










多模态大型语言模型(Multimodal Large Language Models, MLLM)的出现是建立在大型语言模型(Large Language Models, LLM)和大型视觉模型(Large Vision Models, LVM)领域不断突破的基础上的。随着 LLM 在语言理解和推理能力上的逐步增强,指令微调、上下文学习和思维链工具的应用愈加广泛。然而,尽管 LLM 在处理语言任务时表现出色,但在感知和理解图像等视觉信息方面仍然存在明显的短板。与此同时,LVM 在视觉任务(如图像分割和目标检测)上取得了显著进展,通过语言指令已能够引导模型执行这些任务,但推理能力仍有待提升。
💎MMLM 的基本结构
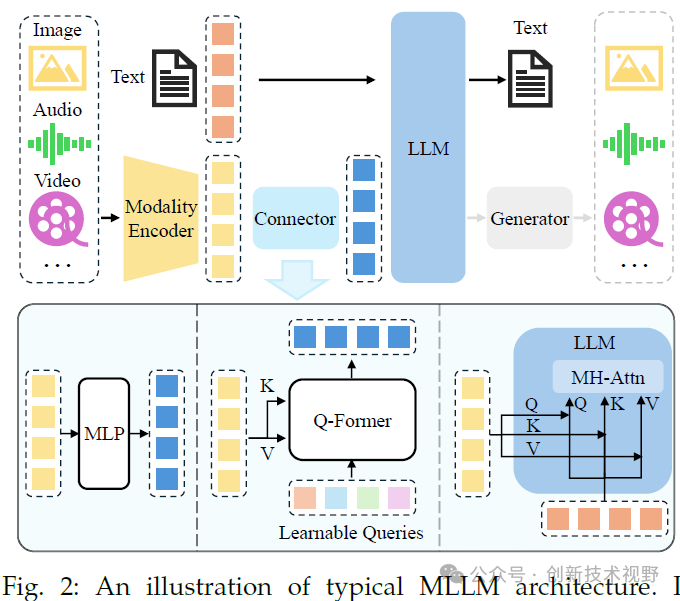
预训练的多模态编码器

1. 模态编码器的功能与选择
模态编码器在 MLLM 中承担着将原始的多模态信息(如图像或音频)转换为紧凑表示的关键角色。与从零开始训练编码器相比,常见的做法是采用已经预训练的编码器,尤其是那些在大规模图像-文本对上预训练过的模型。例如,CLIP 的视觉编码器部分就是一个经典的选择,其能够将图像信息有效转化为向量表示,并与文本信息对齐。不同的模型在编码器的选择和优化上各有侧重。
EVA-CLIP 编码器
MiniGPT-4 采用了 EVA-CLIP 编码器,这种编码器在性能上优于标准的 CLIP,同时所需的训练成本更低。这主要归功于以下三个改进:首先,EVA-CLIP 通过使用 EVA 模型的预训练权重来初始化图像编码器,从而提升了起始性能;其次,使用了 LAMB 优化器,这种优化器特别适用于大批量训练,能够通过自适应元素级更新和层级学习率来提高训练效率并加速模型的收敛;最后,采用了 FLIP 技术,在训练过程中随机遮蔽 50%的图像标记,从而大幅度减少了时间复杂度,使得批量大小可以增加一倍而无需额外的内存开销。
此外,EVA 模型还通过一种名为 Mask Image Modeling 的任务在更大数据集上进行了训练,它将遮蔽部分的图像与 CLIP 模型对应位置的输出进行比对,从而在保持语义学习的同时,也能让模型学习到几何结构。EVA 的这种训练方式证明了其能够有效扩展模型参数至十亿量级,并在广泛的下游任务中展现出色的性能。
基于卷积的 ConvNext-L 编码器
Osprey 选择了基于卷积的 ConvNext-L 编码器,这种编码器能够利用更高分辨率和多层次特征,特别是在开放词汇分割任务中展现了较高的效率。在原文中提到,Osprey 是基于像素级别的任务,如果直接使用 ViT 模型作为编码器,会受到计算负担的限制,图片大小通常只支持 224 或 336。而基于 CNN 的编码器能够在支持高分辨率的同时保持较高的训练效率和推理速度,而不会牺牲性能。
无编码器的架构
Fuyu-8b 就是采用了纯解码器转换器,图像块被线性投影到转换器的第一层,绕过了嵌入查找的过程,将普通 Transformer 解码器视为图像转换器。这样的设计使得 Fuyu-8b 对灵活输入的分辨率具有强大的适应性。
2.模态编码器的优化策略
在选择多模态编码器时,研究人员通常会考虑分辨率、参数规模和预训练语料库等因素。研究表明,使用更高分辨率的图像输入能够显著提升模型的表现。为了实现这一点,不同的模型采用了多种策略来优化编码器。
