







介绍
YOLOv11** 是一个较新的目标检测模型,而您提供的配置文件确实是为 YOLO 系列模型设计的。以下是对您提供的配置文件的中文开题介绍,基于 YOLOv11 的交通标志识别系统 的研究背景和意义。

1. 研究背景与意义
随着智能交通系统(Intelligent Transportation System, ITS)和自动驾驶技术的快速发展,交通标志识别(Traffic Sign Recognition, TSR)成为了计算机视觉领域的重要研究方向。交通标志是道路交通管理的重要组成部分,它们为驾驶员和自动驾驶系统提供了关键的交通规则、道路状况和安全提示信息。然而,在实际驾驶环境中,交通标志的识别面临诸多挑战,例如光照变化、天气条件(如雨雪、雾霾)、遮挡物以及交通标志的老化等。
传统的交通标志识别方法主要依赖于图像处理技术和机器学习算法,如边缘检测、颜色分割和模板匹配等。这些方法在特定环境下表现良好,但在复杂场景中往往难以达到较高的识别精度和鲁棒性。近年来,深度学习技术的快速发展为目标检测任务提供了新的解决方案,尤其是 YOLO(You Only Look Once)系列模型,以其高效、快速和准确的特点,在交通标志识别领域得到了广泛应用。
YOLOv11 作为 YOLO 系列的最新版本之一,继承了 YOLO 系列的高效性和实时性,同时通过改进网络结构、损失函数和数据增强策略,进一步提升了检测精度和鲁棒性。因此,基于 YOLOv11 的交通标志识别系统具有重要的研究价值和应用前景。
2. 研究目标
本研究的目标是设计并实现一个基于 YOLOv11 的交通标志识别系统,能够高效、准确地检测和识别道路上的交通标志。具体研究目标包括:
- 数据集构建与预处理:收集并整理交通标志数据集,对数据进行标注和增强,以适应 YOLOv11 模型的训练需求。
- 模型训练与优化:基于 YOLOv11 模型,在交通标志数据集上进行训练,并通过调整超参数、改进损失函数和数据增强策略,提升模型的检测精度和鲁棒性。
- 系统实现与测试:将训练好的模型部署到实际场景中,测试其在复杂环境下的性能,并对系统进行优化和改进。
3. 数据集与模型配置
根据您提供的配置文件,本研究将使用以下数据集和模型配置:
- 数据集路径:
path\to\your\dataset为数据集的根目录,包含训练集和验证集。- 训练集:
images\train,包含 128 张图像。 - 验证集:
images\val,包含 128 张图像。
- 训练集:
- 类别数量:
nc: 45,表示数据集中包含 45 种不同的交通标志类别。 - 类别名称:
names部分列出了 45 个类别的名称,例如pl80、p6、p5等,这些类别可能代表不同的交通标志类型(如限速标志、警告标志、指示标志等)。
4. 研究方法与技术路线
本研究将采用以下方法和技术路线:
- 数据集准备:
- 对交通标志图像进行标注,生成 YOLO 格式的标签文件(
.txt文件),包含每个交通标志的类别编号和边界框信息。 - 对数据集进行数据增强,如随机裁剪、旋转、缩放、颜色抖动等,以提升模型的泛化能力。
- 对交通标志图像进行标注,生成 YOLO 格式的标签文件(
- 模型训练:
- 使用 YOLOv11 的预训练权重进行迁移学习,加速模型收敛。
- 在训练过程中,采用动态学习率调整策略,并结合数据增强技术,防止模型过拟合。
- 模型评估与优化:
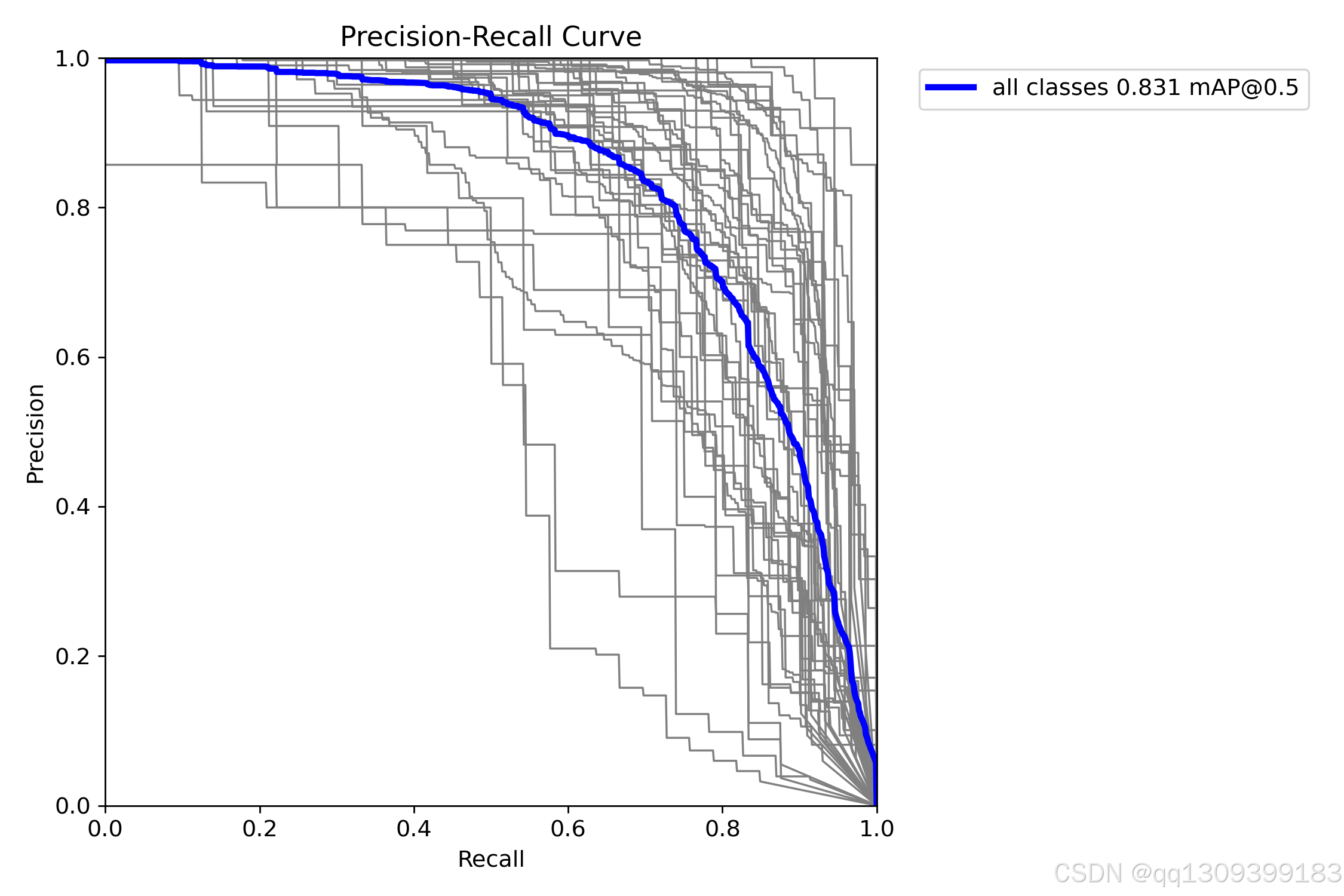
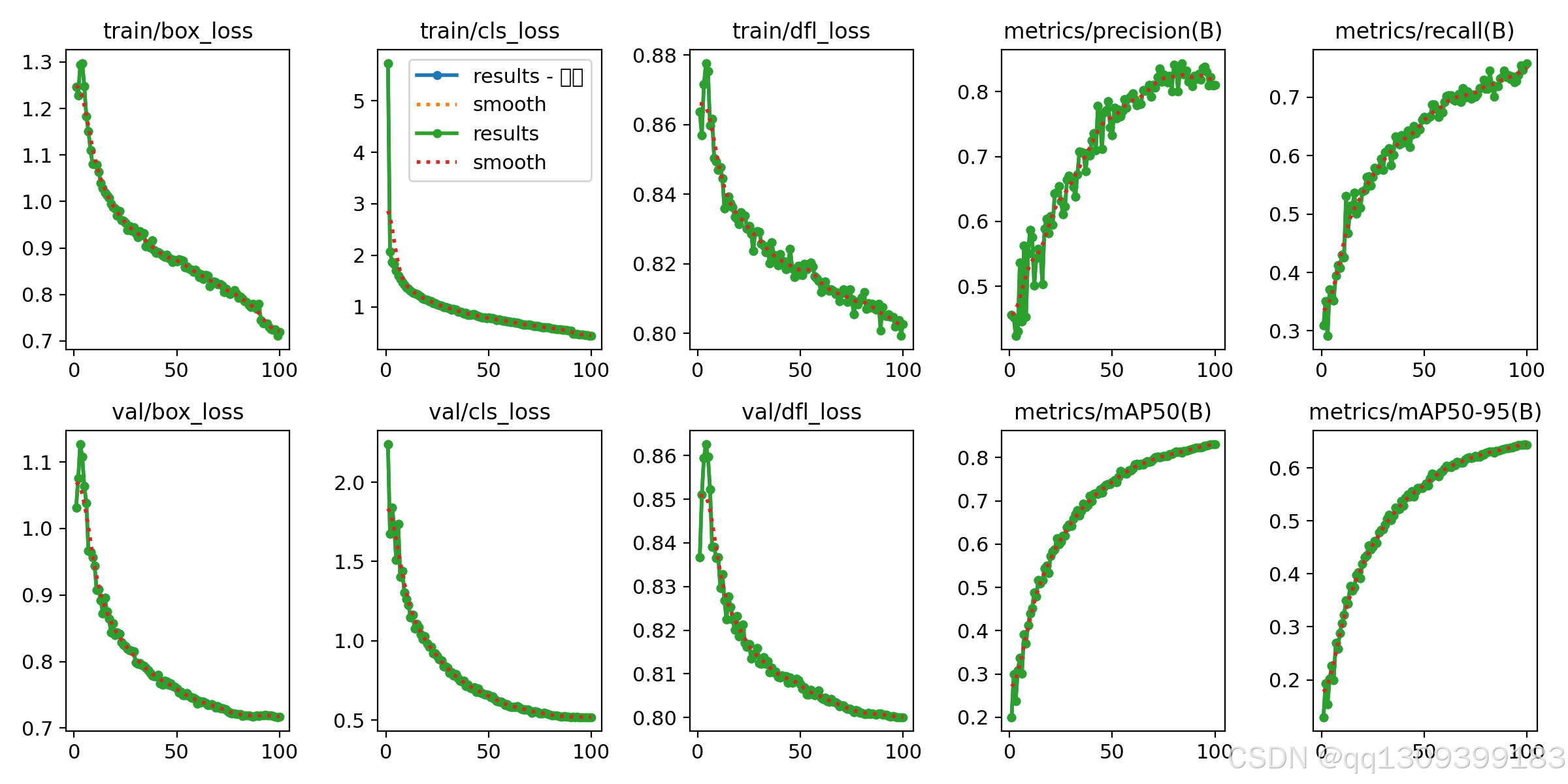
- 使用验证集对模型进行评估,计算模型的精度(Precision)、召回率(Recall)和平均精度(mAP)等指标。
- 通过调整模型结构、损失函数和超参数,进一步优化模型性能。
- 系统部署:
- 将训练好的模型部署到实际场景中,测试其在复杂环境下的实时性和鲁棒性。
- 对系统进行优化,确保其能够在嵌入式设备或移动设备上高效运行。
5. 研究意义与应用价值
本研究的意义和应用价值主要体现在以下几个方面:
- 提升交通标志识别的精度和鲁棒性:通过引入 YOLOv11 模型,能够有效应对复杂环境下的交通标志识别任务,提升检测精度和鲁棒性。
- 推动自动驾驶技术的发展:交通标志识别是自动驾驶系统的关键技术之一,本研究的成果可以为自动驾驶系统提供可靠的环境感知能力。
- 促进智能交通系统的应用:交通标志识别系统可以应用于智能交通监控、交通违规检测等领域,为交通管理部门提供技术支持。
6. 研究计划

