






论文分享 | 大语言模型相关研究进展
我们从2024-12-17到2024-12-17的41篇文章中精选出5篇优秀的工作分享给读者。
-
Hybrid Preference Optimization for Alignment: Provably Faster Convergence Rates by Combining Offline Preferences with Online Exploration
-
Foundational Large Language Models for Materials Research
-
OP-LoRA: The Blessing of Dimensionality
-
VisDoM: Multi-Document QA with Visually Rich Elements Using Multimodal Retrieval-Augmented Generation
-
Intelligent System for Automated Molecular Patent Infringement Assessment
1.Hybrid Preference Optimization for Alignment: Provably Faster Convergence Rates by Combining Offline Preferences with Online Exploration
Authors: Avinandan Bose, Zhihan Xiong, Aadirupa Saha, Simon Shaolei Du, Maryam Fazel
https://arxiv.org/abs/2412.10616
论文摘要
Reinforcement Learning from Human Feedback (RLHF) is currently the most popular tool for language model alignment. Large Language Models typically have access to large offline datasets to train the models. However, the need to align language models for specific tasks means that these offline datasets are often insufficient to cover all the requirements of the specific reward model. Using a purely online algorithm to collect preference data can be expensive when the offline dataset with incomplete coverage can be leveraged. Inspired by the recent theoretical advances in Hybrid RL, in this paper, we initiate the study of Hybrid RLHF. We show that hybrid RLHF requires less stringent coverage conditions than pure offline RLHF, and still improves the sample complexity of the online exploration.
论文简评
在这篇关于混合偏好优化(Hybrid Preference Optimization)的研究中,作者提出了一种结合线下和在线强化学习的人工智能方法,以提高大型语言模型与人类偏好的匹配效率。该研究提供了理论保证和实证证据,证明HPO与纯粹的线下或线上方法相比,在增强样本效率方面具有显著优势。通过分析,我们了解到HPO能够有效利用两种学习方法的优势,并解决了RLHF中的重要挑战。此外,理论分析为理解混合学习方法提供了优化样本复杂度的上下文。最终,实验结果表明,HPO比传统RLHF方法更具优越性,显示出实际应用的可能性。总的来说,这篇论文展示了HPO方法的独特价值和潜力,对相关领域的发展具有重要意义。
2.Foundational Large Language Models for Materials Research
Authors: Vaibhav Mishra, Somaditya Singh, Dhruv Ahlawat, Mohd Zaki, Vaibhav Bihani, Hargun Singh Grover, Biswajit Mishra, Santiago Miret, Mausam, N. M. Anoop Krishnan
https://arxiv.org/abs/2412.09560
论文摘要
Materials discovery and development are critical for addressing global challenges in renewable energy, sustainability, and advanced technology. Yet, the exponential growth in materials science literature comprising vast amounts of textual data has created significant bottlenecks in knowledge extraction, synthesis, and scientific reasoning. Large Language Models (LLMs) offer unprecedented opportunities to accelerate materials research through automated analy sis and prediction. Still, their effective deployment requires domain-specific adaptation for language understanding and solving domain-relevant tasks. Here, we present LLaMat, a family of foundational models for materials science developed through continued pretraining of LLaMA models on an extensive corpus of materials literature and crystallographic data. Through systematic evaluation, we demonstrate that LLaMat excels in materials-specific natural language processing and structured information extraction while maintaining general linguistic capabilities. The specialized LLaMat-CIF variant demonstrates unprecedented capabilities in crystal structure generation, predicting stable crystals with high coverage across the periodic table. Intriguingly, despite LLaMA-3’s superior performance in com parison to LLaMA-2, we observe that LLaMat-2 demonstrates unexpectedly enhanced domain-specific performance across diverse materials science tasks, including structured information extraction from text and tables, more particularly in crystal structure generation— suggesting a potential “adaptation rigidity” in overtrained LLMs. Altogether, the present work demonstrates the effectiveness of domain adaptation towards the development of practi cally deployable LLM copilots for materials research. Beyond materials science, our findings reveal important considerations for domain adaptation of LLMs—model selection, training methodology, and domain-specific performance—that may influence the development of specialized scientific AI systems.