直接缩放输入分辨率
Qwen-VL 和 LLaVA-1.5 都通过将图像分割成更小的图像块来提高模型的输入分辨率。具体而言,LLaVA-1.5 使用了 CLIPViT-L-336px 编码器,并发现高分辨率能够提升模型性能。为了进一步优化,该模型将图像分割成视觉编码器原本训练时分辨率的小图像块,并分别对其进行编码,然后将这些特征图组合成一个大特征图,最终输入到 LLM 中。这种方式不仅保留了高分辨率的细节,还通过降采样图像的特征与合并后的特征图相结合,提供了全局上下文,从而提高了模型对任意分辨率输入的适应性。
CogAgent 采取了双编码器机制来处理高分辨率和低分辨率图像。高分辨率特征通过交叉注意力注入到低分辨率分支中,从而在保证效率的同时,增强了模型对高分辨率输入的支持。CogAgent 允许输入 1120×1120 分辨率的图像,而不需要对视觉语言模型的其他部分做出调整,只需对高分辨率交叉模块进行预训练即可。这种方法在 DOC-VQA 和 TEXT-VQA 等任务中显著超越了 LLAVA-1.5 和 Qwen-VL,特别是在处理小文字时表现出色。
分块法
Monkey 和 SPHINX 将大图像分割成小块,再将这些子图像与降采样的高分辨率图像一起输入图像编码器。Monkey 支持 1344×896 的分辨率输入,通过将大图像分为 6 个 448×448 的图片块,再输入到 VIT 模型中。相比之下,SPHINX 使用混合视觉编码器将高分辨率的图片分块,并与低分辨率全图一起进行编码,从而捕获图像的局部和全局特征。
预训练的 LLM

大多数多模态大型语言模型(MLLMs)中的语言模型部分通常采用 Causal Decoder 架构,遵循如 GPT-3 这样的设计模式。Flan-T5 系列是较早应用于 MLLM 的 LLMs 之一,曾在 BLIP-2 和 InstructBLIP 等工作中使用。开源的 LLaMA 系列和 Vicuna 系列则是当前较为常用的 LLMs。在中文环境中,Qwen 系列以其中英双语支持而著称,广泛应用于多语言场景。
扩大 LLMs 的参数规模通常能够带来显著的性能提升。这种效果在 LLaVa-1.5 和 LLava-Next 的研究中得到了验证:仅仅将 LLM 的参数规模从 7B 增加到 13B,模型在多个基准测试中就获得了全面改进。当 LLM 的参数规模达到 34B 时,尽管训练数据主要为英语多模态数据,模型仍然展现出新兴的零样本中文能力,这表明参数规模的扩大能够增强模型的多语言处理能力。
与此同时,一些研究也致力于开发轻量化的 LLMs,以便在移动设备上实现高效部署。例如,MobileVLM 系列使用了缩小版的 LLaMA(MobileLLaMA 1.4B/2.7B),在移动处理器上实现了高效推理。
最近,混合专家(Mixture of Experts,MoE)架构的研究引起了越来越多的关注。与密集模型不同,稀疏架构通过选择性激活参数,能够在不增加计算成本的情况下扩大模型的总参数规模。实验证明,MM1 和 MoE-LLaVA 在几乎所有基准测试中都比对应的密集模型取得了更优异的性能,这表明 MoE 架构在多模态任务中具有显著的潜力。
模态接口
由于多模态模型的端到端训练难度和成本较高,目前大多数模型都采用了基于模态对齐的两种常用方法:一是构造可学习的连接器(Learnable Connector),二是利用专家模型将图像信息转换为语言形式,再输入到 LLM 中。这两种方法都旨在缩小不同模态之间的差距,使得模型能够更好地理解和处理多模态输入。
