







 本文深入探讨机器学习中的降维方法,主要聚焦于主成分分析法(PCA)和奇异值分解(SVD)。PCA通过最小投影距离和最大方差法寻找数据的主要成分,实现数据的高效降维。SVD则提供了一种无需计算协方差矩阵的降维途径,尤其适用于大规模数据。两者在数据压缩、去噪和模型学习中都有广泛应用。
本文深入探讨机器学习中的降维方法,主要聚焦于主成分分析法(PCA)和奇异值分解(SVD)。PCA通过最小投影距离和最大方差法寻找数据的主要成分,实现数据的高效降维。SVD则提供了一种无需计算协方差矩阵的降维途径,尤其适用于大规模数据。两者在数据压缩、去噪和模型学习中都有广泛应用。
还记得《三体》中的“二向箔”吗?那种降维打击真的令人印象深刻!“我毁灭你,与你何干!”我想这应该算是所有科幻小说中排的上号的攻击手段了吧~
现在,我们有一个新的敌人,它有着庞大的身躯,有八双眼睛,4个头,10只手,20条腿,你无法用语言形容它,因为它巨大的让你难以一窥全貌,它的特点太多了让你无从找到描述的切入点 —— 是的,这就是横亘在机器学习路上的第一只拦路虎——数据集。
我常常有个疑惑,在几百兆甚至几十个G的数据集中,有着上百个特征属性,我们在模型学习过程中真的需要全部使用上吗?特征属性的数量越多,模型学习的效果真的更好吗?比如现在在波士顿的房价数据集中,你觉得波士顿的车辆数量会与房价的变化有太大的关系吗?也许我们在收集数据的时候,会尽可能地考虑更多的可能性,收集更多类型的数据,但是当我们开始进行模型学习的时候,我们必须要把它当成一盘丰盛的食材,去细心的肢解它,取其精华,去其糟粕。
那么我们该如何对待这令人抓狂的敌人呢?我们是残忍而又狡猾的猎人,我们对待敌人绝不手软,我们要使用人类想象力所能想象到的极限攻击手段——降维打击去毁灭它!
现在,让我来隆重地向你们介绍,机器学习中的二向箔 —— 主成分分析法(PCA) & 奇异值分解法(SVD)!!!
一、主成分分析法
主成分分析法(Principal Component Analysis)是最常用的几种降维方法之一。PCA的思想是将原有的n维数据集映射到全新的具有正交特征的K维上。那么,我们如何得到这全新的K维空间呢?有两种思路:分别是对应于样本到超平面的最小投影距离以及样本点在超平面上的投影点的最大方差
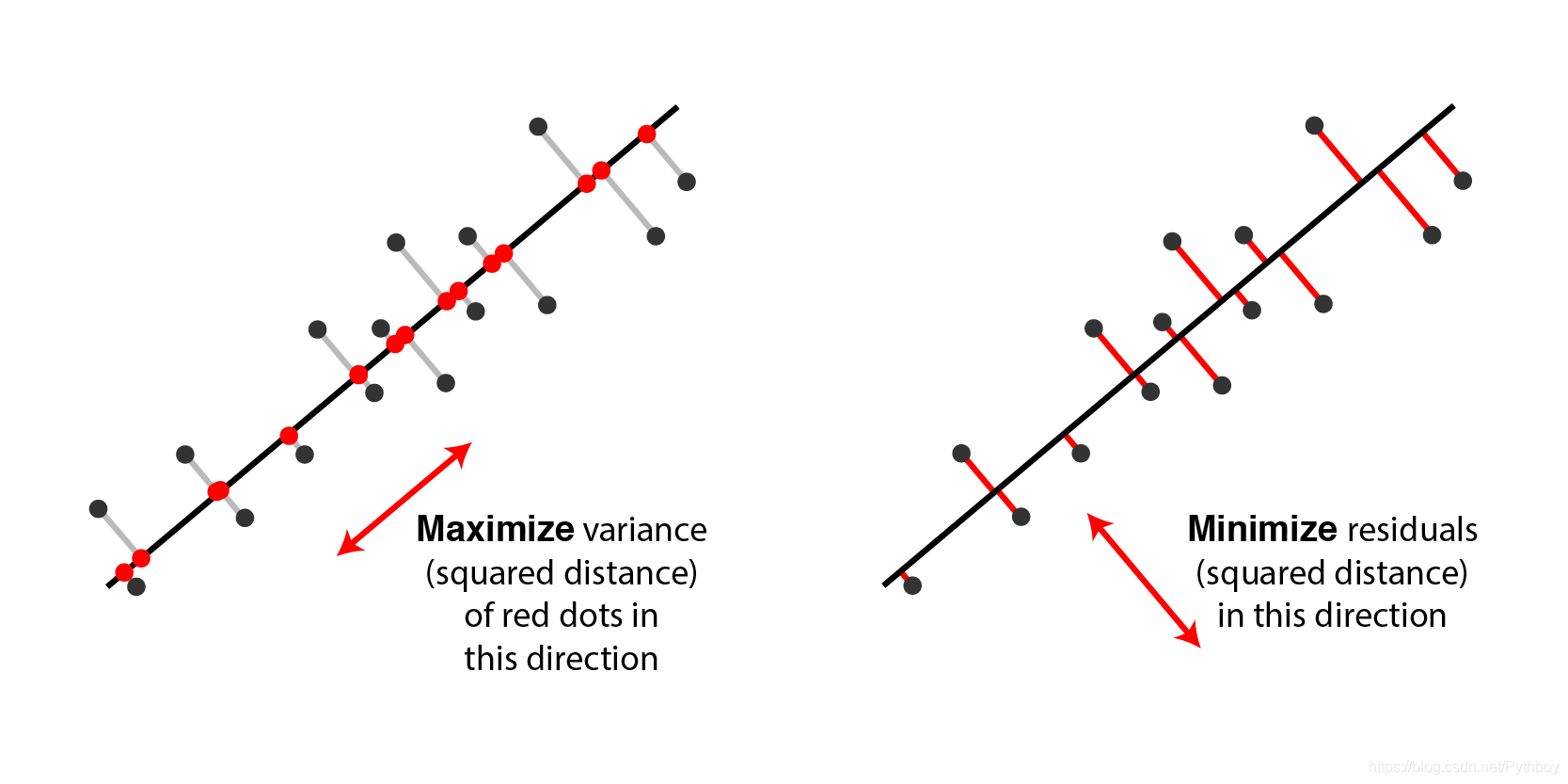
(一)PCA的推导
1.1 最小投影距离
在原先的n维空间中有大量的样本点,但是我希望现在只用一个超平面来对这所有的样本点进行恰当的表达(这一过程你可以理解为二维坐标中的点投影在一根直线上、三维坐标中的点投影在一个面上)。首先我脑海中想到的是基于我们最小二乘法思想的最近投影距离。
为了方便计算,首先我们要对m个n维样本 ( x ( 1 ) , . . . . . , x ( m ) ) (x^{(1)},.....,x^{(m)}) (x(1),.....,x(m))进行中心化操作,使其 ∑ i = 1 m x ( i ) = 0 \sum_{i=1}^{m} x^{(i)} = 0 ∑i=1mx(i)=0 ; 接着假设投影变换后的新坐标系(PS:记住这是坐标系,不是指数据点新的坐标)为 ( ω 1 , . . . . , ω n ) ({\omega _1,...., \omega_n}) (ω1,....,ωn),其中 ω \omega ω是标准正交基,即 ∣ ∣ ω ∣ ∣ = 1 ||\omega||=1 ∣∣ω∣∣=1, ω i T ω j = 0 \omega_i^T \omega_j = 0 ωiTωj=0
