






随着信息技术的快速发展,非结构化数据的管理和检索成为了一个重要议题。多模态检索技术结合了光学字符识别(OCR)、图像识别和文本抽取等技术,为文档的智能处理提供了新的可能性。本文将探讨多模态检索技术在智能文档处理中的应用,并分析思通数科大模型如何与这些技术相结合,以提高信息检索的效率和准确性。
引言
在数字化转型的浪潮中,企业和组织面临着海量非结构化数据的挑战。这些数据通常以PDF、PPT、CSV、PNG、SVG等格式存在,包含了丰富的文本、图像和多媒体信息。传统的检索方法难以高效地处理这些数据,而多模态检索技术的出现,为这一问题提供了解决方案。
多模态检索技术
多模态检索技术通过整合多种信息处理技术,实现了对非结构化数据的深度理解和智能检索。其中,OCR技术能够识别和转换文档中的文本信息,图像识别技术可以识别和分类文档中的图像内容,文本抽取技术则能够提取文档中的关键信息。
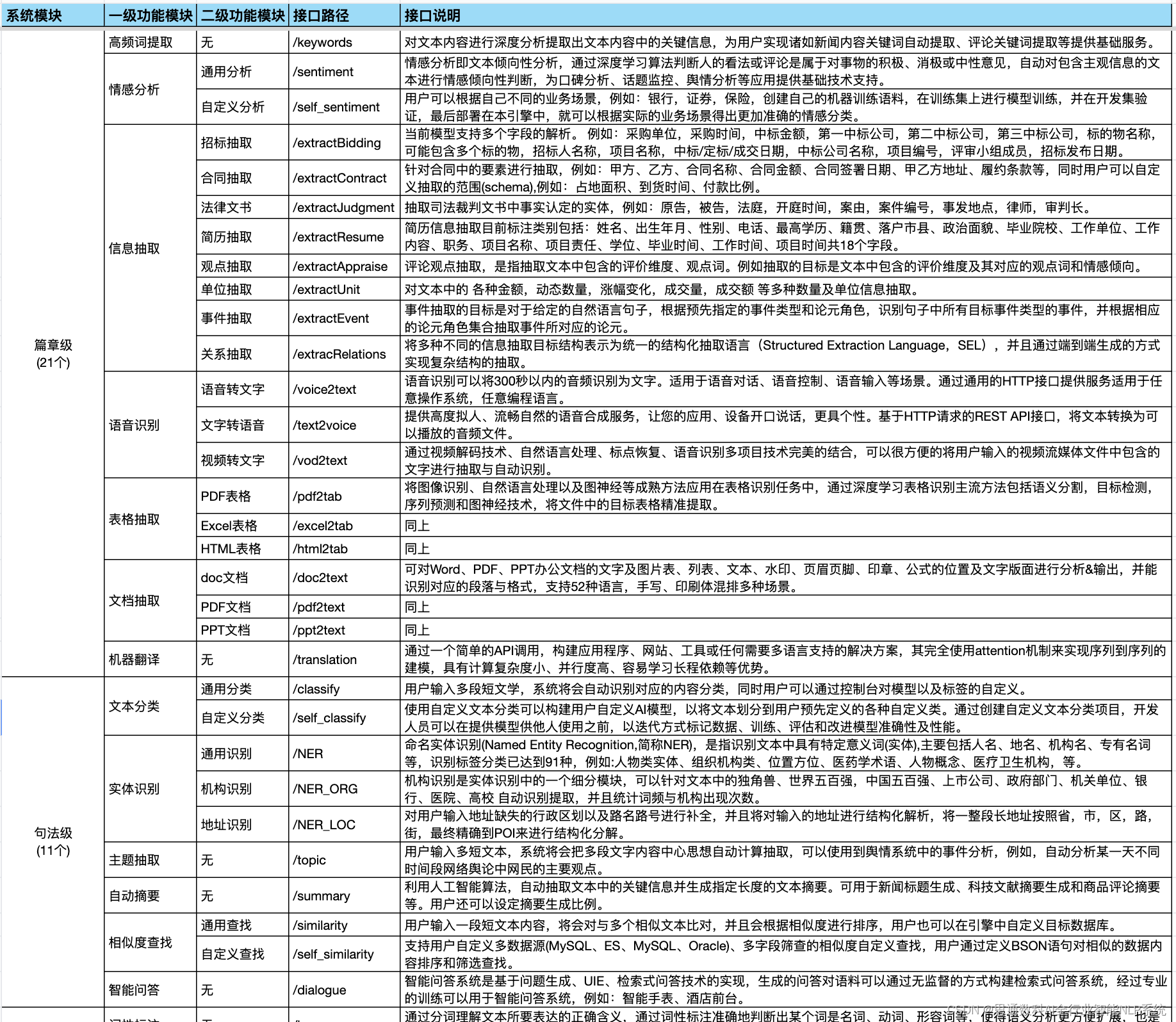
思通数科大模型的融合
