



1.串行和并行
1.1Sequential processing(串行)
- 指令/代码块依次执行
- 前一条指令执行结束以后才能执行下一条语句
- 一般来说,当程序有数据依赖or分支等这些情况下需要串行
例如下面两个代码:
//1 依赖a = b + c;d = a + b;// 2分支if (...){.....}else{....}
1.2串行和并行的区别
如下图所示:在下述情况下
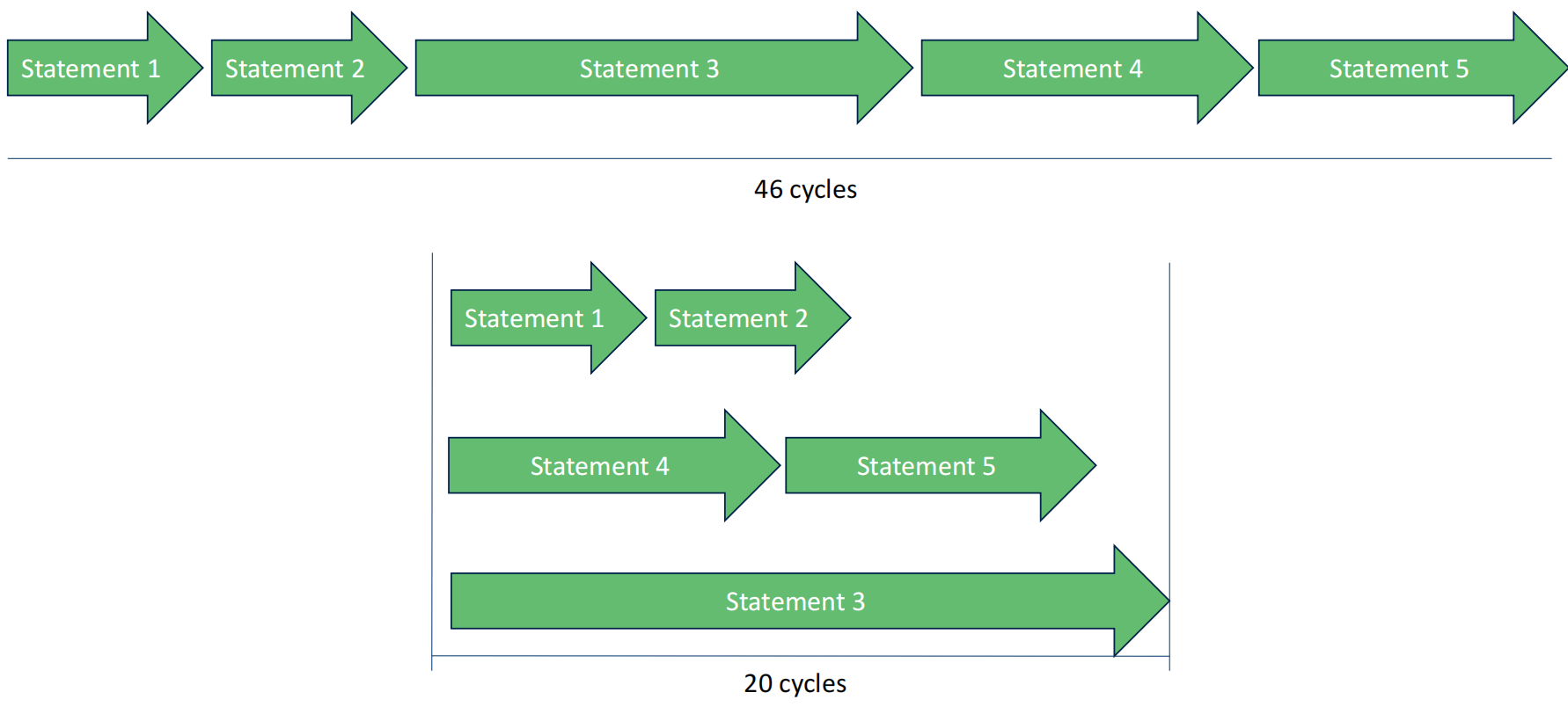
• statement 2 依赖 statement 1• statement 5 依赖 statement 4• statement 3 是一个 循环,跟所有的statement没有任何关系• 有四个core可以使用
- 同样操作,串行需要46个时钟周期,而并行只需要20个,并且可以进一步优化。
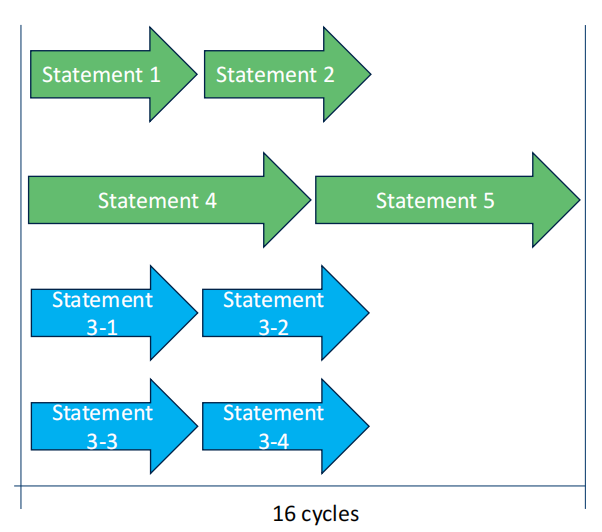
- 我们可以把 statement 3的循环拆成四份来执行,并且把其中过两个放到第四个core中,进一步压缩时钟周期到16.
