







上一趴讲的是无模型预测中用蒙特卡罗思想来进行策略评估,即离线评价某个特定策略的表现,但未进行策略的优化。这一趴对前一篇博文做一个完善和延续,因为在一个问题或者游戏中,你光会评价自己的策略好坏是远远不够的,固守成规没有用,我们得让自己变得聪明,找到最明智最优的策略,仍然采用蒙特卡罗思想,不同的是需要在策略评估后做一个策略的迭代,在一个内部循环中找到可能的最优解。这从一个预测问题上升到了控制问题,当然,所有所有方法的前提是MDPS。
一、原理——一边评估一边提升
控制思想的核心是广义策略迭代(Generalised Policy Iteration)简单来说,在一个过程中建立两个网络,一个是评估网咯,另一个是策略优化网络,开始时我们有初始策略π和价值函数V,我们先对策略π进行评估(上升箭头表示,可以得到新的价值函数V),评估的原理和方法见上一篇博文,评估结束后,我们根据结果用各种方法(greedy算法 或ε-greedy算法等)优化策略(下降箭头表示,可以得到熄灯呢策略π),与DP中的迭代类似,这两个网络的作用过程可以用下面这个图来表示:

二、trick——use Q instead of V
不知道这个算不算trick,反正当我们只有State-Value(V)的时候,如果要用贪婪等方法找出比原来好的策略,是需要通过已知的MDP(模型)的,为了计算最大的V(s),我们需要知道每个接下来的状态的状态转移概率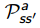


用Q替换V值之后,上面介绍的广义迭代策略的策略评估也可以同样换成对Q值的评估,示意图如下方左图,注意与上图进行比较。为了加快收敛的速率,有时候我们不必对所有状态的策略进行评估,只需要往前走几步,收集到足够用于策略提升的信息即可,这样就大大提升了算法效率。示意图如下方右图所示。

三、策略迭代网络
了解了以上基本思想,并在上一文策略评估的基础上我们开始学习蒙特卡罗控制的另一个网络——策略迭代网络。
1. ε-greedy(Q)算法——别那么贪婪,也许会有意外惊喜哦
策略迭代中最简单的提升策略方法是贪婪算法——greedy(Q),但是完全贪婪算法会有一些弊端,我们可能会困在某个暂时表现良好的行为上而忽略了其余的探索空间,在那里也许未来会获得特别特别好的奖励,谁也说不准,因此,为了确保算法的连续探索能力,我们将完全贪婪算法做了一个改善,提出了ε-greedy(Q)算法:以ε的概率选择一个随机行为,以1-ε的概率选择最大化Q值的贪婪行为。该柔性贪婪算法确保了我们每一步都能对现有策略进行优化得到更好的策略π’。简单的公式证明如下:
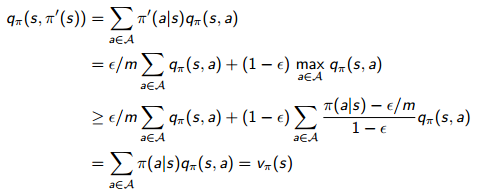
2. GILE——权衡探索和贪婪的平衡木
在蒙特卡罗控制的过程中,我们不仅需要继续探索未知空间,也要保证兼顾了最优函数,怎么保证两者的平衡以使得我们能够找到最优函数呢,来看看GILE(Greedy In the Limit with Infinite Exploration)是如何做到的。
首先算法应该满足以下两个条件:
(1)要保证搜索到了所有的状态行为对 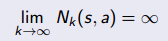
(2)要保证最终得到贪婪策略 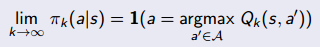
主要的思想就是选择一个ε-greedy(Q)算法,然后在迭代过程中逐渐减少ε的值直到趋向于0。在实践中,我们可以很容易想到用1/k来代替固定的ε的值。有了这个思想之后,接下来我们真正可以用一个完整的控制算法来解决某个问题了。
四、GILE蒙特卡罗控制算法——合而为一
算法的开始我们要做的是对所进行的实验组进行抽样,也就是抽取K次运行轨迹,然后先要做的是策略评估,再做策略提升。
(1)策略评估
策略评估就是根据抽取的轨迹片段对每一个状态行为对的Q(s , a)进行更新,更新的方法很简单,就是累计访问该状态行为对的次数和Q值,然后取其平均值,用上一文中的求取平均值的小trick,可以得出Q值更新规则如下:

(2)策略提升
在策略提升中,我们加入前面讨论过的GILE属性,以确保找到最优值。主要的方法是,对原来的系数ε赋值,且其值根据运行次数的增多而逐渐趋向于0,然后根据ε-greedy(Q)优化每个状态行为对对应的策略。
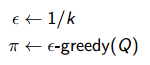
循环地进行策略评估和策略提升两个步骤,这就是一个自我学习,不断自愈的一个过程,也是强化学习算法的核心。
五、编程实战——21点游戏的延续
接下来,根据上一文中的21点游戏做一个延续实践。在上一文中,我们玩家持有的策略是“持续摸牌除非到达20点或21点”,然后用蒙特卡罗的思想对这个策略在游戏中的表现进行评估,从运行结果来看,它的表现可以说是很糟糕的。这一评估过程只是完成了我们自愈算法的其中一个部分,结合我们今天所介绍的策略提升,才可以真正改善我们在一个游戏或者问题中的行为表现。
游戏规则和评估部分就不再赘述了,在现有的评估网络基础上,我们需要加入策略提升网络。
emm……突然有点别的事情,近期可能没时间继续写咯,代码部分之后再续!
时隔几天!我又出现啦~我们来剖析一下程序吧(这里用的是完全贪婪策略),初学者啊,写一写以防自己忘掉。
1. 变量初始化
N_HANDS_TO_PLAY=5e6; % 游戏局数,可随自己设定
rand('seed',0); randn('seed',0); % 设置种子以产生随机数
nStates = prod([21-12+1,13,2]); % 定义状态个数
posHandSums = 12:21; % 只有在12到21范围内才需要策略
nActions = 2; % 0表示停牌; 1表示摸牌
Q = zeros(nStates,nActions); % 初始化Q函数
pol_pi = ones(1,nStates); % 初始策略为总是摸牌 或者随机pol_pi=unidrnd(2,1,nStates)-1;
firstSARewSum = zeros(nStates,nActions);
firstSARewCnt = zeros(nStates,nActions);
2. 大循环
for hi=1:N_HANDS_TO_PLAY, stateseen = []; deck = shufflecards(); p = deck(1:2); deck = deck(3:end); phv = handValue(p); % 玩家摸2张牌 d = deck(1:2); deck = deck(3:end); dhv = handValue(d); % 庄家摸2张牌 cardShowing = d(1);
while( phv < 12 ) % 如果点数小于12那就总是摸牌
p = [ p, deck(1) ]; deck = deck(2:end); phv = handValue(p);
end
stateseen(1,:) = stateFromHand( p, cardShowing ); % 记录状态信息 si = 1; polInd = sub2ind( [21-12+1,13,2], stateseen(si,1)-12+1, stateseen(si,2), stateseen(si,3)+1 ); pol_pi(polInd) = unidrnd(2)-1; % 初始策略随机选择 pol_to_take = pol_pi(polInd); % 动作行为从策略π中索引
while( pol_to_take && (phv < 22) ) % 当点数小于22并且按策略需要摸牌时
p=[ p, deck(1) ]; deck = deck(2:end); phv = handValue(p); % 摸牌
stateseen(end+1,:) = stateFromHand( p, cardShowing ); % 计算新的状态信息
if( phv <= 21 ) % 如果此时没有爆,在策略π集合中记录当前行为
si = si+1;
polInd=sub2ind( [21-12+1,13,2], stateseen(si,1)-12+1, stateseen(si,2), stateseen(si,3)+1 );
pol_to_take = pol_pi(polInd);
end
end
while( dhv < 17 ) % 实施庄家策略
d = [ d, deck(1) ]; deck = deck(2:end); dhv = handValue(d);
end
rew = determineReward(phv,dhv); % 判断游戏输赢
for si=1:size(stateseen,1),
if( (stateseen(si,1)>=12) && (stateseen(si,1)<=21) ) % 出去初始和爆炸后的状态
staInd=sub2ind( [21-12+1,13,2],stateseen(si,1)-12+1,stateseen(si,2),stateseen(si,3)+1 ); %计算动作的索引号(暂且)
actInd=pol_pi(staInd)+1; % 记录动作
firstSARewCnt(staInd,actInd)=firstSARewCnt(staInd,actInd)+1; % 访问计数加1
firstSARewSum(staInd,actInd)=firstSARewSum(staInd,actInd)+rew; % 累计回报
Q(staInd,actInd)=firstSARewSum(staInd,actInd)/firstSARewCnt(staInd,actInd); % 用平均值来估算
[dum,greedyChoice] = max( Q(staInd,:) ); % 贪婪策略
pol_pi(staInd) = greedyChoice-1; % 提升策略
end
end
end















 1238
1238

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









