






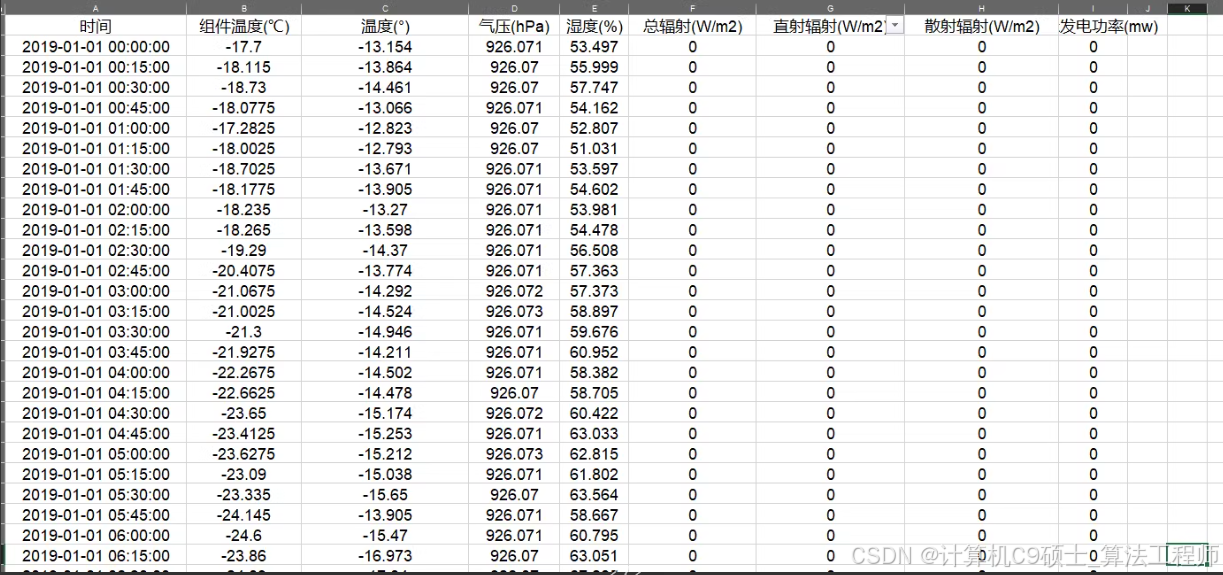
风电数据 光伏数据 功率数据。15分钟分辨率。带测风 测光。数据质量很高。可以用来做预测 数据分析等工作。数据包含2019全年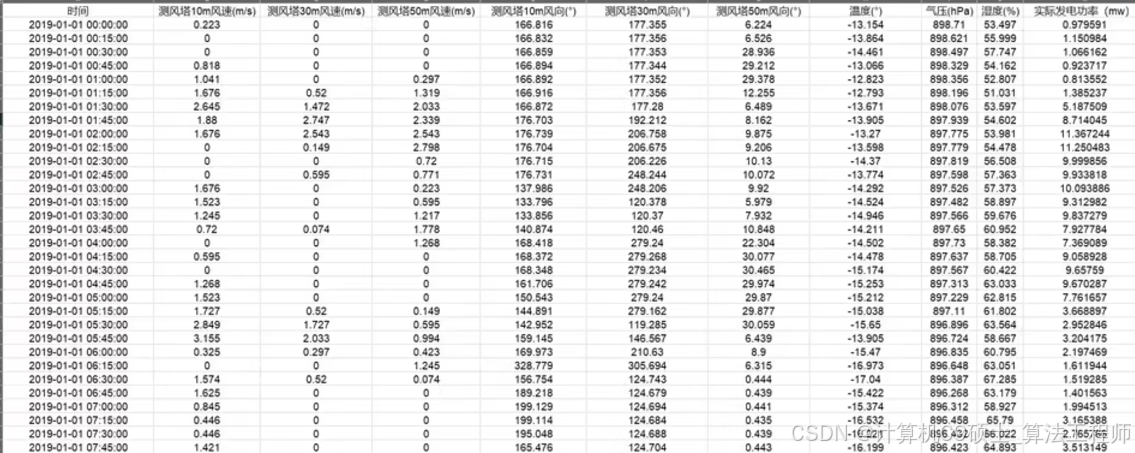
看起来你有一份包含风电和光伏数据的详细表格,数据包括测风、测光以及实际发电功率,分辨率为15分钟。这是一个非常宝贵的数据集,可以用于多种分析和预测任务。以下是如何应用这个数据集的步骤和建议:
数据探索与预处理
-
加载数据:
import pandas as pd # 假设数据存储在CSV文件中 data = pd.read_csv('wind_solar_data.csv', parse_dates=['时间']) data.head() -
数据清洗:
- 检查并处理缺失值。
- 转换日期时间字段为适当的格式。
# 检查缺失值 data.isnull().sum() # 处理缺失值 data.fillna(method='ffill', inplace=True) # 确保时间戳是datetime类型 data['时间'] = pd.to_datetime(data['时间']) -
特征工程:
- 创建新的特征,如日均功率、最大最小功率差值等。
data['日均功率'] = data.groupby(data['时间'].dt.date)['实际发电功率(mw)'].transform('mean') data['功率差值'] = data['实际发电功率(mw)'].diff()
数据分析与可视化
-
描述性统计:
data.describe() -
时间序列可视化:
import matplotlib.pyplot as plt plt.figure(figsize=(14, 6)) plt.plot(data['时间'], data['实际发电功率(mw)'], label='实际发电功率') plt.title('实际发电功率随时间变化') plt.xlabel('时间') plt.ylabel('功率 (MW)') plt.legend() plt.show()
预测建模
-
选择模型:
- 时序预测模型:ARIMA、SARIMA、Prophet。
- 机器学习模型:随机森林、梯度提升机(GBM)、支持向量机(SVM)。
- 深度学习模型:LSTM、GRU。
-
数据划分:
from sklearn.model_selection import train_test_split # 选择特征和目标变量 features = ['测风塔10m风速(m/s)', '测风塔30m风速(m/s)', '测风塔50m风速(m/s)', '测风塔10m风向(°)', '测风塔30m风向(°)', '测风塔50m风向(°)', '温度(°C)', '气压(hPa)', '测光'] target = '实际发电功率(mw)' X = data[features] y = data[target] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=False) -
模型训练与评估:
- 使用随机森林进行预测。
from sklearn.ensemble import RandomForestRegressor from sklearn.metrics import mean_squared_error model = RandomForestRegressor(n_estimators=100, random_state=42) model.fit(X_train, y_train) y_pred = model.predict(X_test) mse = mean_squared_error(y_test, y_pred) print(f'Mean Squared Error: {mse}')
异常检测
-
选择算法:
- Isolation Forest、One-Class SVM。
-
异常检测:
from sklearn.ensemble import IsolationForest iso_forest = IsolationForest(contamination=0.05) data['anomaly'] = iso_forest.fit_predict(data[features]) plt.figure(figsize=(14, 6)) plt.scatter(data['时间'], data['实际发电功率(mw)'], c=data['anomaly'], cmap='viridis') plt.title('异常检测') plt.xlabel('时间') plt.ylabel('功率 (MW)') plt.show()
实际应用案例
-
电力系统调度优化:
- 利用预测结果优化电网调度,减少弃风弃光现象,提高能源利用率。
-
设备维护计划:
- 通过聚类分析和异常检测,提前预警潜在问题,制定合理的维护计划,降低维修成本。
-
政策制定支持:
- 提供数据支持给政策制定者,辅助他们更好地理解和应对新能源发展的挑战与机遇。
注意事项
- 季节性和趋势:考虑到风电和光伏发电受天气条件影响较大,因此在建模时要特别注意数据中的季节性变化和长期趋势。
- 外部变量:引入气象预报数据作为额外的输入特征,可以显著提升预测精度。
- 模型更新:随着新数据的到来,定期重新训练模型以适应最新的市场和技术环境。
好的,让我们一步步详细地探讨如何使用这些数据进行预测和数据分析。我们将从数据预处理开始,然后进行特征工程、模型选择、模型训练和评估,最后进行预测和结果分析。
1. 数据加载与预处理
加载数据
首先,我们需要加载数据并进行初步的预处理。
import pandas as pd
# 假设数据存储在CSV文件中
data = pd.read_csv('wind_solar_data.csv', parse_dates=['时间'])
# 查看数据前几行以了解其结构
print(data.head())
数据清洗
处理缺失值、异常值,并转换日期时间字段为适当的格式。
# 检查缺失值
print(data.isnull().sum())
# 处理缺失值
data.fillna(method='ffill', inplace=True)
# 确保时间戳是datetime类型
data['时间'] = pd.to_datetime(data['时间'])
特征工程
创建新的特征,如日均功率、最大最小功率差值等。
# 创建新特征:日均功率输出
data['日均功率'] = data.groupby(data['时间'].dt.date)['实际发电功率(mw)'].transform('mean')
# 创建新特征:功率差值
data['功率差值'] = data['实际发电功率(mw)'].diff()
# 创建新特征:风速平均值
data['风速平均值'] = data[['测风塔10m风速(m/s)', '测风塔30m风速(m/s)', '测风塔50m风速(m/s)']].mean(axis=1)
2. 数据分析与可视化
描述性统计
查看数据的基本统计信息。
print(data.describe())
时间序列可视化
绘制时间序列图,观察发电功率的变化趋势。
import matplotlib.pyplot as plt
plt.figure(figsize=(14, 6))
plt.plot(data['时间'], data['实际发电功率(mw)'], label='实际发电功率')
plt.title('实际发电功率随时间变化')
plt.xlabel('时间')
plt.ylabel('功率 (MW)')
plt.legend()
plt.show()
3. 预测建模
数据划分
将数据划分为训练集和测试集。
from sklearn.model_selection import train_test_split
# 选择特征和目标变量
features = ['测风塔10m风速(m/s)', '测风塔30m风速(m/s)', '测风塔50m风速(m/s)', '测风塔10m风向(°)', '测风塔30m风向(°)', '测风塔50m风向(°)', '温度(°C)', '气压(hPa)', '测光']
target = '实际发电功率(mw)'
X = data[features]
y = data[target]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=False)
特征缩放
对数值型特征进行标准化或归一化。
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
