






Ibis可以用统一的接口,来基于不同的底层实现来操纵数据。
包括各种 DataFrame实现(如 pandas, polars, dask) 和SQL实现(如pyspark, duckdb, sqlite, postgres)。
从一定意义上说,掌握了ibis就相当于同时掌握了 duckdb, polars, dask, pyspark,各种数据分析和转换问题通通拿下。
公众号算法美食屋后台回复关键词:源码,获取本文notebook完整源代码。
本文我们将按照如下结构演示讲解Ibis的使用方法。
大概30分钟的时间帮助你快速入门Ibis这个强大的数据操纵和分析工具。
⚫️ 安装方法
⚫️ 读取数据
⚫️ 分析数据
⚫️ 保存数据
⚫️ 8道练习题
〇,安装方法
下面我们安装支持duckdb后端和pandas后端(默认都支持)的ibis库。
支持不同的后端需要在中括号里写不同的名字。
#!pip install 'ibis-framework[duckdb]'import ibis
import numpy as np
import pandas as pd
#Ibis默认是Lazy模式的,只有有action才会触发执行。设置此行变成立即执行。
ibis.options.interactive = True
con = ibis.duckdb.connect() #使用duckdb后端
#con = ibis.polars.connect() #使用polars后端
#con = ibis.pandas.connect() #使用pandas后端一,读取数据
%%time
df = pd.read_parquet('dfdemo.parquet')CPU times: user 1.09 s, sys: 163 ms, total: 1.26 s
Wall time: 753 ms%%time
tb = con.read_parquet('dfdemo.parquet',table_name='tb')CPU times: user 4.76 ms, sys: 3.11 ms, total: 7.87 ms
Wall time: 6.93 mscon.list_tables()['tb']二,分析数据
1,where查询
%%time
df.loc[(df['val']>1000)&(df['val']<10000),:].sort_values('val').head(5)CPU times: user 122 ms, sys: 51.1 ms, total: 174 ms
Wall time: 173 ms我们分别试试SQL模式和DataFrame模式
%%time
#SQL模式
tb2 = con.sql('select * from tb where val>1000 and val<10000 order by val limit 5'
)CPU times: user 3.56 ms, sys: 3.73 ms, total: 7.29 ms
Wall time: 5.43 mscon.drop_table('tb2',force=True)
con.create_table('tb2',tb2)
con.list_tables()['tb', 'tb2']%%time
#DataFrame模式