论文简评
《材料科学中基础模型LLaMat》这篇论文旨在通过持续预训练的语言模型LLaMA对大量材料文献和晶体学数据进行语料库建模,解决材料研究中的一个重要挑战——知识提取与合成。该论文系统评估了LLaMat在特定领域的自然语言处理和结构化信息抽取方面的优越性,同时在晶格结构生成方面取得了突破性进展。此外,文中还提出了“适应性刚度”这一概念,为理解和分析语言模型的领域适应性提供了新的视角。实验结果表明,LLaMat在材料研究中表现出显著优势,其研究成果有望推动材料科学的发展。总的来说,本文不仅深入探讨了材料科学领域的问题,也提供了一种新颖的研究方法,对提高材料科学的理解和应用具有重要意义。
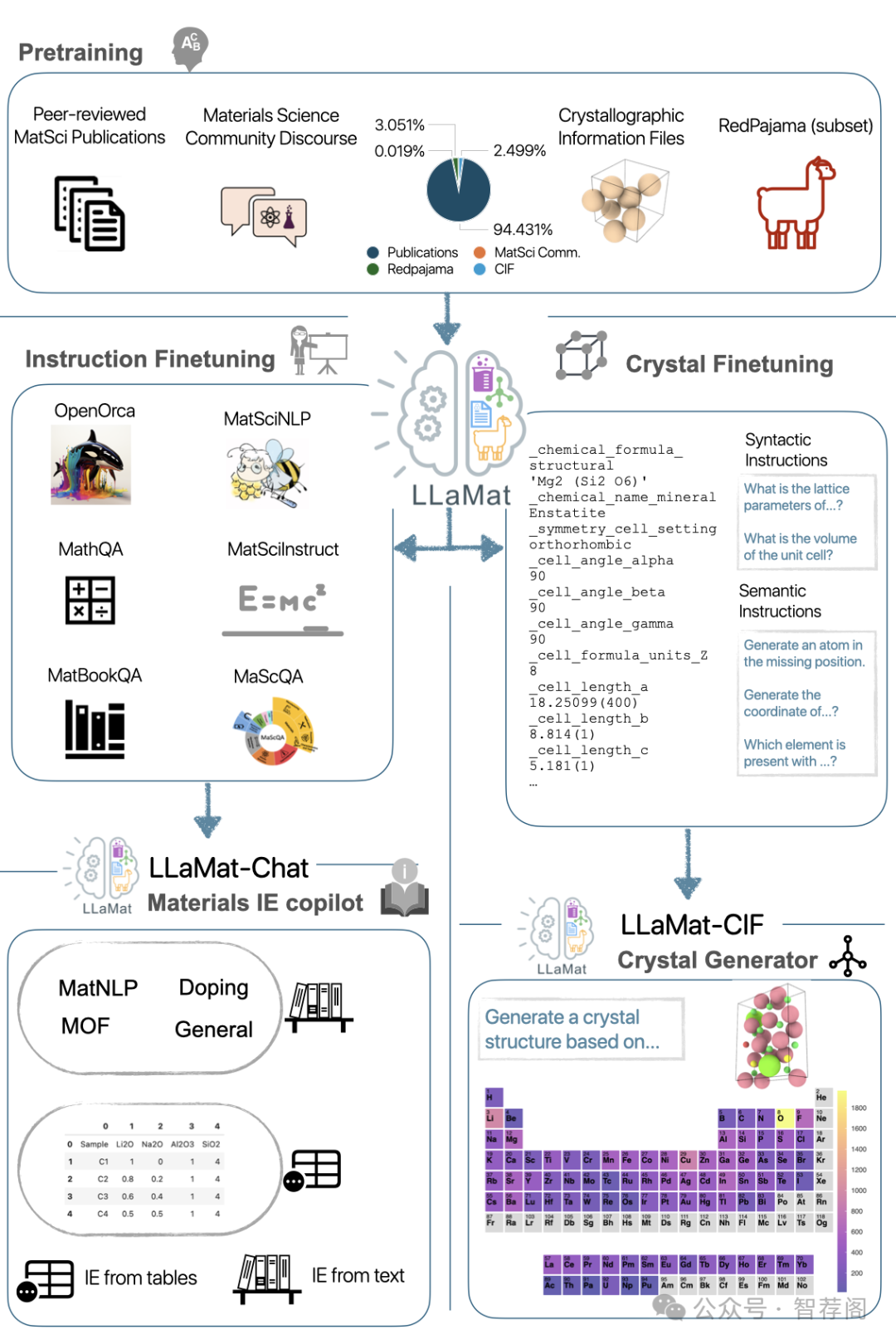
3.OP-LoRA: The Blessing of Dimensionality
Authors: Piotr Teterwak, Kate Saenko, Bryan A. Plummer, Ser-Nam Lim
https://arxiv.org/abs/2412.10362
论文摘要
Low-rank adapters enable fine-tuning of large models with only a small number of parameters, thus reducing storage costs and minimizing the risk of catastrophic forgetting. However, they often pose optimization challenges, with poor convergence. To overcome these challenges, we introduce an over-parameterized approach that accelerates training without increasing inference costs. This method reparameterizes low-rank adaptation by employing a separate MLP and learned embedding for each layer. The learned embedding is input to the MLP, which generates the adapter parameters. Such overparameterization has been shown to implicitly function as an adaptive learning rate and momentum, thus accelerating optimization. At inference time, the MLP can be discarded, leaving behind a standard low-rank adapter. To study the effect of MLP overparameterization on a small yet difficult proxy task, we implement it for matrix factorization, and find that it achieves faster convergence and lower final loss. Extending this approach to larger-scale tasks, we observe consistent performance gains across domains. We achieve improvements in vision-language tasks and especially notable increases in image generation, with CMMD scores improving by up to 15 points.