选择模型
选择合适的预测模型,这里我们选择随机森林和Prophet作为示例。
from sklearn.ensemble import RandomForestRegressor
from fbprophet import Prophet
# 随机森林模型
rf_model = RandomForestRegressor(n_estimators=100, random_state=42)
rf_model.fit(X_train_scaled, y_train)
# Prophet模型
prophet_model = Prophet()
prophet_model.fit(pd.DataFrame({'ds': data['时间'], 'y': data['实际发电功率(mw)']}))
模型评估
评估模型的性能。
from sklearn.metrics import mean_squared_error, mean_absolute_error
# 随机森林模型预测
y_pred_rf = rf_model.predict(X_test_scaled)
mse_rf = mean_squared_error(y_test, y_pred_rf)
mae_rf = mean_absolute_error(y_test, y_pred_rf)
print(f'Random Forest MSE: {mse_rf}, MAE: {mae_rf}')
# Prophet模型预测
future = prophet_model.make_future_dataframe(periods=len(X_test), freq='15T')
forecast = prophet_model.predict(future)
y_pred_prophet = forecast['yhat'].values[-len(y_test):]
mse_prophet = mean_squared_error(y_test, y_pred_prophet)
mae_prophet = mean_absolute_error(y_test, y_pred_prophet)
print(f'Prophet MSE: {mse_prophet}, MAE: {mae_prophet}')
4. 结果分析与可视化
预测结果可视化
绘制预测结果与实际值的对比图。
plt.figure(figsize=(14, 6))
plt.plot(data['时间'][-len(y_test):], y_test, label='实际发电功率')
plt.plot(data['时间'][-len(y_test):], y_pred_rf, label='随机森林预测')
plt.plot(data['时间'][-len(y_test):], y_pred_prophet, label='Prophet预测')
plt.title('预测结果与实际值对比')
plt.xlabel('时间')
plt.ylabel('功率 (MW)')
plt.legend()
plt.show()
5. 异常检测
异常检测
使用Isolation Forest进行异常检测。
from sklearn.ensemble import IsolationForest
iso_forest = IsolationForest(contamination=0.05)
data['anomaly'] = iso_forest.fit_predict(data[features])
plt.figure(figsize=(14, 6))
plt.scatter(data['时间'], data['实际发电功率(mw)'], c=data['anomaly'], cmap='viridis')
plt.title('异常检测')
plt.xlabel('时间')
plt.ylabel('功率 (MW)')
plt.show()
6. 实际应用案例
电力系统调度优化
利用预测结果优化电网调度,减少弃风弃光现象,提高能源利用率。
设备维护计划
通过聚类分析和异常检测,提前预警潜在问题,制定合理的维护计划,降低维修成本。


















 736
736

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