思通数科的大模型可以与多模态检索技术相结合,通过深度学习和自然语言处理技术,提高对文档内容的理解能力。大模型能够学习文档的结构和语义信息,为文档自动添加标签,智能化推荐相关内容,从而优化信息管理流程。
技术实现
1. OCR识别:将文档中的图像和PDF转换为可编辑的文本格式。
2. 图像识别:识别文档中的图像内容,并进行分类和标记。
3. 文本抽取:从文档中提取关键信息,如标题、摘要、关键词等。
4. 云端存储对接:与百度网盘、金山网盘、腾讯文档等云服务集成,实现文档的快速上传和检索。
5. 自动化标签:利用大模型为文档自动添加相关标签,简化分类过程。
6. 内容推荐:基于文档内容和用户行为,智能化推荐相关文档。

应用案例分析
以思通数科的智能文档处理系统为例,该系统通过多模态检索技术和大模型的结合,能够快速处理和检索企业内部的非结构化数据。系统不仅提高了检索效率,还通过自动化标签和内容推荐,优化了用户体验。
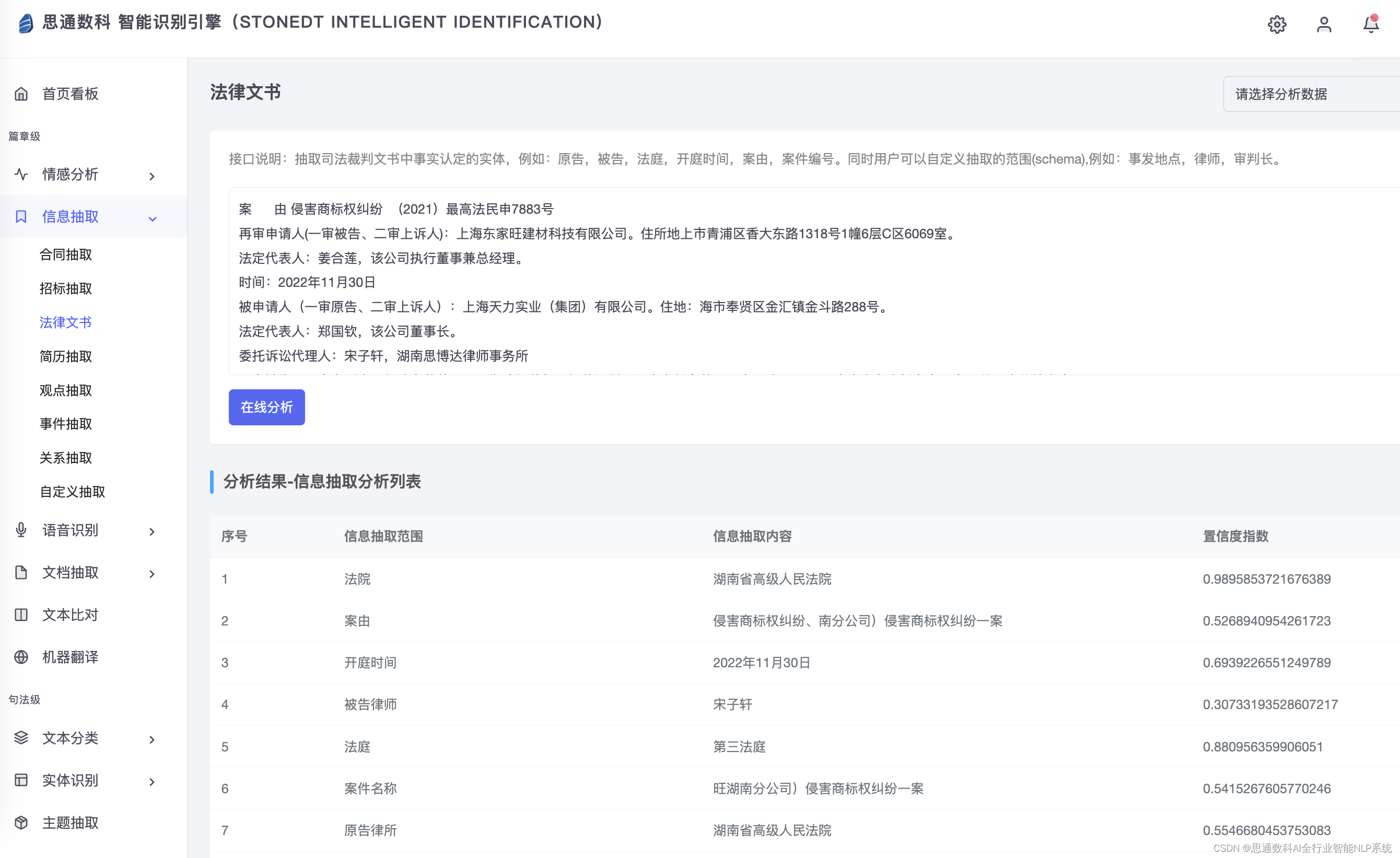
技术挑战与未来方向