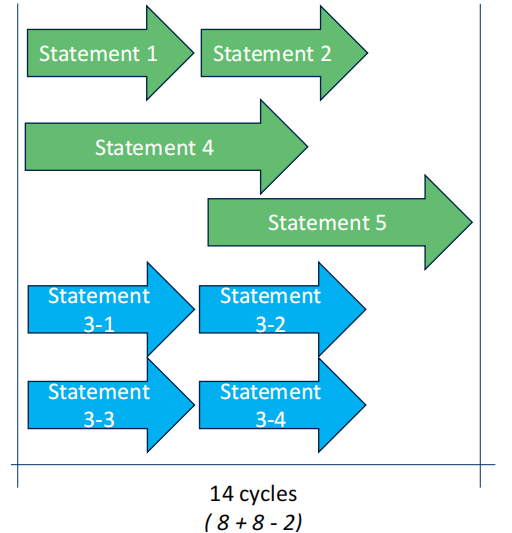
- 为了进一步压缩时钟周期。针对statement 5 依赖 statement 4这一部分进行压缩,假设在statement 4没有执行完的时候,statement 5 就可以知道结果,这是statement 5就可以执行,进一步压缩到14 cycles.
1.3总结
• 把没有数据依赖的代码分配到各个core各自执行 (schedule, 调度)• 把一个大的loop循环给分割成多个小代码,分配到各个core执行(loopoptimization)• 在一个指令彻底执行完以前,如果已经得到了想要得到的数据,可以提前执行下一个指令(pipeling, 流水线)• 我们管这一系列的行为,称作parallelization (并行化)。