模态对齐的方法有很多种,下面总结常见的 3 种:
Token 级融合
通过将编码器输出的特征转换为 token,并在发送给 LLM 之前与文本 token 连接在一起。例如,BLIP-2 首次实现了这种基于查询的 token 提取方式,随后 Vedio-llama、InstructBLIP 和 X-llm 等模型继承了这一方法。这种 Q-Former 风格的方法将视觉 token 压缩成更少数量的表示向量,从而简化了信息的传递和处理过程。
相比之下,另一种更简单的方法是通过 MLP 接口来弥合模态差距。例如,LLaVA、PMC-VQA(用于医学图像问答)、Pandagpt 和 Detgpt 等模型采用了一个或两个线性 MLP 来投影视觉 token,并使其特征维度与词嵌入对齐。这种方法虽然简单,但在特定任务上仍能表现出色。
特征级融合
特征级融合则在文本和视觉特征之间引入了更深度的交互。例如,Flamingo 通过在 LLM 的 Transformer 层之间插入额外的交叉注意力层,从而用外部视觉线索增强语言特征。类似地,CogVLM 通过在每个 Transformer 层中插入视觉专家模块,实现了视觉和语言特征的双向交互与融合。
有关连接器设计的研究表明,token 级融合中,模态适配器的类型不如视觉 token 的数量和输入分辨率重要。在视觉问答(VQA)任务中,token 级融合通常表现优于特征级融合。尽管交叉注意力模型可能需要更复杂的超参数搜索过程才能达到相似的性能,但 token 级融合的简洁性和高效性使其成为许多 MLLM 模型的首选。
就参数规模而言,可学习接口通常只占 MLLM 总参数中的一小部分。以 Qwen-VL 为例,其 Q-Former 模块的参数规模约为 0.08B,仅占总参数的不到 1%,而编码器和 LLM 分别占 19.8%(1.9B)和 80.2%(7.7B)。因此,尽管这些接口模块较小,但它们在模态对齐和特征融合中扮演了至关重要的角色。
使用专家模型(Expert Models)融合
在多模态模型中,专家模型被广泛应用于模态对齐的任务中,特别是当需要将图像或其他非语言模态的输入转换为语言形式时。这类方法的核心思想是利用现有的强大模型进行模态转换,从而避免重新训练一个复杂的多模态对齐模块。
例如,Woodpecker、ChatCaptioner、Caption Anything 和 Img2LLM 等模型都依赖于专家模型来完成从图像到语言的转换。这些模型通常通过预训练的图像描述生成器,如 BLIP-2,将视觉输入转换为文本描述,再将其传递给 LLM 进行进一步的处理和生成。这种方法的优势在于可以快速集成和应用现有的模型能力,而不需要进行额外的训练或微调。
然而,尽管这种方法有效且简便,但在信息传递的过程中存在信息损失的风险。这是因为每次转换都会不可避免地丢失部分细节和上下文,导致最终生成的结果可能偏离原始的多模态输入。未来的研究方向很可能会集中在如何减少这种信息损失,特别是在提高模态对齐的精度和可靠性方面。