假设现在将维度降低至 n ′ < n n' < n n′<n, 则样本点 x ( i ) x^{(i)} x(i) 在低维左边下的投影为 z ( i ) = ( z 1 ( i ) , z 2 ( i ) , . . . . , z n ′ ( i ) ) T z^{(i)} = (z_1^{(i)},z_2^{(i)},....,z_{n'}^{(i)})^T z(i)=(z1(i),z2(i),....,zn′(i))T,其中 z j ( i ) = ω j T x ( i ) z_j^{(i)} = \omega_j^Tx^{(i)} zj(i)=ωjTx(i) 是 x ( i ) x^{(i)} x(i)低维坐标下第 j j j维的坐标。
好了,现在我们有最原始的数据集 x ( i ) x^{(i)} x(i), 也有降维后的数据集 z ( i ) z^{(i)} z(i), 也有了新的坐标系 ω \omega ω , 现在我们试图将低维的数据重新恢复至n维的 X ( i ) = ∑ j = 1 n ′ z j ( i ) w j = W z ( i ) X^{(i)} = \sum_{j=1}^{n'} z_j^{(i)}w_j = Wz^{(i)} X(i)=∑j=1n′zj(i)wj=Wz(i) ,注 : W = ( ω 1 , . . . . , ω n ′ ) W = ({\omega _1,...., \omega_{n'}}) W=(ω1,....,ωn′)
因此,为了使所有的样本到超平面的距离足够近,我们需要最小化下面的式子: ∑ i = 1 m ∣ ∣ X ( i ) − x ( i ) ∣ ∣ 2 \sum_{i=1}^{m} ||X^{(i)} - x^{(i)}||^2 i=1∑m∣∣X(i)−x(i)∣∣2
即:
∑ i = 1 m ∣ ∣ X ( i ) − x ( i ) ∣ ∣ 2 \sum_{i=1}^{m} ||X^{(i)} - x^{(i)}||^2 ∑i=1m∣∣X(i)−x(i)∣∣2
= ∑ i = 1 m ∣ ∣ W z ( i ) − x ( i ) ∣ ∣ 2 = \sum_{i=1}^{m} ||Wz^{(i)} - x^{(i)}||^2 =∑i=1m∣∣Wz(i)−x(i)∣∣2
= ∑ i = 1 m ( W z ( i ) ) T ( W z ( i ) ) − 2 ∑ i = 1 m ( W z ( i ) ) T x ( i ) + ∑ i = 1 m x ( i ) T x ( i ) =\sum_{i=1}^{m}(Wz^{(i)})^T(Wz^{(i)} ) - 2\sum_{i=1}^{m}(Wz^{(i)})^Tx^{(i)} + \sum_{i=1}^{m}x^{(i)T}x^{(i)} =∑i=1m(Wz(i))T(Wz(i))−2∑i=1m(Wz(i))Tx(i)+∑i=1mx(i)Tx(i)
= ∑ i = 1 m ( z ( i ) ) T ( z ( i ) ) − 2 ∑ i = 1 m z ( i ) T W T x ( i ) + ∑ i = 1 m x ( i ) T x ( i ) =\sum_{i=1}^{m}(z^{(i)})^T(z^{(i)}) - 2\sum_{i=1}^{m}z^{(i)T}W^Tx^{(i)} + \sum_{i=1}^{m}x^{(i)T}x^{(i)} =∑
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1240
1240

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