我们得到的可以充分利用多核多线程的程序叫做parallelized program(并行程序)• 并行指指令/代码块同时执行,充分利用multi-core(多核)的特性,多个core一起去完成一个或多个任务
2.概念辨别
并行与并发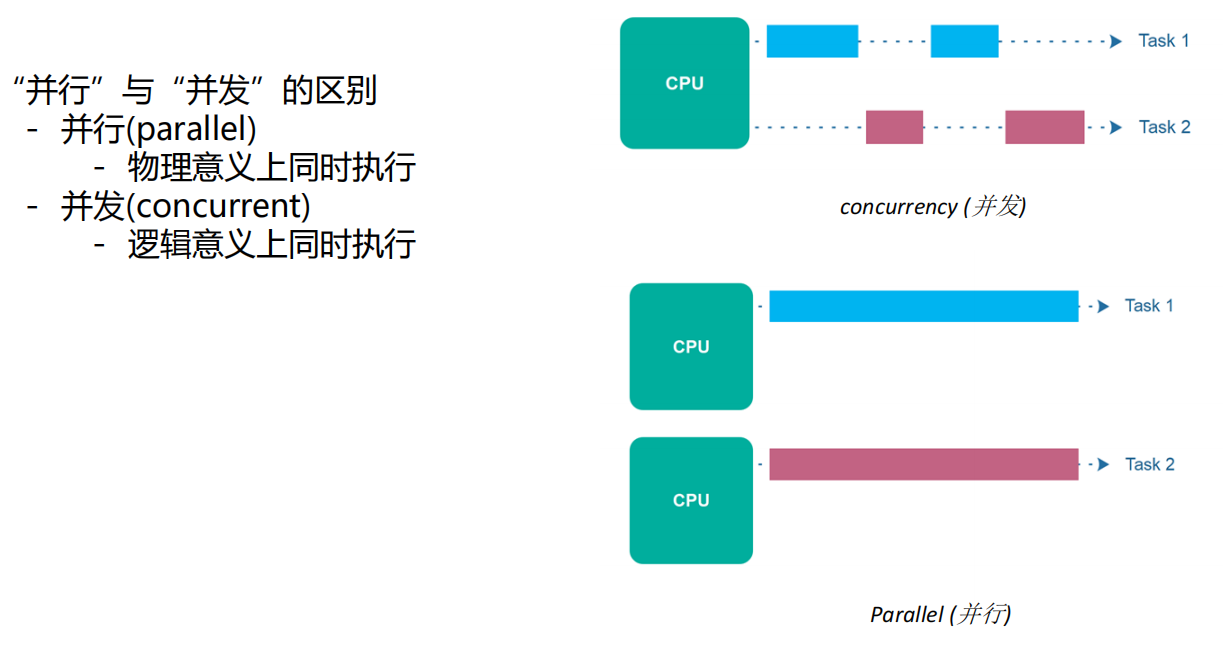
进程和线程
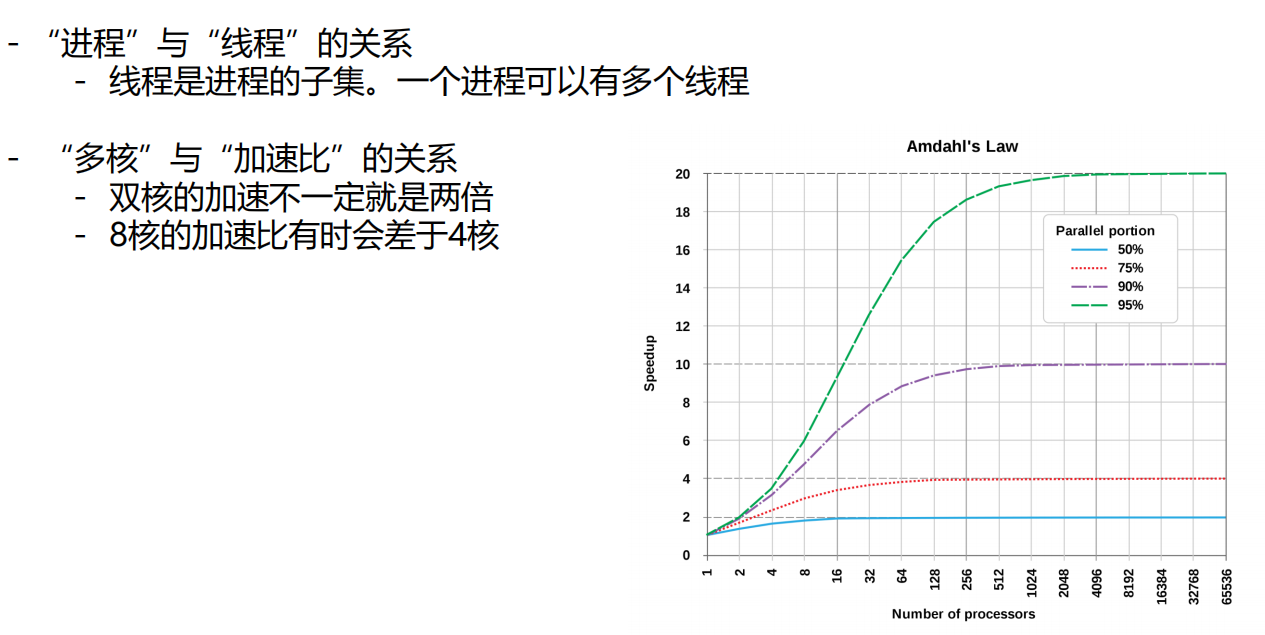
注意:右图显示了加速比具有一定的上限,出现饱和的现象。
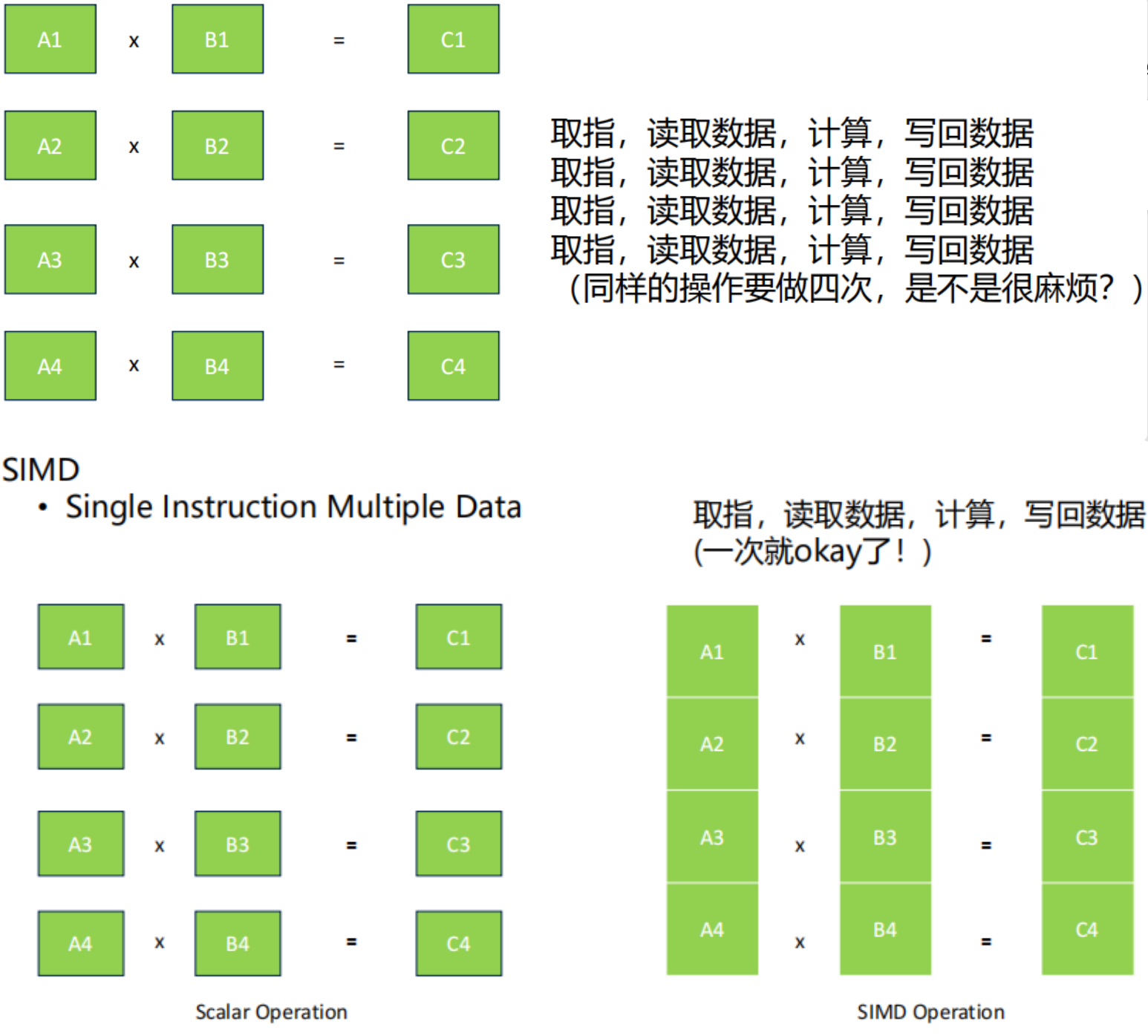
SIMD(Single Instruction Multiple Data)