举例来说,VideoChat-Text 使用了一个预训练的视觉模型来获取图像中的信息(如动作),然后通过一个语音识别模型丰富对图像的描述。这种方法虽然能够快速实现多模态的对齐,但在多次转换和传递过程中,信息的精确度可能会受到影响。因此,尽管专家模型的方法在当前阶段非常有效,但在高精度和高复杂度任务中,仍然有改进的空间。
📝MMLM 的训练策略和训练数据
在多模态大型语言模型(MLLMs)的开发过程中,训练策略和数据处理方法对于模型的性能提升至关重要。通常,训练分为三个主要阶段:预训练,指令微调和对齐微调。
1. 预训练
预训练的主要目标是对齐不同模态,同时让模型学习多模态世界中的丰富知识。这个阶段通常需要大规模的文本配对数据(如图像-文本对、音频-文本对),这些数据能够为模型提供广泛的上下文和世界知识。在预训练过程中,常见的输入格式是将一段描述性文本与对应的图像、音频或视频配对,通过交叉熵损失函数进行训练。这种方式确保了模型能够在不同模态之间建立有效的关联。
预训练的方法通常有两种:一种是冻结 LLMs 和视觉编码器,只训练模态接口,这样可以保留模型已有的预训练知识,代表性的模型有 LLaVA、LLaVA-med 和 Detgpt;另一种是开放视觉编码器的参数,在对齐过程中有更多的参数可以进行微调训练,这类方法通常在需要更精确对齐的任务中使用,代表性模型有 Qwen-VL、mPLUG-Owl 和 VisionLLM。
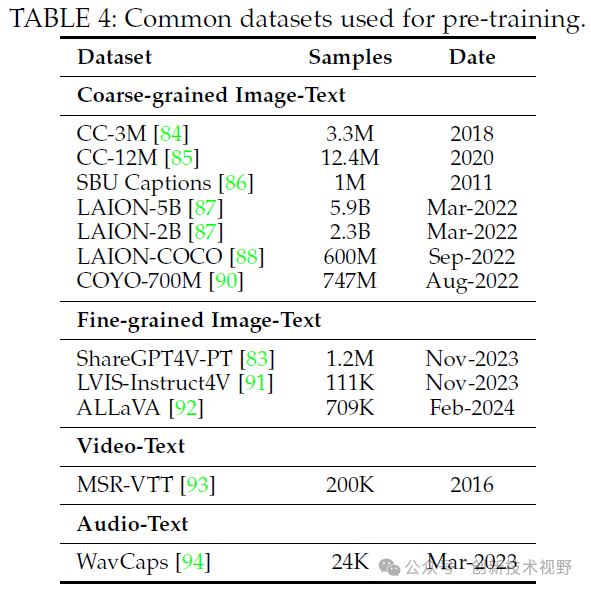
对于训练数据的处理,不同数据集的质量直接影响到模型的训练效果。低质量的数据集(如噪声较大的、简短的描述)通常使用低分辨率(如 224)的图像进行训练,以加快模型的训练进程;而高质量的数据集(如较长且干净的描述)则推荐使用高分辨率(如 448 或以上)的图像进行训练,以减少“幻觉”现象,即模型生成与实际输入不符的内容。例如,ShareGPT4V 的研究发现,在预训练阶段使用高质量的图像标题数据,并且解锁视觉编码器的参数,能够显著提高模型对齐的效果。
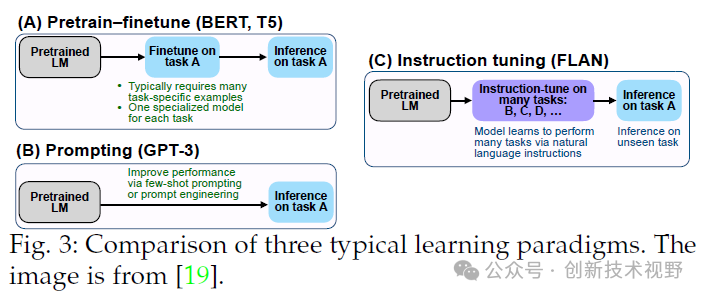
2. 指令微调(Instruction-tuning)
指令微调是训练 MLLMs 的另一关键阶段,其目的是让模型更好地理解和执行用户的指令。在这一阶段,模型通过学习如何泛化到未见过的任务,从而提升零样本的性能。与传统的监督微调相比,指令微调更加灵活,能够通过适应多任务提示来提高模型的广泛应用能力。这种训练策略在自然语言处理领域已经取得了成功,推动了如 ChatGPT、InstructGPT 等模型的发展。
2.1 指令微调的数据格式:
多模态指令样本通常包括一个可选的指令和一个输入-输出对。指令通常是一个描述任务的自然语言句子,例如:“详细描述这张图像”。输出是基于输入条件下对指令的回答。指令模板是灵活的,并且取决于人工设计。需要注意的是,指令模板也可以推广到多轮对话的情况。

2.2 指令微调的数据收集方式:
数据收集是训练多模态大型语言模型(MLLMs)过程中至关重要的一环,特别是在指令微调阶段。由于指令数据的格式多样化且任务描述复杂,收集这些数据样本通常更具挑战性且成本较高。目前,主要有三种方法用于大规模获取指令数据集。
数据适配(Data Adaptation)
