







论文地址:https://arxiv.org/pdf/1707.00243.pdf
代码地址:https://github.com/jfzhang95/DeepGrabCut-PyTorch
(主要就是提出方法的前两步!!!!)
大多数以前基于边界框的分割方法都假设边界框很准,但实际上经常不准。在本文中,提出了一种新的分割方法,它使用矩形框作为软约束,将其转换为欧几里德距离图,将图像与这些距离图concat作为输入。(因此这也是一种基于边界框的分割方法)
对于分割来说重要的两点:(1)框要完整的包含目标 (2)要包含足够的上下文信息进行分割。
传统的模型都依赖于基本的颜色和边缘信息,并且不使用诸如对象的结构和形状之类的高阶知识。
提出的方法:
(1)Rectangle sampling:
randomly jittering the ground truth bounding box
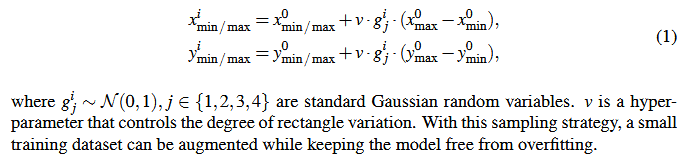
(2)Rectangle transformation:
transforms each of the sampled rectangles into a distance map
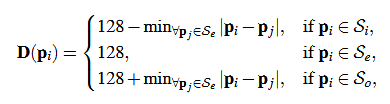
(3)CEDN model training:
编码器网络由若干卷积和最大池化层组成,它们将输入数据抽象为小特征映射,而解码器网络具有若干卷积和unpooling层,从粗略到精细重建图像细节。
二分类分割,前景or背景。
输入有4个channel,为了解决过拟合,在解码器网络的每个卷积层之后使用Dropout。此外,在每个训练epoch开始时随机重新采样所有训练数据。
实验:
对于MS COCO数据集,我们使用2014 train-80k数据集进行训练。在每次训练迭代中,我们为每个实例随机抽样4个边界框,并使它们成为小批量。采样参数v为0.15。训练输入大小调整为320×320。我们使用Adam [10]进行优化。学习率为10-5.非最大抑制的阈值为0.5。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