指的是原先需要多次操作的过程,只需要一次完成,下图展现了区别。
其他概念
lantency:• 完成一个指令所需要的时间memory latency:• CPU/GPU从memory获取数据所需要的等待时间• CPU并行处理的优化的主要方向throughput(吞吐量):• 单位时间内可以执行的指令数• GPU并行处理的优化的主要方向Multi-threading:• 多线程处理
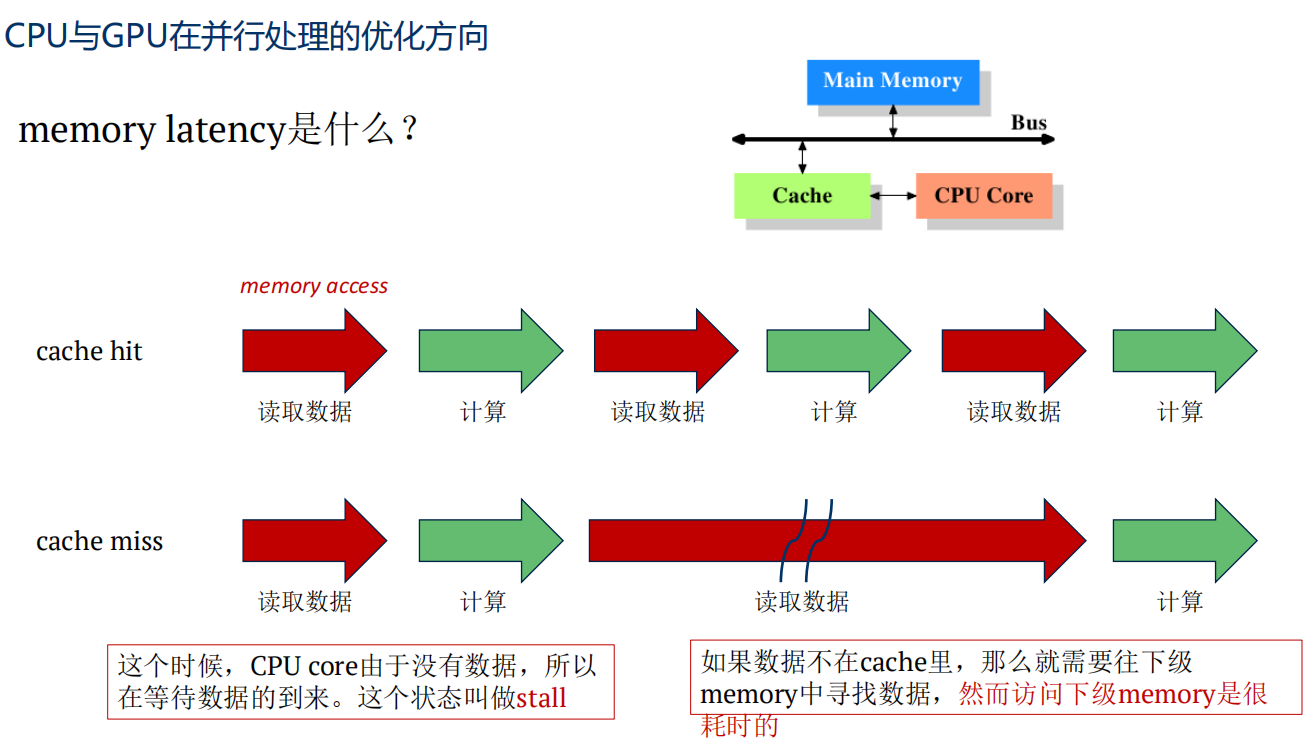
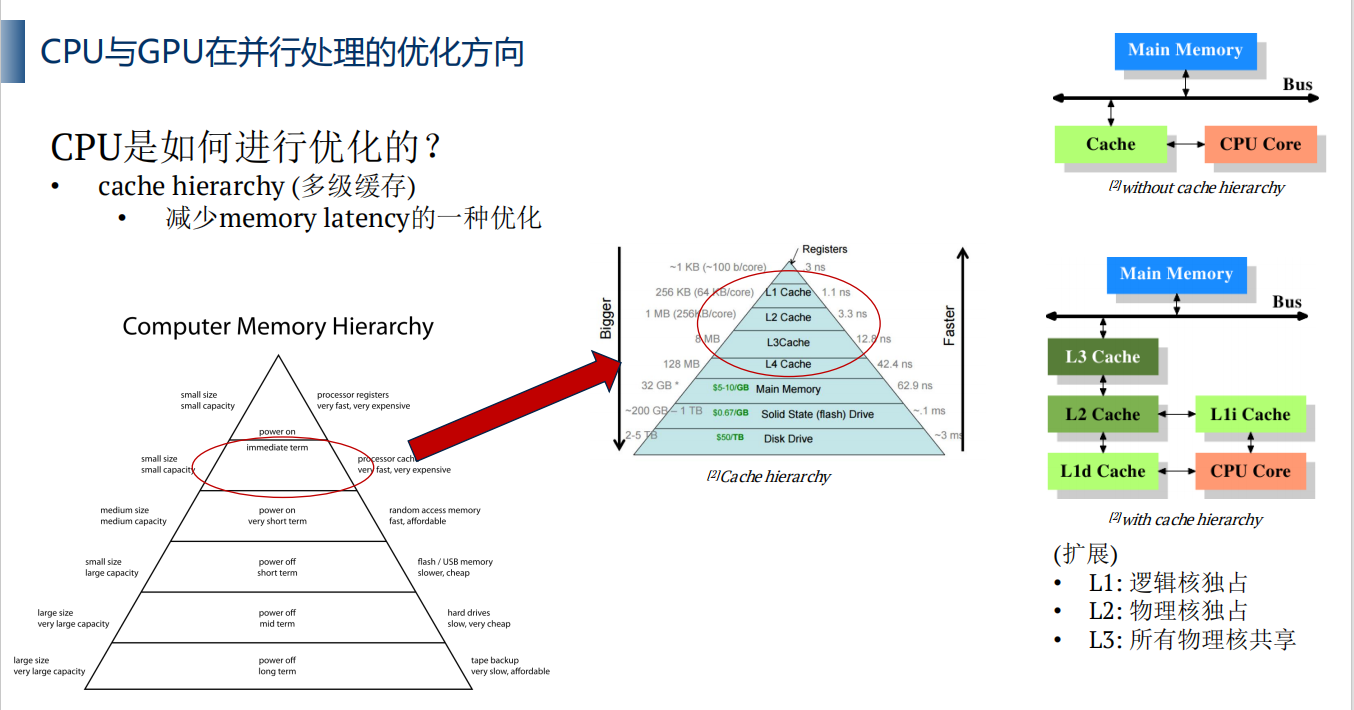
memory latency
CPU/GPU从memory获取数据所需要的等待时间,获取数据的时间。
