






 本文介绍了如何在LMDeploy环境中部署开发机,创建conda环境,安装LMDeploy,以及使用HuggingFace和TurboMind处理模型。还提供了一个使用Transformer库运行模型的Python脚本示例。最后展示了如何通过LMDeploy与预训练模型进行对话。
本文介绍了如何在LMDeploy环境中部署开发机,创建conda环境,安装LMDeploy,以及使用HuggingFace和TurboMind处理模型。还提供了一个使用Transformer库运行模型的Python脚本示例。最后展示了如何通过LMDeploy与预训练模型进行对话。
文档链接:https://github.com/InternLM/Tutorial/blob/camp2/lmdeploy/README.md
课程视频:LMDeploy 量化部署 LLM-VLM 实践_哔哩哔哩_bilibili
LMDeploy环境部署
创建开发机
因LMDeploy最新版本问题,这开发机设置时注意选择镜像Cuda12.2-conda,以及10% A100*1
创建conda环境
InternStudio上提供了快速创建conda环境的方法。在命令行终端,创建名为lmdeploy的环境(全程大约10分钟):
studio-conda -t lmdeploy -o pytorch-2.1.2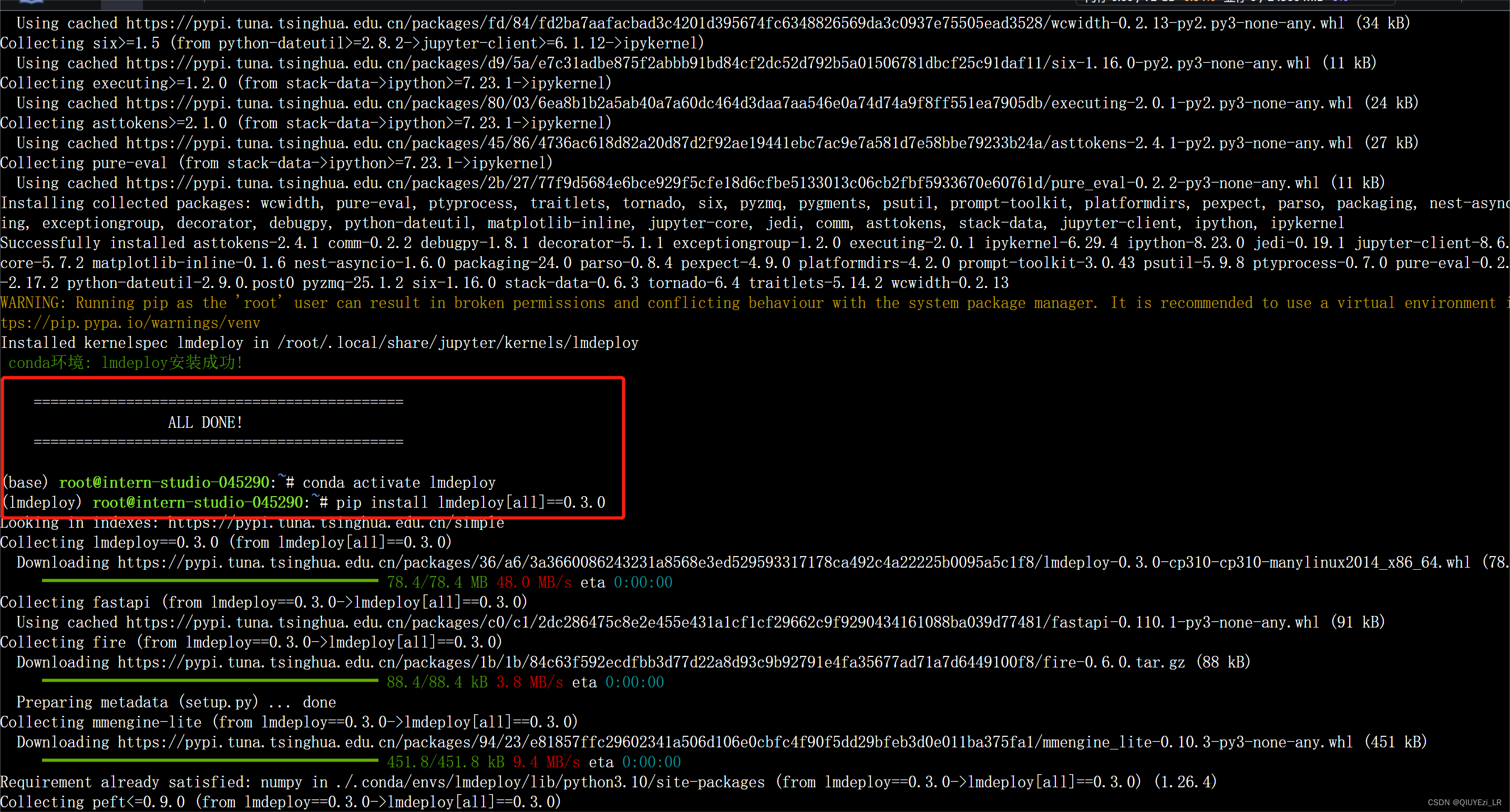
安装LMDeploy
先激活刚刚创建的虚拟环境然后接着安装0.3.0版本的lmdeploy
Huggingface与TurboMind 简介
HuggingFace是一个针对深度学习模型和数据集的在线托管社区。如果你有数据集或者模型想对外分享,可以托管在HuggingFace。如果您想获取他人开源的的数据集或模型,也可以在HuggingFace中找到。托管的模型通常采用HuggingFace格式存储,简写为HF格式。
但是HuggingFace社区的服务器在国外,国内访问不太方便。国内可以使用阿里巴巴的MindScope社区,或者上海AI Lab搭建的OpenXLab社区,上面托管的模型也通常采用HF(.safetensors)格式。
TurboMind是LMDeploy团队开发的一款关于LLM推理的高效推理引擎,它的主要功能包括:LLaMa 结构模型的支持,continuous batch 推理模式和可扩展的 KV 缓存管理器。TurboMind推理引擎仅支持推理TurboMind格式的模型。因此,TurboMind在推理HF格式的模型时,会首先自动将HF格式模型转换为TurboMind格式的模型