这种方法利用现有的高质量任务特定数据集,并将其转换为指令格式的数据集。例如,对于 VQA(视觉问答)类数据集,可以将原始格式(图像+问题→答案)转换为指令格式(指令+图像+问题→答案)。许多工作,如 MiniGPT-4、LLaVA-med、InstructBLIP、X-LLM、Multi-instruct 和 M3it,都是通过这种方式来生成多模态指令数据集。具体而言,这些工作通常手动制作一个候选指令池,然后在训练时从中采样指令,以适应不同的任务需求。
自我指令(Self-Instruction)
这种方法通过利用大型语言模型(LLMs)生成指令数据,以应对实际场景中的人类需求。例如,LLaVA 采用自我指令方法,将图像转换为文本描述和边界框信息,然后通过纯文本的 GPT-4 生成新的指令数据,最终构建出一个名为 LLaVA-Instruct-150k 的多模态指令数据集。这种方法有效扩展了模型的指令理解能力,后续如 MiniGPT-4、ChatBridge、GPT4Tools 和 DetGPT 等工作也基于这一思路开发了适用于不同需求的指令数据集。
数据混合(Data Mixture)
除了多模态指令数据之外,一些研究还将纯语言的用户助手对话数据整合到训练过程中,以提升模型的对话能力和指令遵循能力。例如,mPLUG-Owl、Multimodal-gpt 和 LaVIN 直接通过从纯语言和多模态数据中随机采样来构建小批量数据集(minibatch)。MultiInstruct 则探索了单模态和多模态数据融合的不同策略,包括混合指令调优(结合两种类型的数据并随机打乱)和顺序指令调优(先使用文本数据,然后是多模态数据),从而提高了模型的综合表现。
2.3 数据质量
数据质量对于模型的训练效果也有显著影响。研究表明,在一个高质量的小型微调指令集上进行训练,往往比在一个大规模噪声数据集上进行训练效果更好。例如,在 Lynx 的研究中发现,高质量的数据集应包含丰富多样的提示,并涉及更多的推理任务,以充分发挥模型的潜力。
3. 对齐微调
为了提高多模态大型语言模型(MLLMs)在特定场景下的表现,对齐微调(Alignment Tuning)是一项不可忽视的关键步骤。对齐微调的目标是减少模型在生成过程中可能出现的“幻觉”现象,确保生成内容与输入信息保持一致。
在对齐微调中,**强化学习与人类反馈(RLHF)和直接偏好优化(DPO)**是两种常见的方法。
强化学习与人类反馈(RLHF)
RLHF 是一种通过强化学习算法使模型与人类偏好保持一致的技术,它通过监督微调、奖励建模和强化学习三个步骤完成模型的训练。例如,InstructGPT 在 RLHF 框架下,通过人类标注数据进行监督微调,并在训练过程中利用 PPO(Proximal Policy Optimization)算法优化模型的响应质量。
直接偏好优化(DPO)
DPO 则通过使用简单的二元分类损失从人类偏好标签中学习,简化了传统 RLHF 的流程,不需要显式的奖励模型,从而将整个对齐微调过程简化为人类偏好数据收集和偏好学习两个步骤。
在偏好学习中,模型需要基于给定的多个选项,判断哪个选项更受偏好,或者对选项进行偏好排序。通过这种方法,模型能够逐步优化其参数,使其生成的内容更符合人类的预期。这种学习方式不仅在任务中取得了良好的效果,还在应对复杂场景时表现出色。
除了 RLHF 和 DPO,RLHF-V 和 Silkie 也引入了新的技术,通过纠正模型中的幻觉来收集更细粒度的偏好数据。RLHF-V 通过段落级别的幻觉纠正来生成偏好数据对,而 Silkie 则利用 GPT-4V 来收集偏好数据,并通过 DPO 将这些偏好蒸馏到经过指令微调的模型中,从而进一步提高了模型的对齐效果。