论文简评
这篇论文深入探讨了OP-LoRA方法——一种利用多层感知器(MLP)预测适配器参数以优化训练过程的方法。该方法旨在通过提高训练期间的收敛性来增强模型性能,同时保持推理效率。实验结果表明,在图像生成和视觉语言任务等不同领域中,该方法表现出显著优势。此外,文章还强调了创新使用MLPs来生成低秩参数的可能性,这一特点有望进一步改善模型的性能。综上所述,OP-LoRA方法不仅有效地解决了大型预训练模型在低秩适应中的优化挑战,而且其潜在的应用前景广阔。
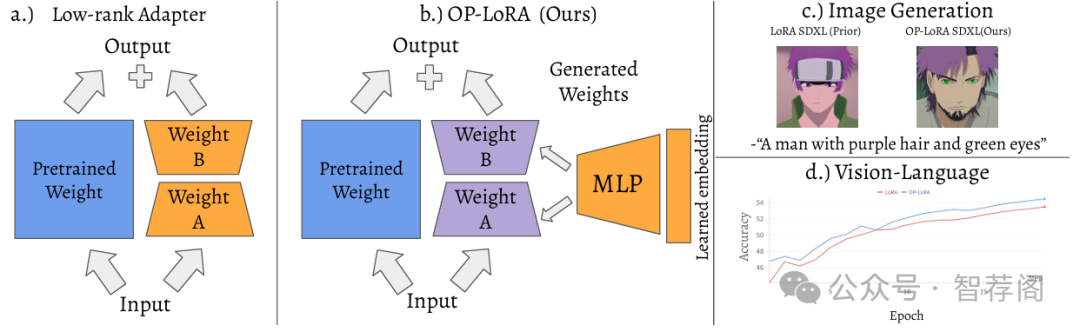
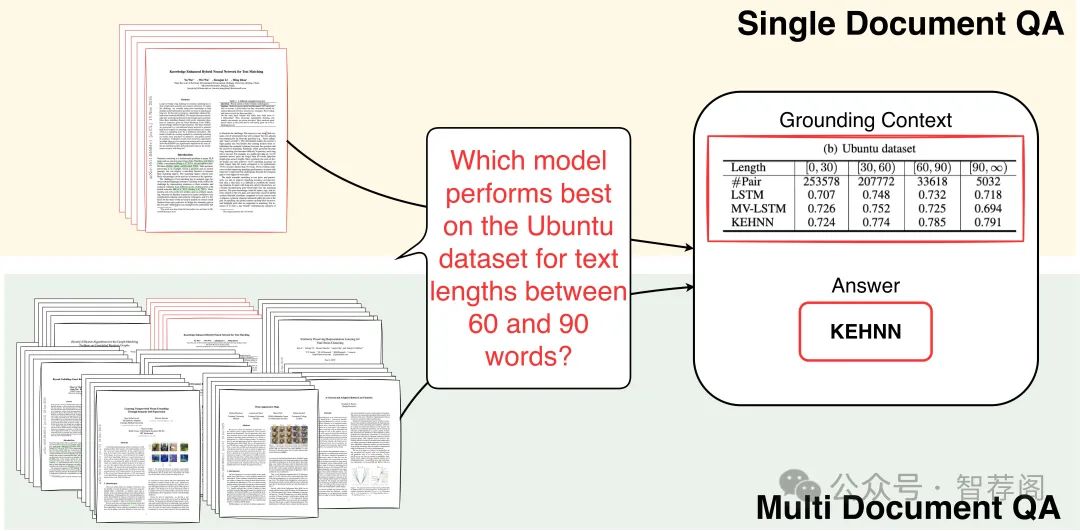
4.VisDoM: Multi-Document QA with Visually Rich Elements Using Multimodal Retrieval-Augmented Generation
Authors: Manan Suri, Puneet Mathur, Franck Dernoncourt, Kanika Goswami, Ryan A. Rossi, Dinesh Manocha
https://arxiv.org/abs/2412.10704
论文摘要
Understanding information from a collection of multiple documents, particularly those with vi Single Document QA Grounding Context sually rich elements, is important for document grounded question answering. This paper intro duces VisDoMBench, the first comprehensive benchmark designed to evaluate QA systems in multi-document settings with rich multimodal content, including tables, charts, and presen tation slides. We propose VisDoMRAG, a novel multimodal Retrieval Augmented Generation (RAG) approach that simultaneously utilizes visual and textual RAG, thereby combining ro bust visual retrieval capabilities with sophis ticated linguistic reasoning. VisDoMRAG em ploys a multi-step reasoning process encom passing evidence curation and chain-of-thought reasoning for concurrent textual and visual RAG pipelines. A key novelty of VisDoM RAG is its consistency-constrained modality fusion mechanism, which aligns the reasoning processes across modalities