






React + LangChain + RAG实战:打造一个专业的AI医疗助手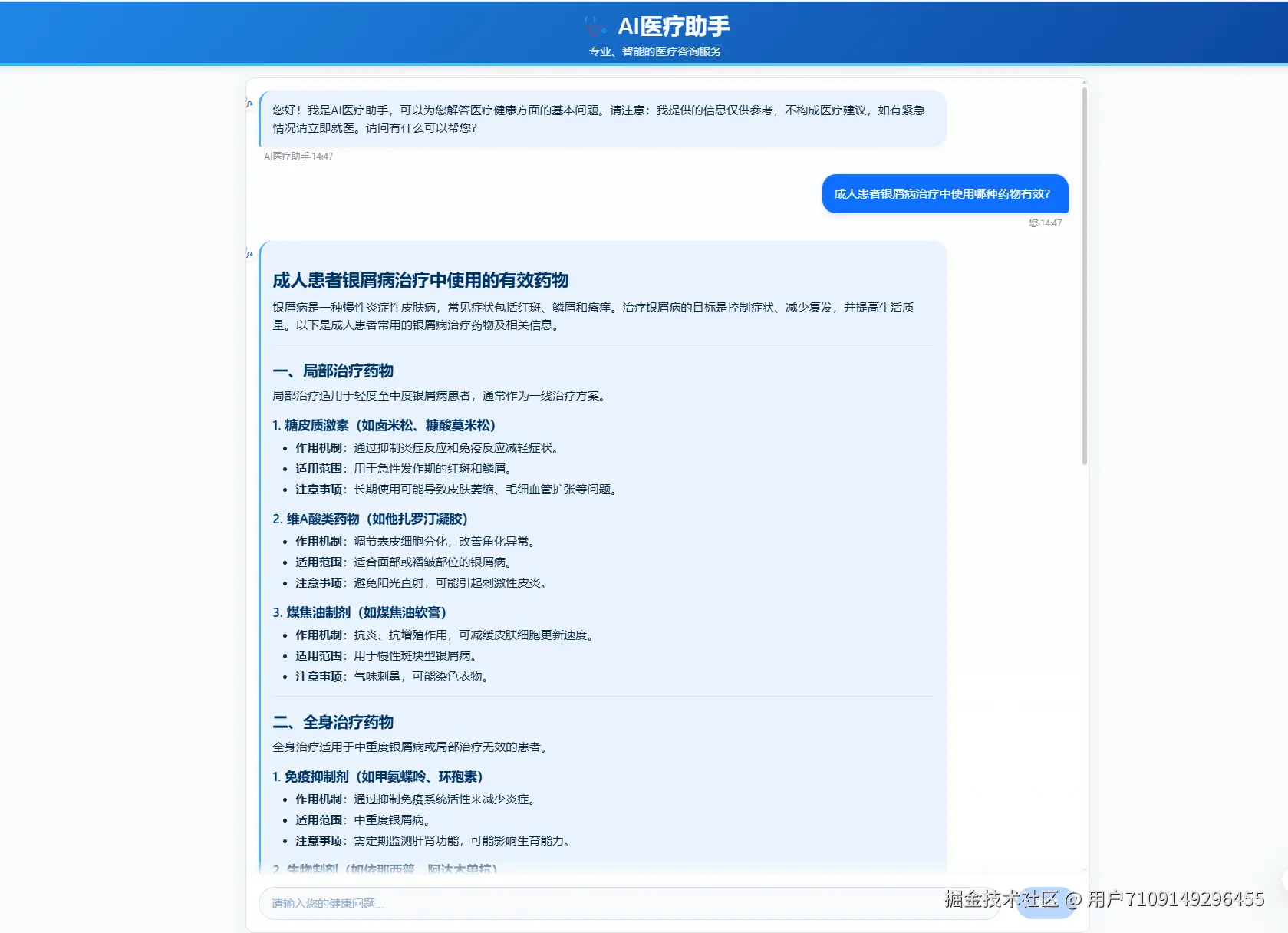
前言
本文将分享如何基于React和LangChain框架,结合通义千问大语言模型,打造一个专业的AI医疗助手应用,实现图文多模态交互、医疗知识检索以及智能对话功能。
技术栈
- 前端:React + TypeScript + CSS
- 后端:FastAPI + LangChain + Pydantic
- 模型:通义千问(Qwen)文本模型 + 通义千问VL多模态模型
- 知识库:本地医疗知识库 + 向量检索
系统架构
系统采用前后端分离架构,通过RESTful API进行通信:
- 前端:负责UI呈现、用户交互和消息管理
- 后端:负责模型调用、知识检索和会话管理
- 知识库:提供专业医疗知识支持
核心功能
1. 多模态交互
支持图文结合的方式咨询医疗问题,用户可以上传病历、检查报告等图片,AI能够理解图片内容并给出专业解读。
// 前端图片上传与转Base64处理
const convertImageToBase64 = (file: File): Promise<string> => {
return new Promise((resolve, reject) => {
const reader = new FileReader();
reader.onload = () => resolve(reader.result as string);
reader.onerror = error => reject(error);
reader.readAsDataURL(file);
});
};
2. RAG检索增强生成
使用LangChain实现的RAG功能,可以从本地医疗知识库中检索相关内容,增强AI的回答质量和专业性:
# 使用RAG增强回答
if docs:
# 如果找到相关文档,准备上下文
context = format_docs(docs)
print(f"找到相关文档,使用RAG模板生成回答,文档数量: {len(docs)}")
# 组合上下文和历史到RAG提示
rag_chain = (
rag_prompt
| model
| StrOutputParser()
)
return rag_chain.invoke({
"context": context,
"question": question,
"history_context": history_context
})
3. 流式响应
实现打字机效果的流式响应,提升用户体验:
# 后端流式响应实现
async def event_generator():
# 模拟流式输出
for char in full_response:
yield {
"event": "message",
"data": char
}
await asyncio.sleep(0.01)
4. Markdown渲染
支持Markdown格式的回答渲染,使医疗信息展示更加结构化和易读:
// Markdown渲染组件
const MarkdownContent = ({ content }: { content: string }) => {
return (
<ReactMarkdown
rehypePlugins={[rehypeSanitize]}
remarkPlugins={[remarkGfm]}
>
{content}
</ReactMarkdown>
);
};
5. 会话持久化
支持对话历史的保存和恢复,让用户可以继续之前的咨询:
// 第一次加载时检查本地存储的会话ID
useEffect(() => {
const savedConversationId = localStorage.getItem('medicalAssistantConversationId');
