



1. 第一个CUDA程序
目录结构:
.
├── Makefile
├── src
│ └── main.cu
main.cu 文件
#include <stdio.h>
// __global__ 表示该函数是一个可以在 GPU 上运行的内核函数
__global__ void printHello_from_gpu(){
printf("hello\n");
}
int main(){
// 调用printHello_from_gpu函数,<<<4,4>>> 表示启动 4 个线程块(blocks),每个线程块包含 4 个线程(threads),
// 总共 16 个线程,每个 GPU 线程都会执行这条语句
printHello_from_gpu<<<4,4>>>();
cudaDeviceSynchronize(); // 同步函数,确保所有 GPU 内核函数执行完毕后,主机(CPU)才能继续执行后续代码
printf("🤪 over !\n");
return 0;
}
Makefile 文件
file_cu = $(shell find src -name "*.cu")
workspeace/exec : $(file_cu)
@echo "[INFO] compile $^ to $@"
@mkdir -p $(dir $@)
@nvcc $^ -o $@
run : workspeace/exec
@echo "[RUN] ./$<"
@./$<
debug : workspeace/exec
@echo "[DEBUG]"
clean :
@$(shell rm -r ./workspeace)
.PHONY : run debug clean
终端运行 make run 命令,会输出16个hello.
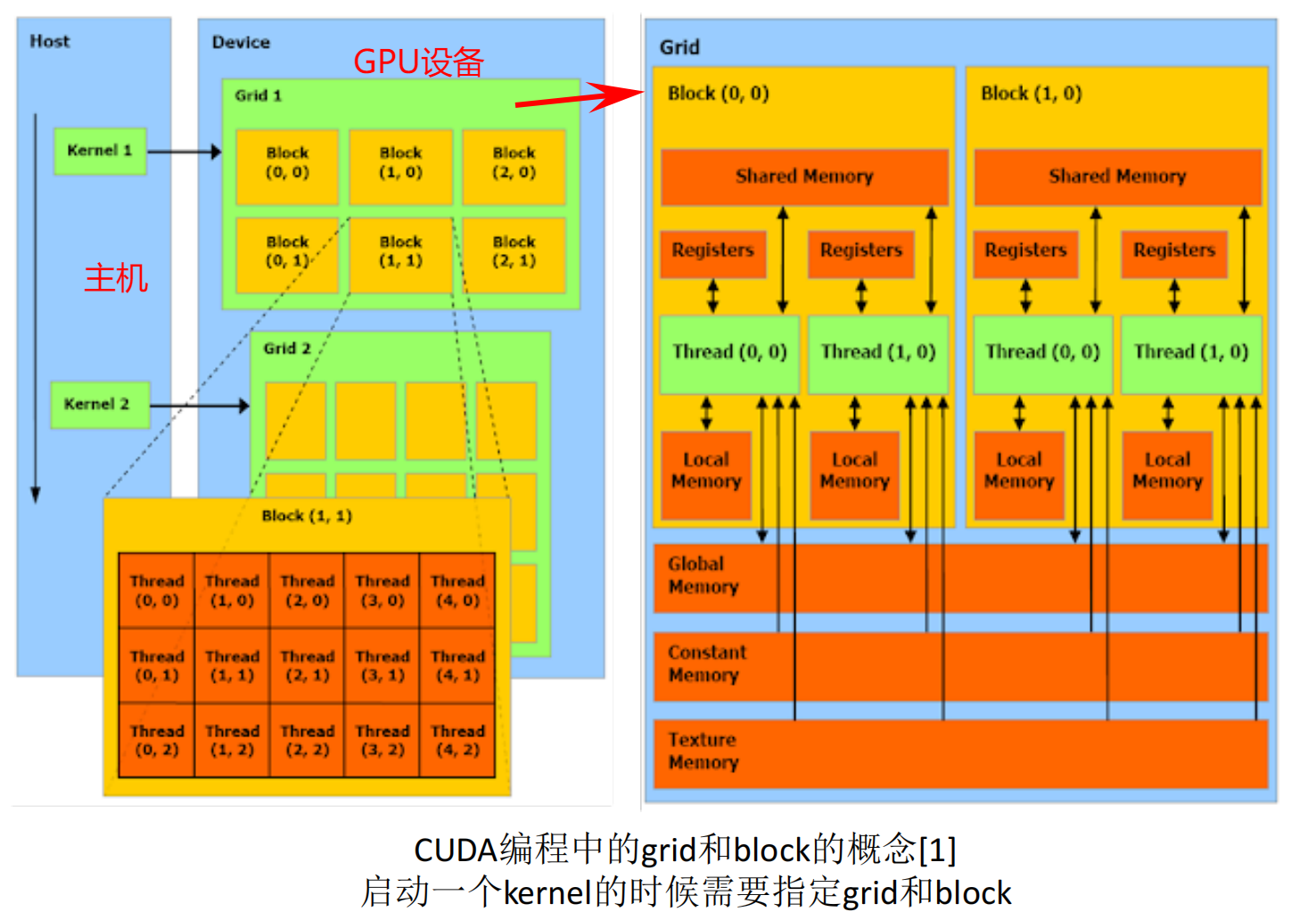
2.CUDA中的grid和block
强调::
- Kernel: Kernel不是CPU,而是在GPU上运行的特殊函数。你可以把Kernel想象成GPU上并行执行的任务。当你从主机(CPU)调用Kernel时,它在GPU上启动,并在许多线程上并行运行。
- Grid: 当你启动Kernel时,你会定义一个网格(grid)。网格是一维、二维或三维的,代表了block的集合。
- Block: 每个block内部包含了许多线程。block也可以是一维、二维或三维的。
- Thread: 每个线程是Kernel的单个执行实例。在一个block中的所有线程可以共享一些资源,并能够相互通信。
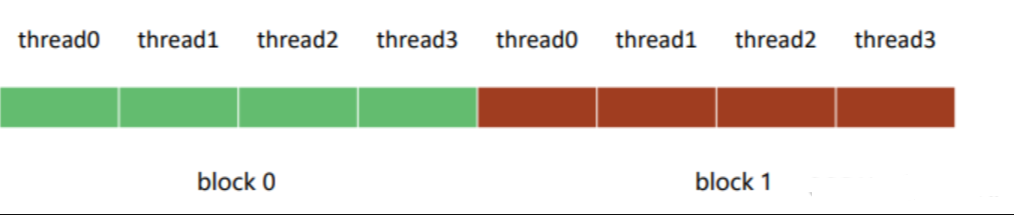
2.1 1D traverse
两个block, 每个block中有4个Thread
void print_one_dim(){
int inputSize = 8;
int blockDim = 4;
int gridDim = inputSize / blockDim; // 2
// 定义block和grid的维度
dim3 block(blockDim); // 说明一个block有多少个threads
dim3 grid(gridDim); // 说明一个grid里面有多少个block
/* 这里建议大家吧每一函数都试一遍*/
print_idx_kernel<<<grid, block>>>();
// print_dim_kernel<<<grid, block>>>();
// print_thread_idx_per_block_kernel<<<grid, block>>>();
// print_thread_idx_per_grid_kernel<<<grid, block>>>();
cudaDeviceSynchronize();
}
总体来说,这两行代码定义了内核的执行配置,将整个计算空间划分为2个block,每个block包含4个线程。你可以想象这个配置如下:
- Block 0: 线程0, 线程1, 线程2, 线程3
- Block 1: 线程4, 线程5, 线程6, 线程7
- dim3 block(blockDim);: 这一行创建了一个三维向量block,用来定义每个block的大小。在这个例子中,blockDim是一个整数值4,所以每个block包含4个线程。dim3数据类型是CUDA中的一个特殊数据类型,用于表示三维向量。在这个情况下,你传递了一个整数值,所以block的其余维度将被默认设置为1。这意味着你将有一个包含4个线程的一维block。
- dim3 grid(gridDim);: 这一行创建了一个三维向量grid,用来定义grid的大小。gridDim的计算基于输入大小(inputSize)和每个block的大小(blockDim)。在这个例子中,inputSize是8,blockDim是4,所以gridDim会是2。这意味着整个grid将包含2个block。与block一样,你传递了一个整数值给grid,所以其余维度将被默认设置为1,得到一个一维grid。