at inference time to produce a coherent final answer. This leads to enhanced accuracy in scenarios where crit ical information is distributed across modali ties and improved answer verifiability through implicit context attribution. Through exten sive experiments involving open-source and proprietary large language models, we bench mark state-of-the-art document QA methods on VisDoMBench. Extensive results show that VisDoMRAG outperforms unimodal and long context LLM baselines for end-to-end multi modal document QA by 12-20%.
论文简评
VisDoMBench作为多模态问题回答系统评估基准,弥补了现有评估中对包含视觉丰富元素的多模态问答系统的不足;而提出的VisDoMRAG方法则融合了文本与视觉两个模态,对于处理复杂问题具有显著提升作用。实验结果展示了该方法在性能上的改进,相较于当前主流QA方法具有显著优势。综上所述,VisDoMBench及VisDoMRAG是值得推荐的研究成果,它们为解决多模态问答任务提供了新的视角和解决方案。
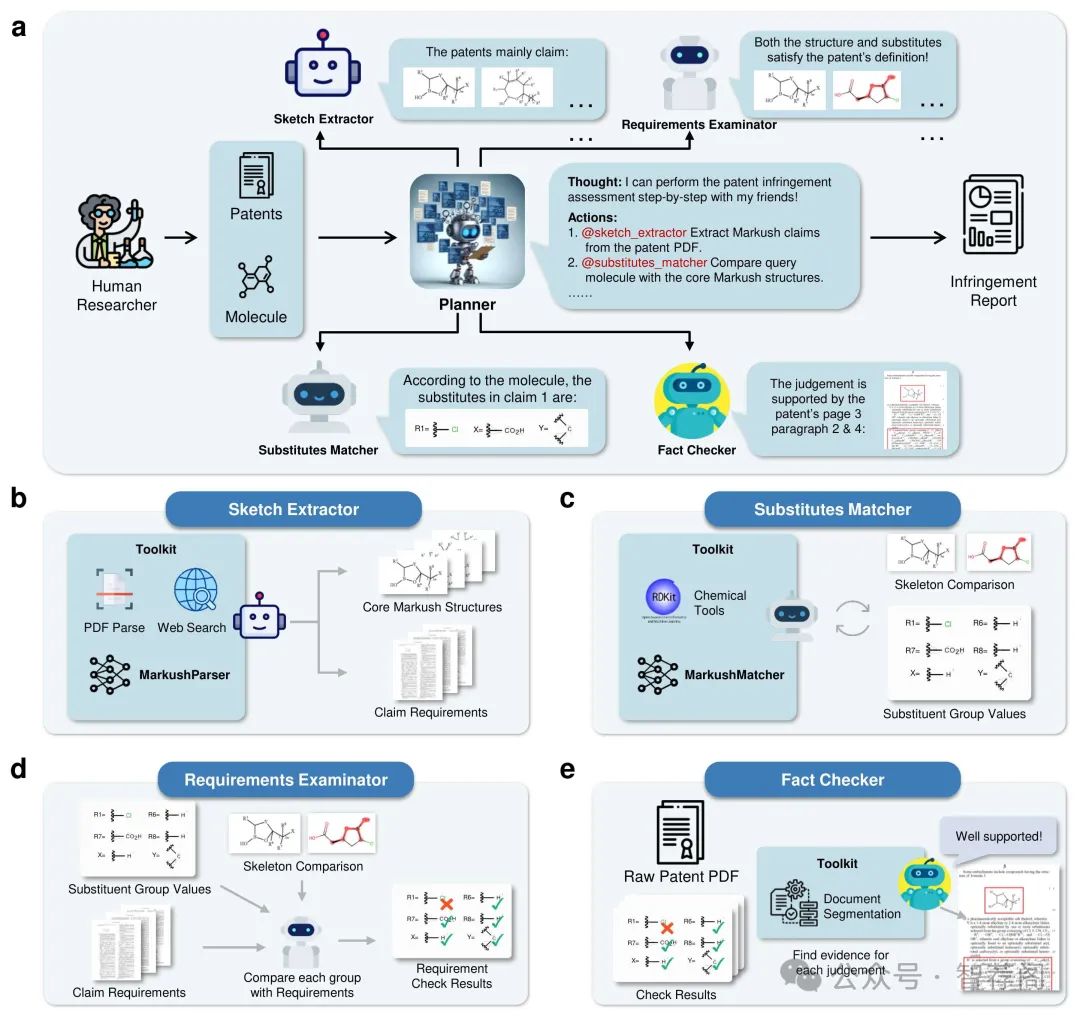
5.Intelligent System for Automated Molecular Patent Infringement Assessment
Authors: Yaorui Shi, Sihang Li, Taiyan Zhang, Xi Fang, Jiankun Wang, Zhiyuan Liu, Guojiang Zhao, Zhengdan Zhu, Zhifeng Gao, Renxin Zhong, Linfeng Zhang, Guolin Ke, Weinan E, Hengxing Cai, Xiang Wang
https://arxiv.org/abs/2412.07819
论文摘要
Automated drug discovery offers significant potential for accelerating the development of novel therapeutics by substituting labor-intensive human workflows with machine-driven processes. However, a critical bottleneck persists in the inability of current automated frameworks to assess whether newly designed molecules infringe upon existing patents, posing significant legal and financial risks. We introduce PatentFinder, a