tb3 = (tb.filter([tb.val>1000,tb.val<10000])
.order_by(ibis.asc("val"))
.head(5))
tb3CPU times: user 2.99 ms, sys: 56 µs, total: 3.04 ms
Wall time: 3.18 ms
2,groupby分组聚合
%%time
df.groupby('category').agg({'val':['count','mean']})CPU times: user 1.42 s, sys: 142 ms, total: 1.56 s
Wall time: 1.59 s%%time
# SQL模式
tb4 = con.sql(
'select category, count(val) as rows, mean(val) as avg_val from tb group by category'
)
tb4CPU times: user 5.15 ms, sys: 4.52 ms, total: 9.67 ms
Wall time: 6.02 ms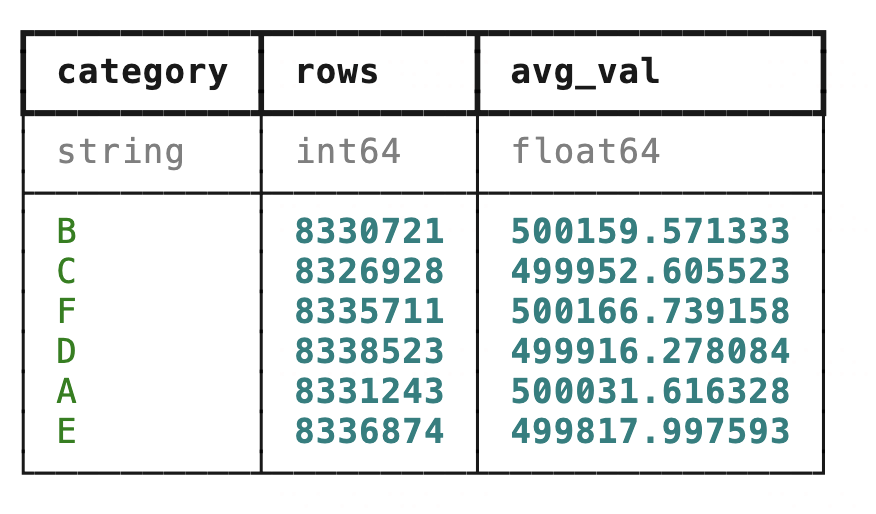
%%time
# DataFrame模式
tb5 = (tb.group_by(tb.category)
.agg(rows=tb.val.count(),avg_val=tb.val.mean())
)
tb5CPU times: user 4.93 ms, sys: 1.47 ms, total: 6.41 ms
Wall time: 6.67 ms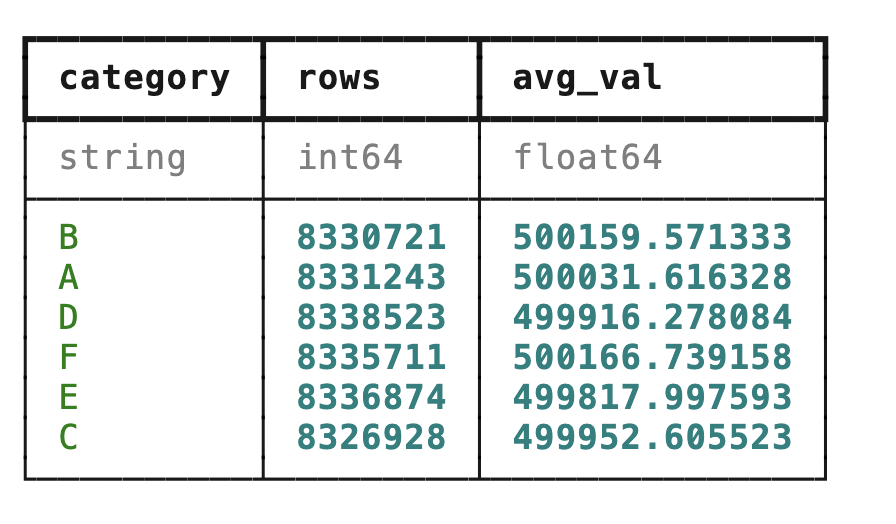
3,join表格连接
dfcolor = pd.read_parquet('dfcolor.parquet')%%time
dfjoin = df.merge(dfcolor,left_on='category',right_on='cat')CPU times: user 3.3 s, sys: 793 ms, total: 4.09 s
Wall time: 4.49 stb_color = con.read_parquet('dfcolor.parquet',table_name='tb_color')
con.list_tables()%%time
# DataFrame模式
tbjoin = tb.join(tb_color,tb.category==tb_color.cat,how='left')
tbjoinCPU times: user 2.05 ms, sys: 428 µs, total: 2.48 ms
Wall time: 2.54 ms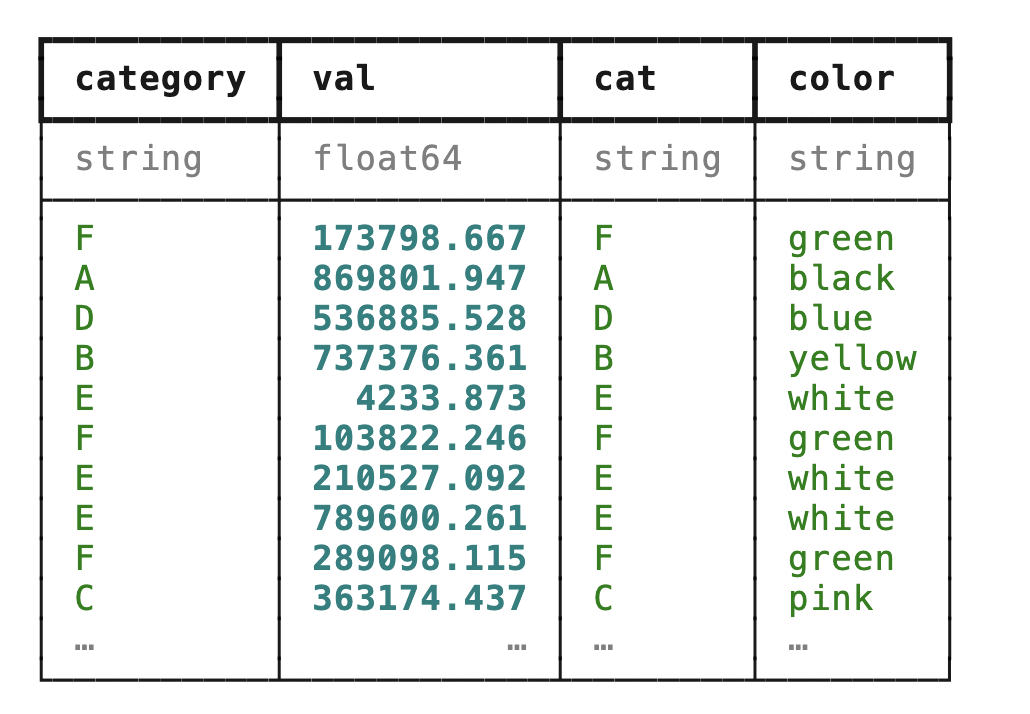
4,自定义函数
import duckdb
@ibis.udf.scalar.python
def random_name(i:int) -> str:
...
return name%%time
tb = ibis.memtable({'i':range(100)})
tb_students = tb.mutate(name = random_name(tb.i),
score = (100*ibis.random())).cast({'score':'int'})