本研究计划分为以下几个阶段:
- 第一阶段(1-2 个月):数据集收集与预处理,完成数据标注和数据增强。
- 第二阶段(3-4 个月):模型训练与优化,完成 YOLOv11 模型的训练和调优。
- 第三阶段(5-6 个月):系统实现与测试,将模型部署到实际场景中,并进行性能测试和优化。
- 第四阶段(7-8 个月):撰写论文与总结,整理研究成果并撰写论文。
path: path\to\your\dataset # dataset root dir
train: images\\train # train images (relative to 'path') 128 images
val: images\\val # val images (relative to 'path') 128 images
nc: 45
names:
0: pl80
1: p6
2: p5
3: pm55
4: pl60
5: ip
6: p11
7: i2r
8: p23
9: pg
10: il80
11: ph4
12: i4
13: pl70
14: pne
15: ph4.5
16: p12
17: p3
18: pl5
19: w13
20: i4l
21: pl30
22: p10
23: pn
24: w55
25: p26
26: p13
27: pr40
28: pl20
29: pm30
30: pl40
31: i2
32: pl120
33: w32
34: ph5
35: il60
36: w57
37: pl100
38: w59
39: il100
40: p19
41: pm20
42: i5
43: p27
44: pl50
7. 训练
python train.py --data path\to\your\dataset\config.yaml --weights yolov5s.pt --epochs 100
基于 YOLOv11 的交通标志识别系统具有重要的研究价值和应用前景。通过本研究,我们希望能够为交通标志识别任务提供一种高效、准确的解决方案,并为自动驾驶和智能交通系统的发展提供技术支持。


















 447
447

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