novel tool-enhanced and multi-agent framework that accurately and comprehensively evaluates small molecules for patent infringement. It incorporates both heuristic and model-based tools tailored for decomposed subtasks, featuring: MarkushParser, which is capable of optical chemical structure recognition of molecular and Markush structures, and MarkushMatcher, which enhances large language models’ ability to extract substituent groups from molecules accurately. On our benchmark dataset MolPatent-240, PatentFinder outperforms baseline approaches that rely solely on large language models, demonstrating a 13.8% increase in F1-score and a 12% rise in accuracy. Experimental results demonstrate that PatentFinder mitigates label bias to produce balanced predictions and autonomously generates detailed、interpretable patent infringement reports. This work not only addresses a pivotal challenge in automated drug discovery but also demonstrates the potential of decomposing complex scientific tasks into manageable subtasks for specialized、tool-augmented agents.
论文简评
该篇论文主要介绍了专利侵权评估框架——PatentFinder,它通过引入MarkushParser和MarkushMatcher模型分析小分子与现有专利之间的关系,从而改进了基于大规模语言模型的基础方法在MolPatent-240数据集上的表现。此外,论文还提出了一种多代理和工具增强的方法,使复杂任务被分解为易于管理的小型子任务,由专门的代理处理。这些创新性措施不仅解决了自动化药物发现中的一个重要挑战,而且在MolPatent-240数据集上展示了显著的实验结果,表现优于基准方法。综上所述,这篇论文在专利侵权评估领域提出了一个具有创新性的解决方案,其研究结果证明了这种方法的有效性和实用性。
如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


















 113
113

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