调用的结果:

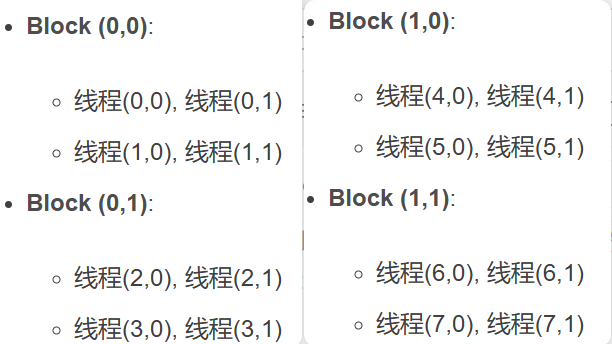
2.2 2D
// 8个线程被分成了两个
void print_two_dim(){
int inputWidth = 4;
int blockDim = 2;
int gridDim = inputWidth / blockDim;
dim3 block(blockDim, blockDim);
dim3 grid(gridDim, gridDim);
/* 这里建议大家吧每一函数都试一遍*/
// print_idx_kernel<<<grid, block>>>();
// print_dim_kernel<<<grid, block>>>();
// print_thread_idx_per_block_kernel<<<grid, block>>>();
print_thread_idx_per_grid_kernel<<<grid, block>>>();
cudaDeviceSynchronize();
}
- dim3 block(blockDim, blockDim);: 这里创建了一个二维的block,每个维度的大小都是blockDim,在这个例子中是2。因此,每个block都是2x2的,包含4个线程。由于dim3定义了一个三维向量,没有指定的第三维度会默认为1。
- dim3 grid(gridDim, gridDim);: 同样,grid也被定义为二维的,每个维度的大小都是gridDim。由于inputWidth是4,并且blockDim是2,所以gridDim会是2。因此,整个grid是2x2的,包括4个block。第三维度同样默认为1。
- 可视化如下:
执行结果如下,执行的顺序仍然是不确定的。你看到的输出顺序可能在不同的运行或不同的硬件上有所不同 。输出中的“block idx”是整个grid中block的线性索引,而“thread idx in block”是block内线程的线性索引。最后的“thread idx”是整个grid中线程的线性索引。

2.3 3D grid
- Block布局 (dim3 block(3, 4, 2)):
- 这定义了每个block的大小为3x4x2,所以每个block包含24个线程。
- 你可以将block视为三维数组,其中x方向有3个元素,y方向有4个元素,z方向有2个元素。
- Grid布局 (dim3 grid(2, 2, 2)):
- 这定义了grid的大小为2x2x2,所以整个grid包含8个block。
- 你可以将grid视为三维数组,其中x方向有2个元素,y方向有2个元素,z方向有2个元素。
- 由于每个block包括24个线程,所以整个grid将包括192个线程。
dim3 block(3, 4, 2);
dim3 grid(2, 2, 2);
3.打印对应的thread

__global__ void print_cord_kernel(){
int index = threadIdx.z * blockDim.x * blockDim.y + \
threadIdx.y * blockDim.x + \
threadIdx.x;
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
printf("block idx: (%3d, %3d, %3d), thread idx: %3d, cord: (%3d, %3d)\n",
blockIdx.z, blockIdx.y, blockIdx.x,
index, x, y);
}
index是线程索引的问题,首先,考虑z维度。对于每一层z,都有blockDim.x * blockDim.y个线程。所以threadIdx.z乘以该数量给出了前面层中的线程总数,从图上看也就是越过了多少个方块
然后,考虑y维度。对于每一行y,都有blockDim.x个线程。所以threadIdx.y乘以该数量给出了当前层中前面行的线程数,也就是在当前方块的xy面我们走了几个y, 几行
加上thread x完成索引的坐标
void print_cord(){
int inputWidth = 4;
int blockDim = 2;
int gridDim = inputWidth / blockDim;
dim3 block(blockDim, blockDim);
dim3 grid(gridDim, gridDim);
print_cord_kernel<<<grid, block>>>();