使用Transformer库运行模型
在终端新建脚本pipeline_transformer.py
touch /root/pipeline_transformer.py 将以下内容复制粘贴进脚本pipeline_transformer.py
脚本大致内容为:加载internlm2-chat-1_8b ,输入两个示例prompt,模型推理输出回答
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("/root/internlm2-chat-1_8b", trust_remote_code=True)
# Set `torch_dtype=torch.float16` to load model in float16, otherwise it will be loaded as float32 and cause OOM Error.
model = AutoModelForCausalLM.from_pretrained("/root/internlm2-chat-1_8b", torch_dtype=torch.float16, trust_remote_code=True).cuda()
model = model.eval()
inp = "hello"
print("[INPUT]", inp)
response, history = model.chat(tokenizer, inp, history=[])
print("[OUTPUT]", response)
inp = "please provide three suggestions about time management"
print("[INPUT]", inp)
response, history = model.chat(tokenizer, inp, history=history)
print("[OUTPUT]", response)然后运行该Python脚本
python /root/pipeline_transformer.py
2.4 使用LMDeploy与模型对话
使用LMDeploy与模型进行对话(通用命令格式为lmdeploy chat [模型路径]):
lmdeploy chat /root/internlm2-chat-1_8b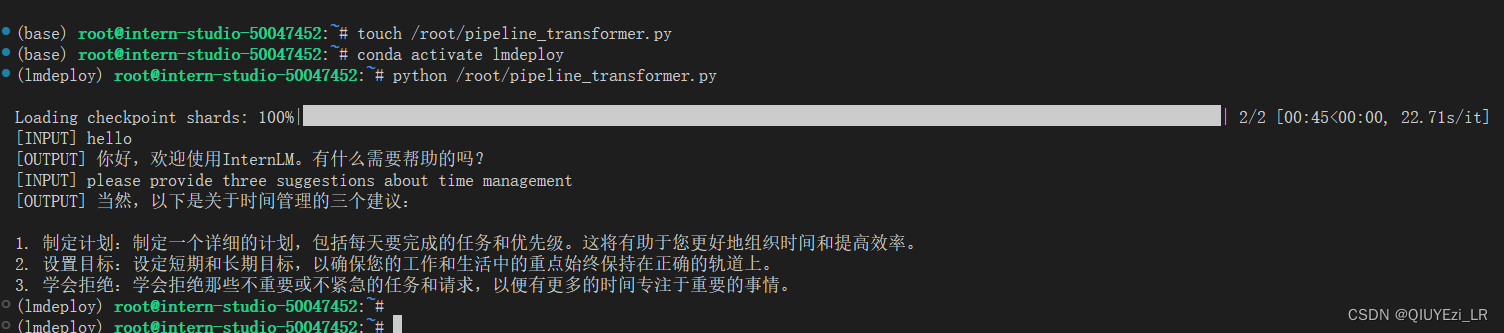















 1328
1328

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









