“残差块是像素级求和,“稠密块”是按通道数级联。一个“稠密块“就是长下面这个样子:

是不是有点晕,来个能稍微看得懂的,就是下面这个,和上面结构一样,但我觉得这个图更直观的凸显了通道级联这个特点:
FC-DenseNet:目的是将DenseNet和FCN结合起来,让DenseNet不再做单一分类,而是和FCN一样做到像素级分割。通过加入FCN的上采样结构,从而让网络输出尺寸和输入一样大小。
2、现在来详细说说DenseNet
2.1 DenseNet Block
假设网络输入是X0,Xl表示第l层的输出,Hl是作用于前一层输出的非线性映射函数,则
对于一个普通CNN而言,Xl=Hl*(Xl-1)
对于ResNet的一个Residual Block而言,
对于DenseNet的一个DenseNet Block而言,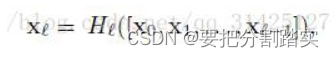
[x0,x1,…,xl-1]表示将0到 l-1层的输出feature map按通道进行合并,而resnet是做值的相加,通道数是不变的。这里的Hl包括BN−>ReLU−>Conv(3×3)
2.2 Bottleneck layer
虽然说每个层只产生kk个输出,但是后面层的输入依然会很多,因此引入了Bottleneck layers 。本质上是引入1x1的卷积层来减少输入的数量,HlHl的具体表示如下
BN−>ReLU−>Conv(1×1)−>BN−>ReLU−>Conv(3×3)
文中将带有Bottleneck layers的网络结构称为DenseNet-B。
2.2 Translation layer
为了减少特征图的空间维数,每两个DenseBlock的之间又加了一个Transition layers,由BN−>Conv(1×1)−>averagePooling(2×2)组成。
如果你看到DenseNet-C这个网络,表示增加了这个Translation layer,
如果你看到DenseNet-BC这个网络,表示包含Bottleneck layer和Translation layer。
DenseNet就是由以上几个部分的组合而成:
3、FC-DenseNet
3.1 网络结构
这里写图片描述
这个’U‘字形左边一部分就是第二节中DenseNet网络的DB1~DB3,右边是一系列上采样过程,可以看到新加入的一个块就是Transition Up。
这个Transition Up包含了一个转置卷积,用于对特征图进行上采样,上采样得到的特征图和左边DB输出的特征图进行skip connection(即concat),由于上采样操作增加了特征图的大小以及数量,从而需要更多的内存,解决办法就是:将DB的输入和输出不按通道进行concat,因此转置卷积只作用于最后一层DB的输出,而不是concat所有的特征图。
3.2 语义分割结构
3.2.1 Dense Block
这里的Dense Block和第2节中的DenseNet Block是不一样的,作者说因为网络层数较多(103层),如果像DenseNet网络那样每一层卷积都把前面的所有的特征图都按通道级联起来,会造成网络参数膨胀,因此作者只是把上一层的特征图和本层特征图级联而不是前面所有。详见下图: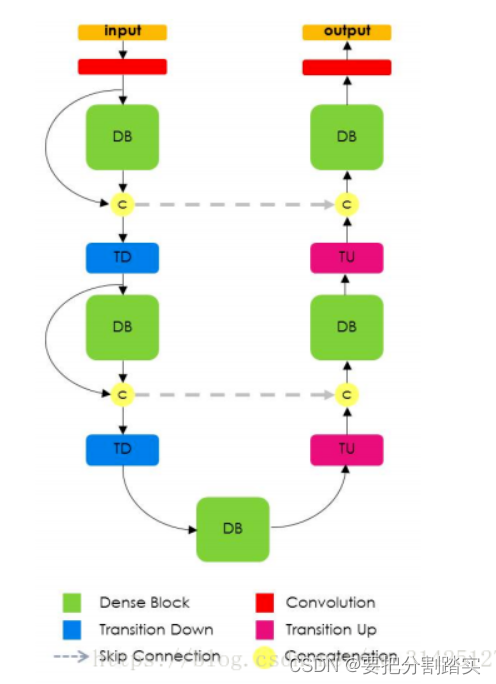
C指的是concat,Layer层具体结构如下图: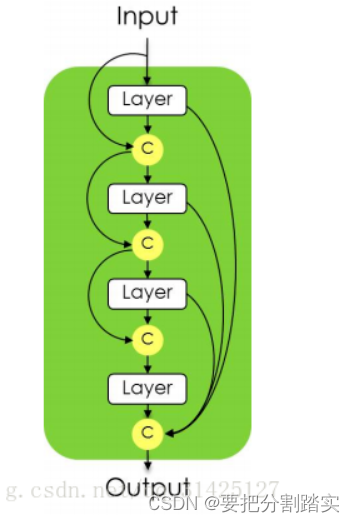
3.2.2 Transition Down
下采样层,图片分辨率降低
3.2.3 Transition Up
上采样层,图片分辨率提高,目的就是将网络输出的图像尺寸变得和输入尺寸一样大小,这样才能进行损失误差的参数更新,同时和FCN一样,做了一个skip connection,与图像低维信息相融合,结果会更精细。
介绍一个DenseNet的视频:
https://v.qq.com/x/page/g0530rsighw.html
————————————————
版权声明:本文为CSDN博主「青青大肥羊」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_31425127/article/details/80600241















 218
218











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