下图右上,展示了CPU读取数据,先访问Cache,没有发现数据,则访问下级的memory,则需要更多时间。
3.CPU的优化方式
3.1 Pipeline (流水线执行)
- 提高throughput的一种优化

- 一条指令有5部分组成
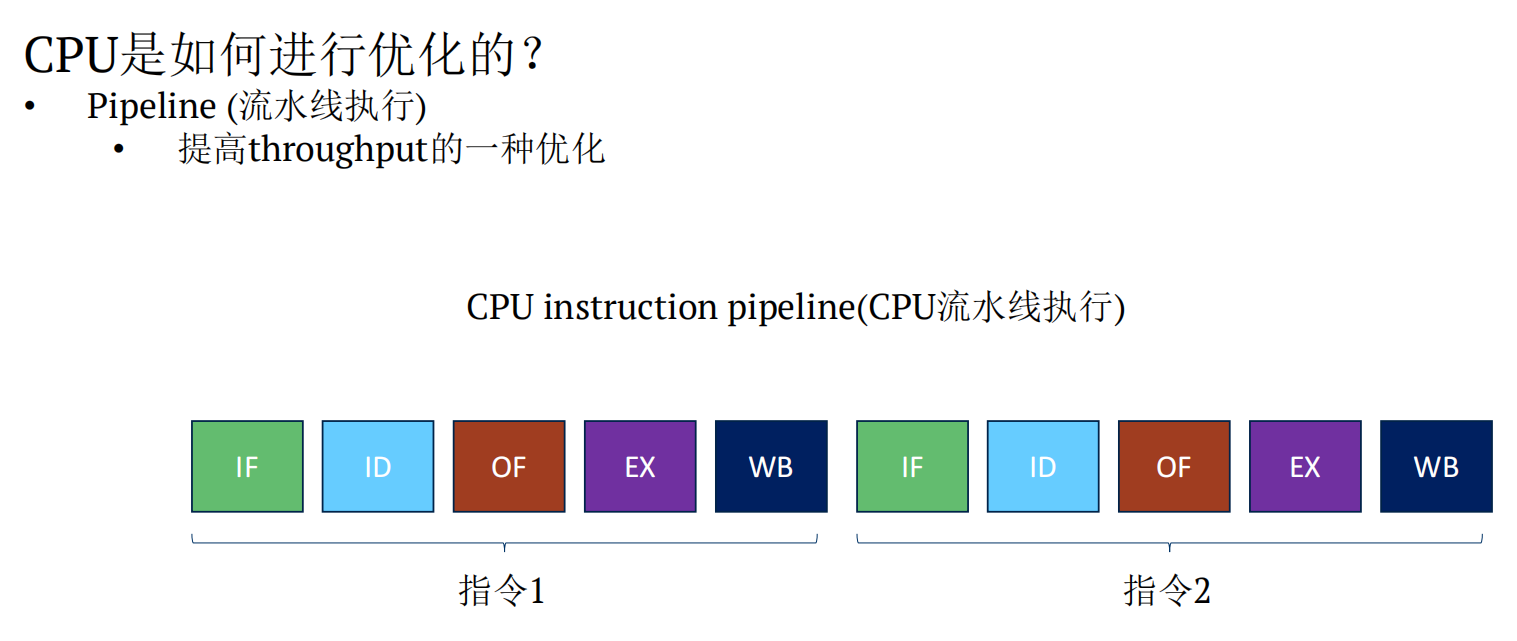
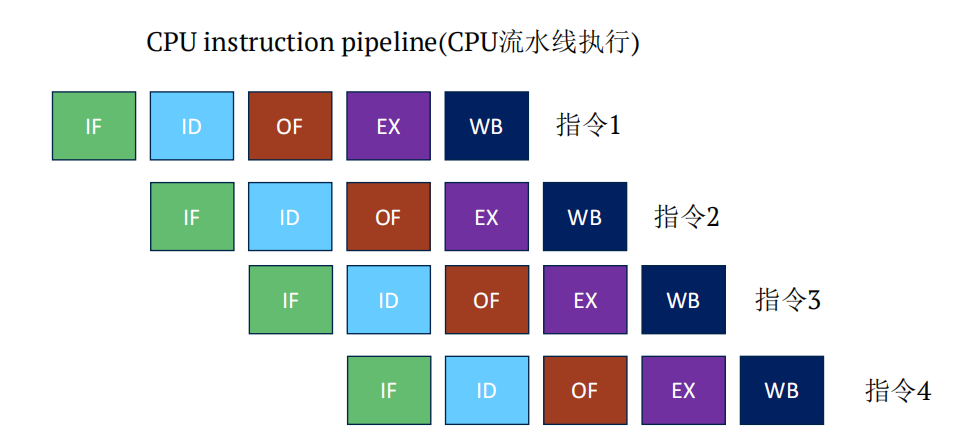
在第一个指令没有执行完是,利用多余的资源去执行第二个指令,如下图。
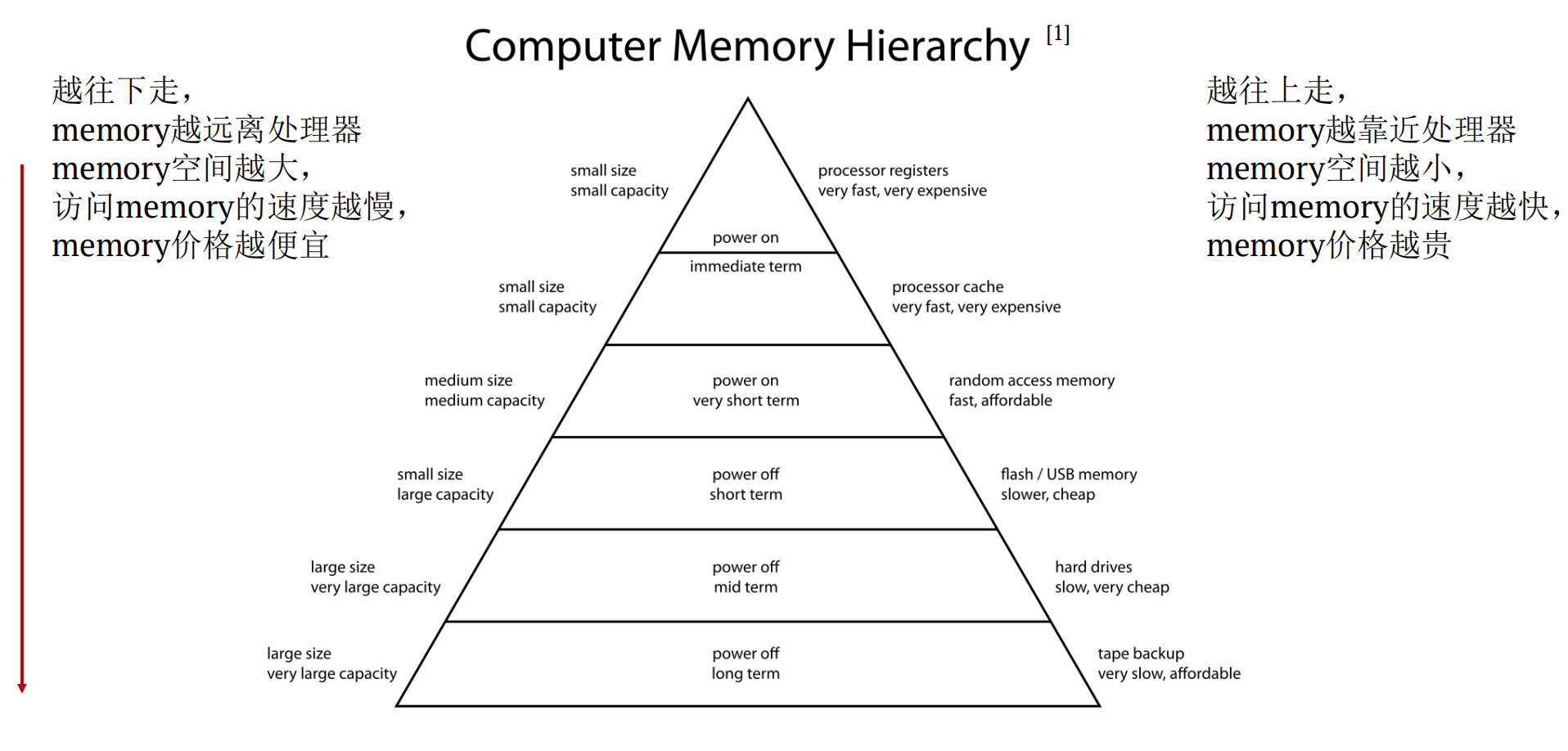
3.2 多级缓存
3.3 其他