// print_thread_idx_per_grid_kernel<<<grid, block>>>();
cudaDeviceSynchronize();
}
结果
block idx: ( 0, 1, 0), thread idx: 0, cord: ( 0, 2)
block idx: ( 0, 1, 0), thread idx: 1, cord: ( 1, 2)
block idx: ( 0, 1, 0), thread idx: 2, cord: ( 0, 3)
block idx: ( 0, 1, 0), thread idx: 3, cord: ( 1, 3)
block idx: ( 0, 1, 1), thread idx: 0, cord: ( 2, 2)
block idx: ( 0, 1, 1), thread idx: 1, cord: ( 3, 2)
block idx: ( 0, 1, 1), thread idx: 2, cord: ( 2, 3)
block idx: ( 0, 1, 1), thread idx: 3, cord: ( 3, 3)
block idx: ( 0, 0, 1), thread idx: 0, cord: ( 2, 0)
block idx: ( 0, 0, 1), thread idx: 1, cord: ( 3, 0)
block idx: ( 0, 0, 1), thread idx: 2, cord: ( 2, 1)
block idx: ( 0, 0, 1), thread idx: 3, cord: ( 3, 1)
block idx: ( 0, 0, 0), thread idx: 0, cord: ( 0, 0)
block idx: ( 0, 0, 0), thread idx: 1, cord: ( 1, 0)
block idx: ( 0, 0, 0), thread idx: 2, cord: ( 0, 1)
block idx: ( 0, 0, 0), thread idx: 3, cord: ( 1, 1)
4.总的代码
#include <cuda_runtime.h>
#include <stdio.h>
// 打印核的id
__global__ void print_idx_kernel(){
printf("block idx: (%3d, %3d, %3d), thread idx: (%3d, %3d, %3d)\n",
blockIdx.z, blockIdx.y, blockIdx.x,
threadIdx.z, threadIdx.y, threadIdx.x);
}
__global__ void print_dim_kernel(){
printf("grid dimension: (%3d, %3d, %3d), block dimension: (%3d, %3d, %3d)\n",
gridDim.z, gridDim.y, gridDim.x,
blockDim.z, blockDim.y, blockDim.x);
}
__global__ void print_thread_idx_per_block_kernel(){
int index = threadIdx.z * blockDim.x * blockDim.y + \
threadIdx.y * blockDim.x + \
threadIdx.x;
printf("block idx: (%3d, %3d, %3d), thread idx: %3d\n",
blockIdx.z, blockIdx.y, blockIdx.x,
index);
}
__global__ void print_thread_idx_per_grid_kernel(){
int bSize = blockDim.z * blockDim.y * blockDim.x;
int bIndex = blockIdx.z * gridDim.x * gridDim.y + \
blockIdx.y * gridDim.x + \
blockIdx.x;
int tIndex = threadIdx.z * blockDim.x * blockDim.y + \
threadIdx.y * blockDim.x + \
threadIdx.x;
int index = bIndex * bSize + tIndex;
printf("block idx: %3d, thread idx in block: %3d, thread idx: %3d\n",
bIndex, tIndex, index);
}
__global__ void print_cord_kernel(){
int index = threadIdx.z * blockDim.x * blockDim.y + \
