






概述
在物体检测中1,IOU阈值被用于判定正负样本。在低IOU阈值比如0.5的状态下训练模型经常产生噪音预测,然而检测效果会随着IOU增加而降低。两个主要因素:1.训练时的过拟合,正样本指数消失 2.检测器最优IOU与输入假设的不匹配。
一个单阶段的物体检测器CascadeR-CNN被提出用于解决这些问题。网络由一个检测序列组成,这些序列训练时会伴随IOU增长从而对FP样本更加有选择性地判别。检测器一个阶段一个阶段进行训练,检测器输出的优质分布用于训练下一个更高质量的检测器。逐步改进假设的重采样保证了所有检测器都有一组等价大小的正样本集,减少了过拟合问题。同样的级联程序应用于推理,使每个阶段的假设和检测器质量之间更接近匹配。cascade在COCO数据集上打败了其他单阶段检测器。
介绍
物体检测需要解决两个主要目标,首先检测器需要解决识别问题,为了从背景中区分出前景并且赋值正确的类别标签。第二十检测器需要解决定位问题,为不同的物体赋值正确的bbox。这些都是非常困难的,由于检测器需要处理许多近似的FP样本,这些样本都是相似但是不同的,检测器需要找到TP样本的同时抑制FP样本。
最近的一些工作例如Fast R-CNN, FPN,Faster R-CNN都基于双阶段结构。这些网络被架构用于多任务学习问题:结合了分类与bbox回归。不像物体识别,IOU阈值被用来定义正负样本。然而,IOU经常使用0.5,这是相对宽松的标准。图1可以看到低IOU训练出的检测器产生带有噪声的bbox。