1. Pre-fetch• 减少memory latency的一种优化2. Branch-prediction(分支预测)• 简单来说,就是根据以往的branch得走向,去预测下一次branch的走向3.Multi-threading• 充分利用计算资源的一种技术• 让因为数据依赖或者cache miss而stall的core去做一些其他的事情• 提高throughput的一种技术
总结
 4.GPU 优化方式
4.GPU 优化方式
• 由于throughput非常的高,所以相比与CPU,cache miss所产生的latency对性能的影响比较小• GPU主要负责的任务是大规模计算(图像处理、深度学习等等),所以一旦fetch好了数据以后,就会一直连续处理,并且很少cache miss
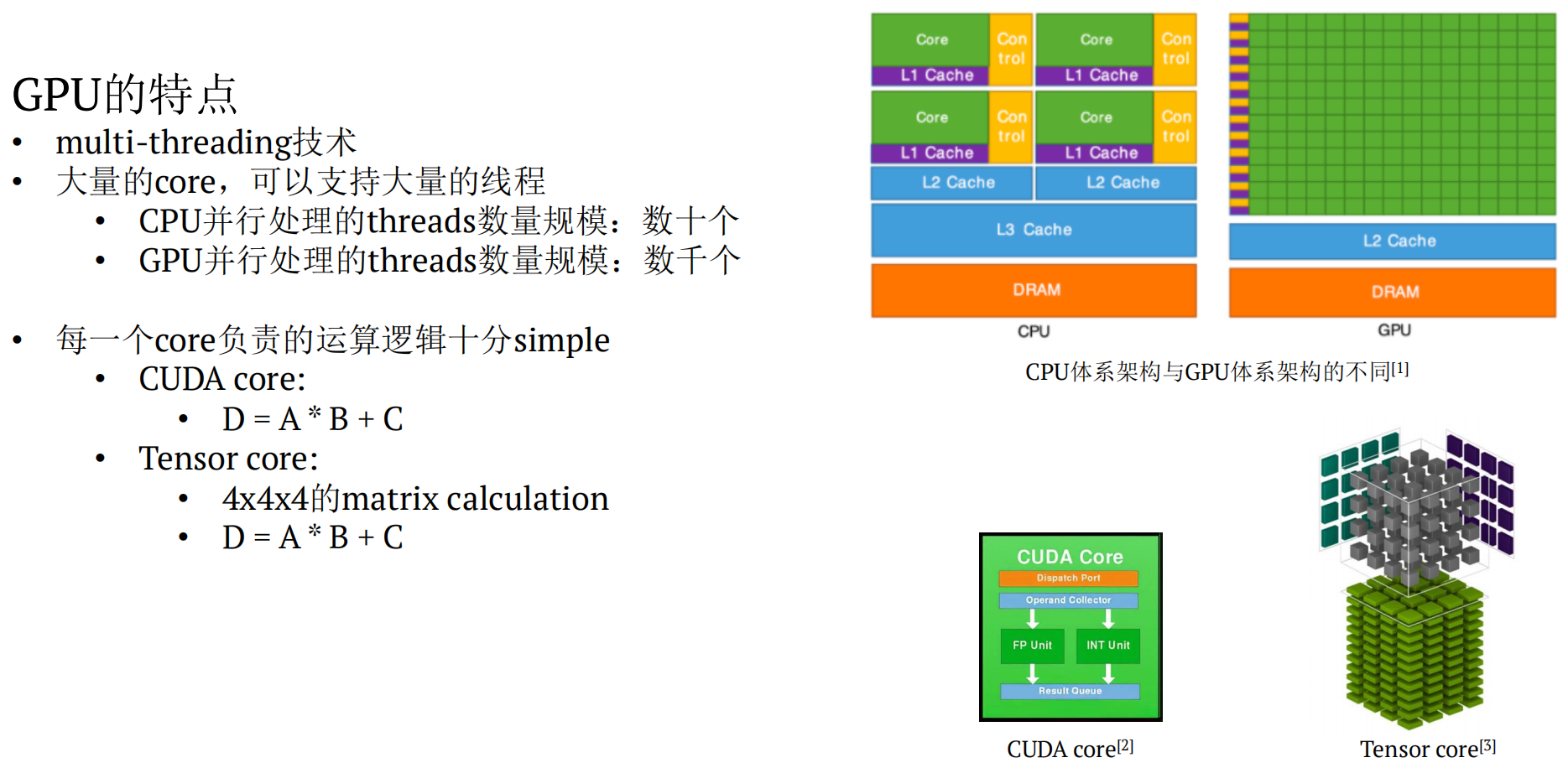
