







import nltk
nltk.download() #下载corpora 和 book
#测试book
from nltk.book import *
有text1 ~ text9
#搜索文本
text1.concordance("monstrous")
#查找与词有相似的上下文,如the ___ pictures 和 the ___ size
text1.similar("monstrous")
#共用两个或两个以上词汇的上下文
text2.common_contexts( [ "monstrous", "very" ] )
# 词在文本中的位置, 用离散图表示
text4.dispersion_plot( ["citizens", "democracy", "freedom", "duties", "America"] )
# 不同风格产生随机文本
text3.generate()
# 计数词汇
len(text3)
44764个标识符
# 获得词汇表
set(text3)
sorted(set(text3))
len(set(text3))
2789 个不同的词汇 #是指一个词在一个文本中独一无二的出现或拼写形式
from __future__ import division
len(text3) / len(set(text3))
16.05
text3.count("smote") #词出现的次数
100 * text4.count('a) / len(text4)
1.46
# 频率分布
fdist1 = FreqDist(text1)
fdist1
FreqDist({u'foul': 11,
u'four': 74,
u'fleeces': 1,
u'woods': 9,
u'clotted': 2,
u'hanging': 19,
u'woody': 1,
u'Until': 2,
u'disobeying': 1, vocabulary1 = fdist1.keys() # keys提供文本中所有不同类型的链表
vocabulary1[:50] # 切片查看
fdist1['whale']
fdist1.plot(50, cumulative=True) # 累积词频图
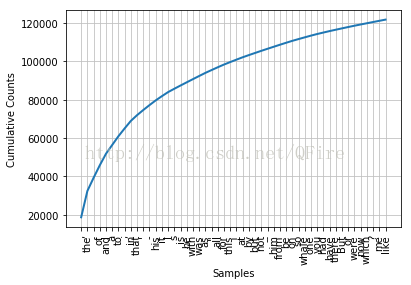
# 细粒度的选择词
集合论:找出文本词汇表中长度超过15个字符的词,把它称为P特性
w | w 属于 V 并且 P(w)
对应的Python表达式 w for w in V if P(w)
V = set(text1)
long_words = [ w for w in V if len(w) > 15]
sorted(long_words)
[u'CIRCUMNAVIGATION', u'Physiognomically', u'apprehensiveness', u'cannibalistically', u'characteristically'.....
聊天语料库中所有长度超过7个字符并且出现次数超过7次的词
fdist5 = FreqDist(text5)
sorted([ w for w in set(text5) if len(w) > 7 and fdist5(text5)[w] > 7 ])
# 词语搭配和双连词
双连词 bigrams()
text4.collocations()
# 计算其他东西
最频繁词的长度是多少, 有多少个?

#

# 嵌套代码块
允许我们在条件表达式或者说if语句条件满足时执行代码块
# 自动理解自然语言
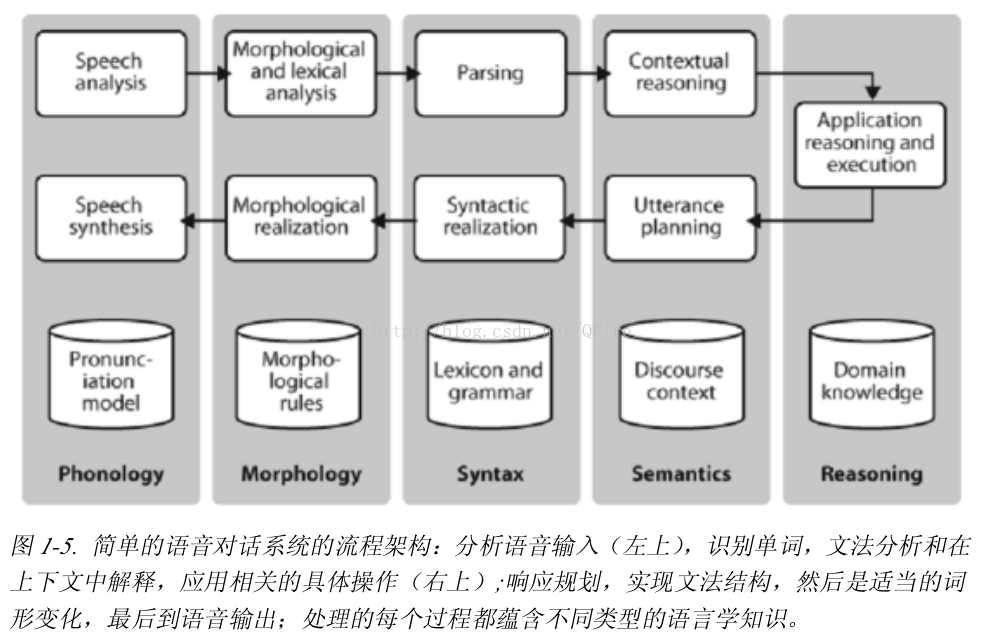
# NLP的局限性
仍然不能进行常识推理或以一般的可靠的方式描述这个世界的知识
# 深入阅读
http://www.nltk.org
计算语言学协会ACL
LanguageLog语言学博客














 7391
7391











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