FP样本往往能够通过阈值0.5的检测,使用0.5作为IOU阈值训练模型会使得网络对于FP样本的过滤能力下降。
作者定义一个预测的质量为它与GT的IOU,检测器的质量则是训练时使用的IOU阈值。作者目的在于研究高质量检测器(神经网络高质量检测器)一个基本的思路是单阶段网络只能够被优化在一个等级上。
图1c和d分别展示了三个检测器在不同IOU阈值下训练的定位于检测表现。定位效果使用IOU的输入提议进行评估。检测效果作为IOU阈值的函数。图一c可以看出每个bbox回归器IOU最优表现都是在检测器训练时使用的IOU值的附近。图一d可以看出低IOU样本下阈值使用0.5的效果比0.6好,但在高IOU样本中表现不好。总体来讲,一个检测器只能在一个IOU等级上面取得较好结果。高级检测器需要更进一步匹配需要处理的假设(hypotheses)总体来说只有在高质量输入的情况下才会得到高质量输出。
为了产生高质量检测器,不能简单的提高训练时的IOU,从图1d中可以看出这样做反而会降低表现。问题在于假设的分布对于检测器的提议往往严重不平衡且低质量(特征图中潜在的含有目标的特征与检测器输出特征差距大)总的来说就是强加一个高IOU会导致正训练样本指数减少。密集样本伴随着高IOU会导致过拟合。高质量的检测器只有对于优化高质量的假定输出才是必要的,对于其他质量的假定输出,不同等级的检测器提取效果是次优的。
这篇论文中作者提出了一个新的检测器结构:Cascade R-CNN。这是对于R-CNN一个多阶段拓展网络,检测器随着cascade深入对于FP样本有着更强的判别力。cascade的集序训练的顺序的,使用前一个输出作为后一个输入训练。这么做是因为从图1c中可以看出回归器输出的IOU始终比输入IOU好(几乎所有的曲线都在灰色直线之上)可以看出使用特定IOU训练出来的检测器的输出分布是优质的,可以用于训练下一个更高质量的检测器。这种方法类似于boostrapping。
Cascade R-CNN易于使用且训练时端到端的。作者的实验表明简单使用Cascade R-CNN可以在COCO数据集检测任务上大幅超越所有先前的单模型检测器,尤其是以高IOU进行检测评估的方式下。Cascade可以被构建于任何基于R-CNN框架的的双阶段检测器中。在增加少量计算的前提下获得2-4点的提升。这种增益与基线网络的本身的性能无关,因此这一一种简单有效的检测结构且可以被植入到任何物体检测任务中去。
2.相关工作
由于RCNN成功的结构,解决检测问题的双阶段方案通过结合一个提议检测器(区域提议)和一个区域范围( region-wise)的分类器的做法是过去的主导方法。为了降低R-CNN中多余的计算,SPP-Net与Fast-RCNN引入了一种区域特征提取方法,显著加速了检测器推理速度。之后的Faster-RCNN通过引入RPN更进一步加速。这个结构成为双阶段物体检测的标准架构。最近的一些工作着力于解决各种细节问题,比如R-FCN提出了有效的 区域范围的(region-wise)全卷积网络,提高运行速度同时保证精度不下降,避免了Faster-RCNN中繁重的卷积计算。另一边MS-CNN和FPN在多层检测输出以减缓RPN感受野与物体实际尺寸之间的不匹配,同时提高了检测的召回率。
单阶段检测器的盛行主要是由于计算的高效性,这些结构近似于滑动窗口策略。YOLO推理输出非常系数的检测结果。当使用高效的backbone网络之后可以实现物体的实时检测。SSD与RPN相似的检测检测器,但是使用了多路特征映射在不同的分辨率下,以覆盖到不同大小的物体。这些单阶段网络的限制是精确度往往低于双阶段检测器。最近RetinaNet在提出了一种针对前背景极度不平衡问题的解决方法(focal loss)取得了比双阶段还要好的效果。
一些多阶段物体检测的方法也被提出。多区域( multi-region)检测器引入了迭代bbox回归(iterative bounding box regression)在这里多次使用R-CNN来产生更好的bbox。CRAFT与AttractionNet使用了多阶段步骤来产生正确的提议,之后前前向入到Fast R-CNN中。还有的工作嵌入了序列分类结构到物体检测中。
3.物体检测
Cascade R-CNN是基于Faster R-CNN的拓展。第一个阶段是提议自网络(H0),被用于生成全图的假设预检测(proposals)第二节福安这些假设会被感兴趣区检测子网络(H1)处理,也就是网络的Head部分。最终分类分数C以及回归框B被赋值到每个假设。作者专注于建模多阶段检测子网络,采用但不限制于使用RPN进行区域提议。
3.1 BBox回归
BBox由四个值构成,BBox回归目标为使用回归函数f(x,b)回归候选框b到目标框g上,函数表示为:
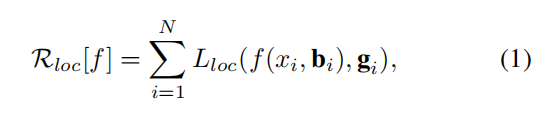
R-CNN中位置损失函数使用的是L2损失,之后在FastR-CNN中更新为smoothL1。为了鼓励回归的尺度和位置不变性( 原文:invariant to scale and location 是为了归一?)距离向量被定义为∆ = (δx, δy, δw, δh)
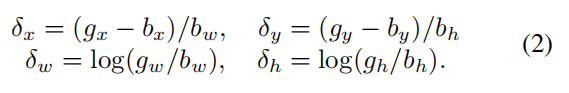
从上式可以看出BBox回归通常是基于b的细小调整,公式2中的数字可能非常小,因此回归的risk往往小于分类(俺没明白有啥risk,网络效果不好吗?)为了提升多目标学习的有效性,∆通常用均值和方差归一化,也就是使用公式δ′x = (δx - µx)/σx替换原有的δx 。
一些工作指出f的单回归步骤对于正确的位置是不充分的。使用迭代的f作为后处理步骤:
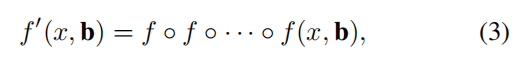
来提炼BBox b,这被叫做 iterative bounding box regression(迭代bbox回归)可以被用于图三b中的推理结构
 这种迭代方法忽视了两个问题,一个是图一提到的使用IOU阈值0.5来训练出的结果对于高IOU是次优的。其次是图2中
这种迭代方法忽视了两个问题,一个是图一提到的使用IOU阈值0.5来训练出的结果对于高IOU是次优的。其次是图2中
 bbox的分布在每次迭代之后变化巨大。回归器对于初始化分布是最优的但之后可能就不是最优了(不理解),由于这些问题迭代bbox需要大量的人工处理,提议累积的方式,box方式等。总之使用超过两次f是不利的。
bbox的分布在每次迭代之后变化巨大。回归器对于初始化分布是最优的但之后可能就不是最优了(不理解),由于这些问题迭代bbox需要大量的人工处理,提议累积的方式,box方式等。总之使用超过两次f是不利的。
3.2 分类
分类函数h(x)为图片块赋值类别,类别0表示背景已经保留对象(不需要分类的对象?)h(x)是类上后验分布M+1维估计。