threadIdx.y * blockDim.x + \
threadIdx.x;
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
printf("block idx: (%3d, %3d, %3d), thread idx: %3d, cord: (%3d, %3d)\n",
blockIdx.z, blockIdx.y, blockIdx.x,
index, x, y);
}
void print_one_dim(){
int inputSize = 8;
int blockDim = 4;
int gridDim = inputSize / blockDim;
dim3 block(blockDim); // 一个block中的线程数
dim3 grid(gridDim); // 一个grid里面有多少个block
/* 这里建议大家吧每一函数都试一遍*/
print_idx_kernel<<<grid, block>>>(); // 打印核函数id
print_dim_kernel<<<grid, block>>>(); // 打印纬度
print_thread_idx_per_block_kernel<<<grid, block>>>();
print_thread_idx_per_grid_kernel<<<grid, block>>>();
cudaDeviceSynchronize();
}
void print_two_dim(){
int inputWidth = 4;
int blockDim = 2;
int gridDim = inputWidth / blockDim;
dim3 block(blockDim, blockDim);
dim3 grid(gridDim, gridDim);
/* 这里建议大家吧每一函数都试一遍*/
print_idx_kernel<<<grid, block>>>();
print_dim_kernel<<<grid, block>>>();
print_thread_idx_per_block_kernel<<<grid, block>>>();
print_thread_idx_per_grid_kernel<<<grid, block>>>();
cudaDeviceSynchronize();
}
void print_cord(){
int inputWidth = 4;
int blockDim = 2;
int gridDim = inputWidth / blockDim;
dim3 block(blockDim, blockDim); // 一个block中的线程数 4
dim3 grid(gridDim, gridDim); // 一个grid里面有多少个block 4
print_cord_kernel<<<grid, block>>>();
cudaDeviceSynchronize();
}
int main() {
/*
synchronize是同步的意思,有几种synchronize
cudaDeviceSynchronize: CPU与GPU端完成同步,CPU不执行之后的语句,直到这个语句以前的所有cuda操作结束
cudaStreamSynchronize: 跟cudaDeviceSynchronize很像,但是这个是针对某一个stream的。只同步指定的stream中的cpu/gpu操作,其他的不管
cudaThreadSynchronize: 现在已经不被推荐使用的方法
__syncthreads: 线程块内同步
*/
// print_one_dim();
print_two_dim();
// print_cord();
return 0;
}
Makefile 和文件结构,make run 运行
file_cu = $(shell find src -name "*.cu")
workspeace/exec : $(file_cu)
@echo "[INFO] compile $^ to $@"
@mkdir -p $(dir $@)
@nvcc $^ -o $@
run : workspeace/exec
@echo "[RUN] ./$<"
@./$<
debug : workspeace/exec
@echo "[DEBUG]"
clean :
@$(shell rm -r ./workspeace)
.PHONY : run debug clean


















 1031
1031

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