对齐微调的数据收集
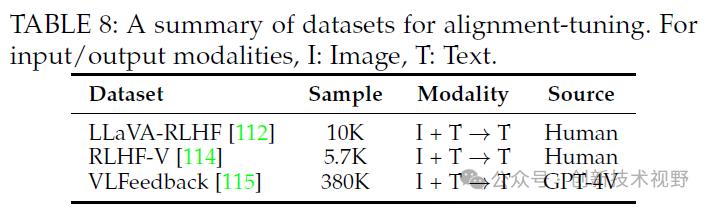
在对齐微调的数据集方面,LLaVA-RLHF 通过人类反馈收集了 10,000 对偏好数据,主要关注模型响应的诚实性和有用性。RLHF-V 收集了 5,700 条细粒度的人类反馈数据,特别是针对段落级别的幻觉进行纠正。VLFeedback 则利用 AI 来为模型的响应提供反馈,包含超过 380,000 对比较数据,这些对比是由 GPT-4V 根据有用性、忠实度和伦理问题进行评分的。
📏MMLM 的性能评估方法
在多模态大型语言模型(MLLMs)的开发过程中,评估模型性能是确保其应用效果的重要步骤。与传统的多模态模型评估方法相比,MLLMs 的评估具有一些新的特征,主要体现在对模型多功能性的全面评估以及对新兴能力的特别关注。
封闭式问题的评估通常针对特定任务数据集进行,评估设置可以分为零样本设置和微调设置两种。在零样本设置中,研究者选择涵盖不同任务的数据集,将其分为保留集(held-in)和留出集(held-out),在前者上进行调整后,在后者上评估模型的零样本性能。微调设置则常见于特定领域的任务评估,例如 LLaVA 和 LLaMA-Adapter 在 ScienceQA 上的微调表现,LLaVA-Med 在生物医学 VQA 上的性能等。
为了解决这些方法在少数选定任务或数据集上的局限性,研究者们开发了专门为 MLLMs 设计的新基准。例如,MME 是一个包括 14 个感知和认知任务的综合评估基准,而 MMBench 则通过使用 ChatGPT 将开放式响应与预定义选项进行匹配。对于视频领域的应用,Video-ChatGPT 和 Video-Bench 提供了专注于视频任务的专门基准和评估工具。
开放式问题的评估更为灵活,通常涉及 MLLMs 在聊天机器人角色中的表现。由于开放式问题的回答可以是任意的,评判标准通常分为人工评分、GPT 评分和案例研究三类。
-
人工评分 需要人类评估生成的回答,通常通过手工设计的问题来评估特定方面的能力。例如,mPLUG-Owl 收集了一个视觉相关的评估集,用于判断模型在自然图像理解、图表和流程图理解等方面的能力。
-
GPT 评分 则探索了使用 GPT 模型进行自动评分的方法。这种方法通过让 GPT-4 从不同维度(如有用性和准确性)对模型生成的回答进行评分。例如,LLaVA 的评分方法使用 GPT-4 对不同模型生成的答案进行比较,并通过 COCO 验证集中抽样的问题进行评估。
-
案例研究 作为补充评估方法,通过具体案例比较 MLLMs 的不同能力。研究者们通常选择两个或多个高级商用模型进行对比,分析它们在复杂任务中的表现。例如,Yang 等人对 GPT-4V 进行了深入分析,涵盖了从基础技能(如描述和物体计数)到需要世界知识和推理的复杂任务(如理解笑话和室内导航)的评估。
🔨能力扩展
能力扩展 是 MLLMs 研究中的一个重要方向。为了更好地与用户交互,研究者开发了支持更精细粒度控制的模型,从 Image 演变到 Region 级别(如 Shikra、GPT4ROI、Pink),甚至像素级别(如 Osprey、Glamm、Ferret)的输入和输出支持。例如,Shikra 支持用户通过引用图像的特定区域(以边界框表示)进行交互,而 Osprey 则利用分割模型 SAM 支持点输入,实现了对单个实体或其部分的精确定位。