y是类别标签。基于给定的训练集xi yi学习最小化分类风险
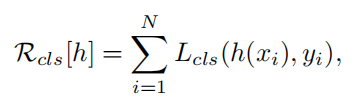
Lcls是分类交叉熵损失函数。
上面对于回归和分类讲的叽里呱啦的
3.3检测质量
因为bbox中包含目标物体和一部分背景,所以判断样本正负有困难。这个问题有时通过IOU来解决。如果IOU阈值为u,框出的图片块被认为是一类的正样本。这类标签的假定x是u的函数:

gy是物体g的类别标签。这个IOU阈值u定义了检测器的质量。
物体检测是一个挑战,因为无论IOU如何,检测设置都是高对抗性的(highly adversarial 没明白,那意思是u上去之后会增加FN?训练时也不能充分训练因为过滤掉了过多的样本?) 当u高时,正样本包含少量的背景,但无法得到足够的正训练样本(IOU低的都被滤掉了)当IOU低的时候可以得到大量且多种多样的正样本,但是训练的检测器就会对于FP样本丧失足够的敏感性。总的来说,单一的范磊器很难在所有IOU阈值下得到全部最优效果。在推理的时候,由于大多数假定输出有提议检测器(例如RPN或者Selective Search)生成,且假定输出质量低下。这就需要对其进行更多的筛选(用更多的检测器)一个折中的方式是设置u=0.5,这是一个相对低的IOU,会得到更多低质量检测,这些检测被人们认为接近FP,就像图一a中展示的那样。
一个土掉渣的解决方法是开发一套分类器,结构是图三c,其需要优化的损失为多等级质量的目标, 公式:

U是IOU阈值,这个数与integral loss类似, U = {0.5, 0.55, · · · , 0.75},被设计用于契合COCO的评估指标。在定义上来讲,分类器需要在推理时组装。这个解决方法失败在没有解决在不同数量正样本上计算不同损失的操作(没懂,是把多个IOU阈值的结果求均值吗?估计得看 Integral Loss论文)
 上图4中可以看到正样本的数量随着IOU增大急速减少。这是有问题的,因为高质量分类器容易过拟合(我个人还是觉得IOU高了之后训练样本减少导致的过拟合,或者说训练数据本来就不足,容易过拟合。低IOU带来的噪声是不应该用来解决过拟合问题的)此外,这些高质量检测器处理低质量提议时是次优的。由于这些原因,公式6的方法无法在大多等级下得到更高的准确率。
上图4中可以看到正样本的数量随着IOU增大急速减少。这是有问题的,因为高质量分类器容易过拟合(我个人还是觉得IOU高了之后训练样本减少导致的过拟合,或者说训练数据本来就不足,容易过拟合。低IOU带来的噪声是不应该用来解决过拟合问题的)此外,这些高质量检测器处理低质量提议时是次优的。由于这些原因,公式6的方法无法在大多等级下得到更高的准确率。
CascadeR-CNN
这一节作者介绍Cascade R-CNN物体检测
4.1 级联的(Cascaded)BBox回归
在图1c中可以看到,要求单回归器在所有质量等级上统一的完美运行是非常困难的。困难的回归任务可以被分解为简单地步骤序列,收到Cascade pose 回归以及面部对齐的启发。Cascade R-CNN被构架为级联的回归问题,见图三d。这依赖于一个级联的specialized回归器:

T是级联阶数。值得注意的是回归器f在级联当中被w.r.t优化。采样的分布{bt}在对应的阶段中,而不是初始分布{b1}。这种级联显著提升输出假设。
与迭代BBox( iterative BBox)结构不同有几点:首先是 iterative BBox作为提升bbox的前处理方法而cascaded回归作为重采样的方法来在不同的阶段改变假设输出的分布。第二,由于这种方法在训练和推理都使用了,所以分布没有差异。第三,多个专用的回归器{fT , fT 1, · · · , f1}在不同的阶段中重采样最优。与公式3不同的是,公式3只在初始化分布上面是最优的。这些区别使得Cascade rcnn在定位上相比迭代bbox更加精确且不需要进一步人工调试。
在3.1中讨论的 ∆ = (δx, δy, δw, δh)在公式2中需要使用均值和方差来进行归一化以有效的多任务学习。在每一个回归阶段,这些这些统计将会被序列评估,就像展示在公式2中的一样.训练时,对应统计在每个阶段使用∆进行归一化。
4.2 级联检测
在图4中左侧展示的初始化的假设分布也就是RPN提议是严重偏向低质量的。这不可避免的导致高质量分类器的无效学习。CascadeR-CNN通过作为resampling mechanism的级联回归器解决这个问题。这样坐的动机是因为图1c中所有的曲线都在灰色对角线之上,BBox回归器为特定IOU训练能够产生更高的bbox iou。因此从一系列样本(xi, bi)开始,级联回归为了更高的IOU依次重采样样本分布 (x′i, b′i)这种方式可以保证连续的阶段中正样本数量可以大致保持不变,即使是IOU增高。图4中展示的更倾向于高质量样本的分布在每个重采样步骤之后。可以得到两个结果,首先是不会发生过拟合,因为样本在每一个等级都十分充足。其次是更深层次的检测器对于更高IOU阈值是最优的。值得注意的是,一些离群值被增长的IOU逐渐移除,正如图2中展示的那样,使得序列专用检测器能够被更好训练。
在每个目标t中,R-CNN包含一个分类器ht和一个回归器ft,这两个数被IOU阈值ut所优化,同时 ut > ut-1。这个是被最小化损失保证的,损失函数:

g是xt的ground truth, λ = 1是平衡系数, yt是xt的标签。不同于公式6的完全损失(integral loss)这保证了一系列检测器在增加质量(IOU)的情况下有效训练。在推理时,通过使用同样的级联处理方法以及更高的检测器,只需要在设定更高的假设输出,假定输出的质量就会顺序提升。这是从图1的cd看出来的
5.实验结果
CascadeR-CNN使用COCO2017。这个数据集包含118K训练数据,5K评估数据,20K没有标注的测试数据。COCO定义AP为是IOU阈值从0.5到0.95间隔0.05计算一次AP的均值。这种评估方式能够衡量各种质量的检测。所有的模型都在coco上面训练,之后使用val进行评估。最终结果在test-dev集上报告
5.1 实施细节
处于简单的目的,所有的回归器的类别都是不可知的。在CascadeR-CNN中所有的级联检测阶段有着同样的结构,这些结构是基线检测网络的头。总的来说,CascadeR-CNN有四个阶段:一个RPN以及三个检测,其IOU分别为U = {0.5, 0.6, 0.7},第一个阶段采样与FastR-CNN和FasterR-CNN相同。之后的阶段中使用先前阶段的回归输出做简单的重采样。除了标准的图片水平翻转没有使用其他的数据增强。在单张图片上进行推理,没用其他花里胡哨的东西。所有的基线检测器都使用caffe重应用,为了公平起见使用的同样的基本代码。
5.5.1基线网络
为了测试CascadeR-CNN的适应能力,实验中选用了三种常用的基线网络:Faster-RCNN框架配合VGG-Net,R-FPN还有ResNet+FPN。这些基线网络有广泛的检测表现。除非特别指出,他们的训练都使用端到端训练而不是多阶段训练。
Faster-RCNN:
网络head部分有两个全连接层,为了降低参数量,作者使用了 Learning both weights and connections for efficient neural network论文中的方法来对不重要连接进行修剪。每个全连接层中的2048个单元被重新训练并且dropout层被移除。训练开始学习率为0.002,之后60K和90K时分别下降10倍,最终在100K时完成训练。训练在两个并行GPU上进行,每个GPU每一步迭代包含4张图片。每张图片提取128个RoI(兴趣区域,假设输出)
R-FCN:
R-FCN为ResNet添加了一个卷积层,一个bbox回归一集一个分类层。CascadeR-CNN中所有的头方法都包含这个结构。在线困难样本发掘没有被使用。训练开始学习率为0.003,之后160K和240K迭代时下降10倍,最终在280K迭代停止。训练使用4个GPU,每个GPU1次迭代包含1张图片,输出256个RoI
FPN:
由于FPN至今没有开放源码,作者的实施细节可能会有些不同。为了加强基线网络使用了RoIAlign。这个网络标识为FPN+后面被用于消融学习。通常来讲ResNet-50被用于消融实验,ResNet-101用于最终检测。训练使用学习率0.005迭代120K,之后再用0.0005迭代60K步完成训练。使用8张GPU,每张每次迭代一张图片,提取256个RoI
5.2 质量不匹配(Quality Mismatch)
 图5中展示了三种独立训练且IOU分别为{0.5, 0.6, 0.7}的检测器AP曲线。u=0.5的检测器相比u=0.6的检测器在低IOU水平时表现更好,但是在高IOU时表现不佳。然而u=0.7的AP比前两者都要低。
图5中展示了三种独立训练且IOU分别为{0.5, 0.6, 0.7}的检测器AP曲线。u=0.5的检测器相比u=0.6的检测器在低IOU水平时表现更好,但是在高IOU时表现不佳。然而u=0.7的AP比前两者都要低。