tb_students
三,保存数据
tb_students.to_parquet('tb_students.parquet')四,8道练习题
1, 求平均数
#任务:求data的平均值
data = [1,5,7,10,23,20,6,5,10,7,10]2,求众数
#任务:求data中出现次数最多的数
data = [1,5,7,10,23,20,6,5,10,7,10]3,求topN
#任务:有一批学生信息表格,包括name,age,score, 找出score排名前3的学生, score相同可以任取
students = [("LiLei",18,87),("HanMeiMei",16,77),("DaChui",16,66),("Jim",18,77),("RuHua",18,50)]
n = 34,排序并返回序号
#任务:排序并返回序号, 大小相同的序号可以不同
data = [1,7,8,5,3,18,34,9,0,12,8]5,二次排序
#任务:有一批学生信息表格,包括name,age,score
#首先根据学生的score从大到小排序,如果score相同,根据age从大到小
students = [("LiLei",18,87),("HanMeiMei",16,77),("DaChui",16,66),("Jim",18,77),("RuHua",18,50)]6,连接操作
#任务:已知班级信息表和成绩表,找出班级平均分在75分以上的班级
#班级信息表包括class,name,成绩表包括name,score
classes = [("class1","LiLei"), ("class1","HanMeiMei"),("class2","DaChui"),("class2","RuHua")]
scores = [("LiLei",76),("HanMeiMei",80),("DaChui",70),("RuHua",60)]7,分组求众数
#任务:有一批学生信息表格,包括class和age。求每个班级学生年龄的众数。
students = [("class1",15),("class1",15),("class2",16),
("class2",16),("class1",17),("class2",19)]8,透视分析
#任务:已知成绩表,包含姓名,班级,性别,数学,物理,计算机 三科成绩。
#求每个班,男生和女生的平均分。
data = {'name':['Lily','Ann','Jim','Tom','LiLei','HanMeiMei'],
'class':[1,1,2,2,2,1],
'gender':['female','male','male','male','female','female'],
'math':[78,90,65,80,75,68],
'physics':[90,95,98,96,85,98],
'computer':[76,66,58,66,90,60]}公众号算法美食屋后台回复关键词:源码。
获取本文notebook完整源代码,以及使用ibis解决这8道练习题的参考答案。
万水千山总是情,点个在看行不行~😋😋


















 706
706

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