尽管多模态检索技术和大模型在智能文档处理中展现出巨大潜力,但仍面临一些挑战,如处理复杂图像和手写文本的准确性、多语言文档的支持等。未来的研究方向可能包括提高模型的泛化能力、优化算法以适应更多的文档格式和内容。
结论
多模态检索技术和思通数科大模型的结合为智能文档处理提供了强大的工具。通过自动化处理非结构化数据,企业和组织能够提高信息检索的效率,加快信息流转,支持更精准的数据分析和业务决策。随着技术的不断进步,智能文档处理将在更多领域发挥重要作用。
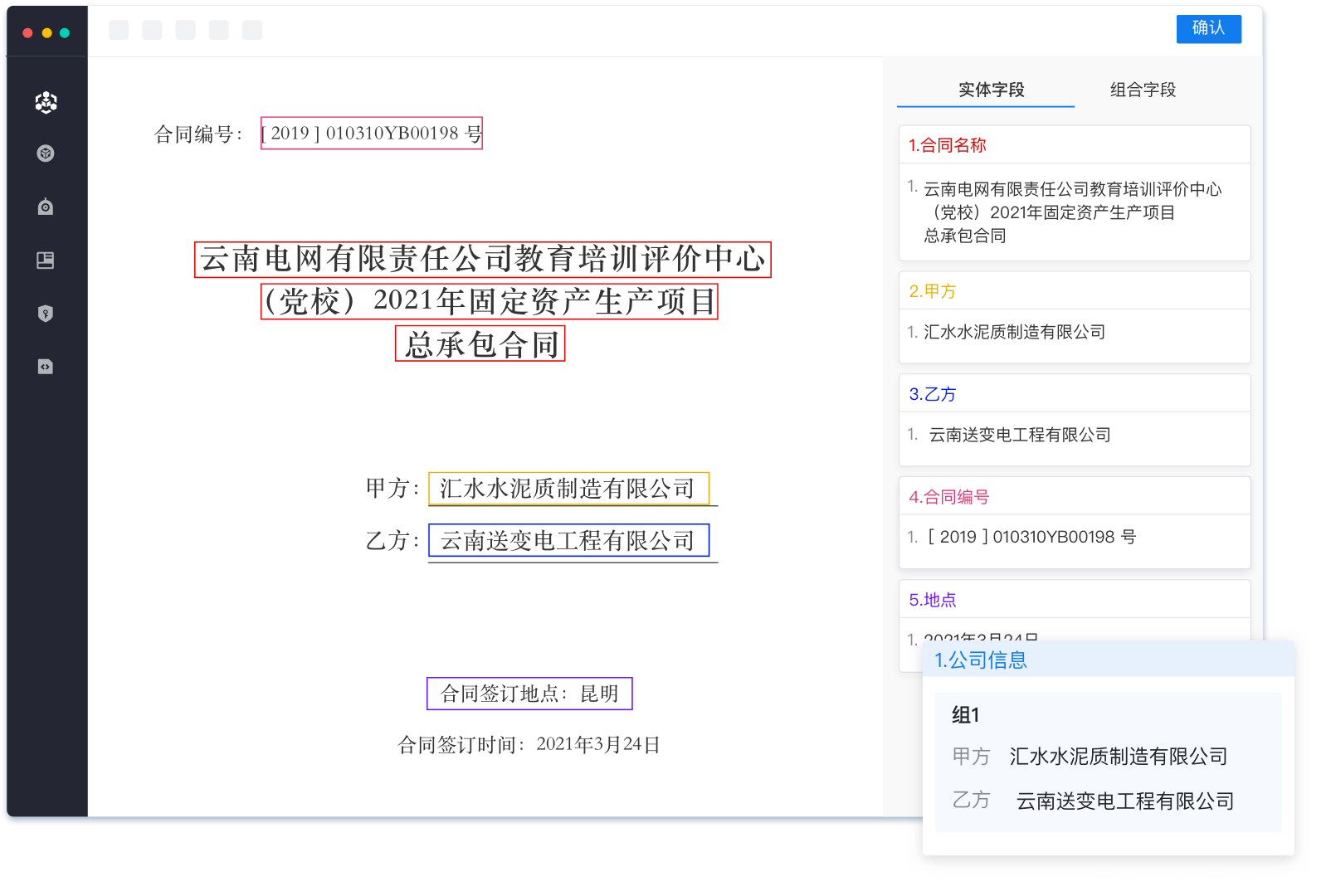
同时向大家推荐一个AI开源项目:自然语言处理、情感分析、实体识别、信息抽取、图像识别、OCR识别、语音识别接口。
获取本项目地址,请百度搜索:思通数科+多模态AI
https://gitee.com/stonedtx/free-nlp-api















 1286
1286

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