if (savedConversationId) {
setConversationId(savedConversationId);
loadChatHistory(savedConversationId);
}
}, []);
关键实现细节
多模态调用优化
直接使用DashScope SDK调用多模态模型,确保图片分析能力:
# 调用多模态模型
response = MultiModalConversation.call(
model='qwen-vl-plus',
messages=messages,
stream=False,
result_format='message',
temperature=0.7,
max_tokens=1000,
)
图片处理
在后端验证和处理用户上传的图片:
# 解码base64图片并验证
image_bytes = base64.b64decode(base64_data)
image = Image.open(io.BytesIO(image_bytes))
image_format = image.format.lower() if image.format else "jpeg"
提示工程
为医疗场景定制的提示模板,引导AI生成专业、负责任的医疗建议:
RAG_TEMPLATE = """你是一位专业的AI医疗助手,会提供准确、有帮助的医疗健康信息。
请基于以下参考信息、聊天历史以及你的专业知识回答用户的问题:
参考信息:
{context}
{history_context}
用户问题: {question}
请遵循以下回答规则:
1. 使用Markdown格式化你的回答,使其更易于阅读
2. 如有医学专业术语,可以使用斜体或加粗标记,并简单解释其含义
3. 如果是重要的健康警告或注意事项,请使用引用块标记
...
"""
项目难点与解决方案
1. RAG稳定性问题
问题:初始RAG组件存在路径解析错误和API配置问题 解决:实现了更可靠的文件路径解析和API配置,并添加了全面的错误处理
2. 多模态集成挑战
问题:模型无法正确处理图片内容 解决:放弃LangChain包装,直接使用DashScope SDK调用模型,并优化消息格式
3. 图片显示问题
问题:历史记录中的图片无法正确显示 解决:实现图片URL转换和静态文件服务,确保图片可以正确加载和显示
# 处理每条消息中的图片URL
processed_messages = []
for msg in messages:
processed_msg = msg.copy()
if "image_url" in processed_msg:
image_path = processed_msg["image_url"]
if image_path and os.path.exists(image_path):
relative_path = os.path.relpath(image_path, UPLOAD_DIR)
processed_msg["image_url"] = f"/uploads/{relative_path}"
processed_messages.append(processed_msg)
总结与展望
本项目通过结合React和LangChain,成功构建了一个功能完整的AI医疗助手应用。系统支持多模态交互、知识增强生成和流式响应等特性,为用户提供专业、易用的医疗咨询体验。
未来计划:
- 集成更多的医疗专科知识库
- 添加语音交互功能
- 支持医疗报告自动解读
- 实现用户个性化推荐

















 500
500

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