此外,MLLMs 正在被扩展以支持更多的模态输入和输出。例如,ImageBind-LLM 支持编码图像、文本、音频、深度图、热成像和惯性测量单元(IMU)数据,而 Next-gpt 和 Emu 等模型则可以生成多模态响应,如图像、语音和音频。
😵MMLM 的幻觉问题及其缓解方法
在多模态大型语言模型(MLLMs)的生成过程中,幻觉问题(即模型生成的内容与实际输入不符的现象)是一个亟需解决的挑战。幻觉问题主要包括三种类型:存在性幻觉(模型错误地声称图片中存在某些对象)、属性幻觉(模型错误描述对象的某种属性)以及关系幻觉(模型错误描述对象之间的关系,如位置或动作)。这些问题对 MLLMs 的输出质量和可信度造成了严重影响,因此,研究者们提出了多种缓解幻觉的方法。
1. 幻觉评估方法
传统的评估方法,如 BLEU、METEOR、TF-IDF 等,主要基于生成内容与参考描述的相似度,但在处理幻觉问题时显得力不从心。为了更准确地评估幻觉现象,新一类的评估指标应运而生。
CHAIR(Caption Hallucination Assessment with Image Relevance)是一种早期的评估开放式图像描述中幻觉程度的指标,它通过测量句子中包含幻觉对象的比例来判断模型的准确性。
POPE 通过构建多个二元选择的提示,询问图像中是否存在特定对象,以评估模型的鲁棒性。MME 则提供了更全面的评估,涵盖了存在性、数量、位置和颜色等方面的幻觉评估。HaELM 提出了使用纯文本大语言模型(LLMs)作为判断者,自动决定 MLLMs 生成的描述是否与参考描述相符
FaithScore 基于将描述性子句分解并单独评估每个子句的准确性,从而以更细粒度的方式评估生成内容。
2. 幻觉缓解方法
幻觉缓解方法分为预校正、过程中校正和后校正三种策略。
预校正:通过收集专门设计的数据集(包括负面数据)并对模型进行微调,以减少幻觉的产生。例如,LRV-Instruction 引入了一个视觉指令调优数据集,除了常见的正面指令外,还包括不同语义层面的负面指令,以此来鼓励模型生成与图像内容更一致的回应。
过程中校正:这类方法希望通过分析和控制幻觉产生的原因,在生成过程中进行校正。例如,HallE-Switch 通过对比原始视觉输入与扭曲视觉输入的输出分布,来减少模型对统计偏差和语言先验的过度依赖,从而降低幻觉发生的可能性。VCD 则通过设计放大然后对比的解码方案,确保生成内容与视觉输入紧密结合,显著减轻了模型中的幻觉问题。
后校正:这种方法在输出生成后对幻觉进行纠正。Woodpecker 是一个无需训练的通用幻觉校正框架,通过结合专家模型补充图像的上下文信息,逐步纠正生成内容中的幻觉。LURE 则训练了一个专门的校正器,通过遮蔽描述中不确定性高的对象,重新生成更准确的响应。
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
四、AI大模型商业化落地方案

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 6437
6437

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