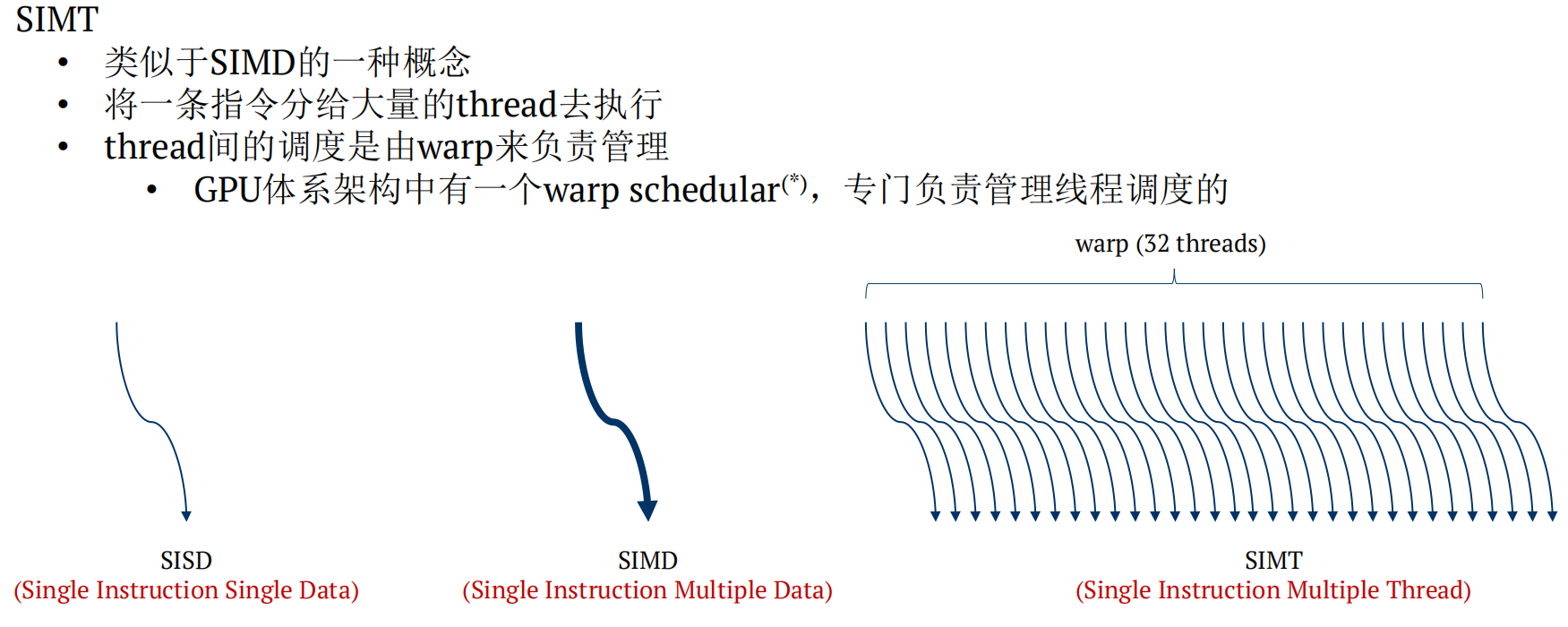
SIMT
 5.总结上面四章
5.总结上面四章
CPU与GPU的分工不同• CPU:• 适合复杂逻辑的运算• 优化方向在于减少memory latency• 相关的技术有,cache hierarchy, pre-fetch, branch-prediction, multi-threading• 不同于GPU,CPU硬件上有复杂的分支预测器去实现branch-prediction• 由于CPU经常处理复杂的逻辑,过大的增大core的数量并不能很好的提高throughput• GPU:• 适合简单单一的大规模运算。比如说科学计算,图像处理,深度学习等等• 优化方向在于提高throughput• 相关的技术有,multi-threading,warp schedular• 不同于CPU,GPU硬件上有复杂的warp schedular去实现多线程的multi-threading• 由于GPU经常处理大规模运算,所以在throughput很高的情况下,GPU内部的memory latency上带来的性能损失不是那么明显• 然而CPU和GPU间通信时所产生的memory latency需要重视
6.环境搭建
需要下述环境:
- gpu
待更新


















 651
651

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