为了理解为什么会发生这种事情,作者改变了推理时提议框的质量。图5b展示了当gtbox被添加到提议集合中去获得的结果。首先u=0.5对于精确地检测并不是一个好的选择,对于低质量提议具有鲁棒性。其次,高精度的检测器要求假定输出需要满足检测器质量。之后原始监测提议被CascadeR-CNN的高质量提议所代替(u=0.6,u=0.7,分别用于低2,3个检测器)图五a也建议只有两个检测器提议与检测质量非常接近才会有显著提升。

测试中所有CascadeR-CNN检测器在所有的级联阶段中产生了相同的观测结果。图6中展示了每一个检测器在使用更精确地假设输出后能够被提升,同时质量越高的检测器增益越大。比如u=0.7的检测器在1阶段低质量提议中表现贫弱,但是能够更好地在更深层级联阶段中获得精确假定输出。此外,即使是适用同样的提议的情况下,联合训练的图6中的检测器由于独立训练的图5中的检测器。这表明了检测器在CascadeR-CNN框架中能够被更好地训练。
5.3与迭代box(Iterative BBox)和积分损失(Integral Loss)的对比
这一节中,作者对比了CascadeR-CNN与iterative BBox以及integratedloss检测器。Iterative BBox通过FPN+基线网络迭代应用三次。integral loss检测器与CascadeR-CNN有同样数量的分类器头,他的IOU分别为 {0.5, 0.6, 0.7}
定位:

级联与迭代bbox的定位表现对比在图7a中.单回归器会使得定位在高IOU情况下变差。这种影响会随着回归器迭代使用中积累,就像迭代BBox,效果其实下降了。值得注意的是迭代BBox在三次迭代之后效果变得非常差。相反的是级联回归器在最后阶段取得了最好的表现、几乎在所有IOU等级中超越了迭代BBox方法。
积分损失(Integral Loss):
图7b展示了所有分类器在积分损失检测器中的检测效果, 积分损失检测器共享单一的回归器。分类器u=0.6时获得了所有IOU等级中最好的效果。当分类器u=0.7是是最差的。所有的分类器组合都显示了没有明显的增益。
 表1中展示了迭代BBox与积分损失检测器相比于baseline检测器的略微优势。CascadeRCNN则是在所有评估指标中获得了最佳表现。对于低IOU阈值的增益是较少的,但对于高IOU阈值的增益大。
表1中展示了迭代BBox与积分损失检测器相比于baseline检测器的略微优势。CascadeRCNN则是在所有评估指标中获得了最佳表现。对于低IOU阈值的增益是较少的,但对于高IOU阈值的增益大。
5.4 消融实验
基于阶段的的对比:
 表2中总结了阶段的表现。第一阶段受益于多阶段多任务学习已经超越了基线检测器。第二阶段显著提升了效果,第三阶段详单与第二阶段。不同于积分损失检测器在高IOU分类器的贫弱。
表2中总结了阶段的表现。第一阶段受益于多阶段多任务学习已经超越了基线检测器。第二阶段显著提升了效果,第三阶段详单与第二阶段。不同于积分损失检测器在高IOU分类器的贫弱。
IOU阈值:
全部head部分使用u=0.5训练了一个CascadeRCNN。这种情况先每个阶段不同的地方就只有输入的假设(待测区域,感兴趣区域,提议区域)每一个阶段使用了对应假设进行训练。对应着图2中的分布。

表3中第一行展示了展示了CascadeRCNN相比于基线网络的提升。这显示出优化对应阶段的样本分布的重要性。第二行展示了通过增加u,检测器可以变得对FP样本更有判别性,并且针对更加精确的假设,得到额外的增益,这也在4.2节中总结了。
回归统计:
利用逐步更新的回归统计,帮助多任务学习更加有效地进行分类与回归。这些优点在表3中的模型对比中指出。学习对这些统计不敏感。
阶段的数量:

表4中总结了阶段数的影响。添加第二阶段能够明显提升基线检测器。三检测器阶段依旧提供了不少的提升,但是增加额外的4阶段(u=0.75)会导致轻微的效果下降。值得注意的是尽管所有的AP效果下降了,但是4级联阶段在高IOU等级上效果最好。三阶段级联得到最好的平衡。
5.5与SOTA的对比
不多说了,两张图:


总之就是效果还是不错地,但是考虑到运行效率的话,使用这种方法还是要有些取舍。















 1927
1927











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









