







博主的学习网站 : https://bigdataboy.cn/
分为两步:
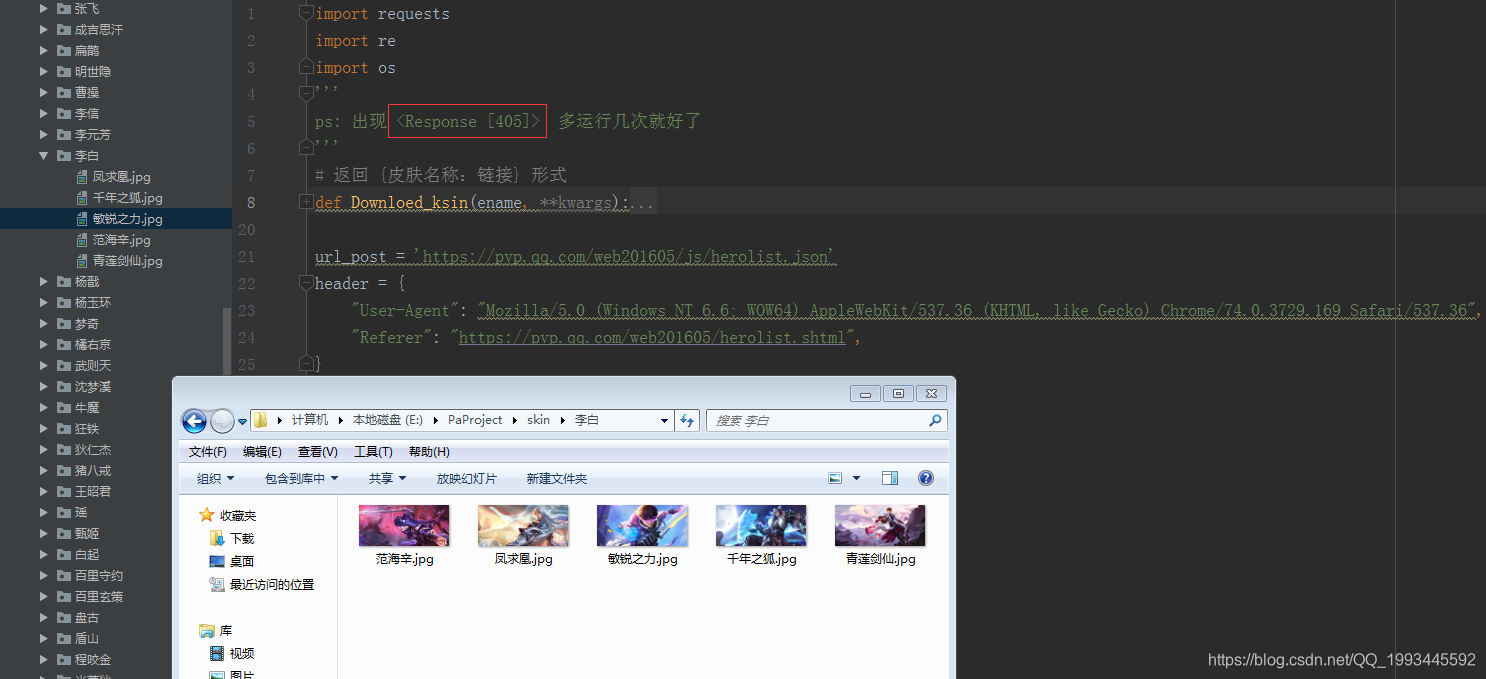
1.找到皮肤图片的地址
函数只需要传入英雄编号即可返回 {皮肤名称:链接地址} 形式
def Downloed_ksin(ename, **kwargs):
# 英雄详情页
url = 'https://pvp.qq.com/web201605/herodetail/' + ename + '.shtml'
html = session.get(url=url, headers=header)
html.encoding = html.apparent_encoding
# 获取皮肤名称
skin_name = re.search(r'data-imgname="(.*?)">', html.text).group(1).split('|')
infor = {}
for num in range(len(skin_name)):
infor[skin_name[num]] = 'https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/' + ename + '/' + ename + '-bigskin-' + str(num+1) + '.jpg'
# 返回 {皮肤名称:链接} 形式
return infor
2.下载图片
遍历函数返回值 创建目录 二进制 写入
os.makedirs('skin' + '/' + str(cname))#创建目录
for v, k in skin_url.items():
img = requests.get(url=k, headers=header).content
with open('skin' + '/' + str(cname) + '/' + v + '.jpg', 'wb+') as imgfile:
imgfile.write(img)
完整代码:
import requests
import re
import os
'''
ps: 出现 <Response [405]> 多运行几次就好了
'''
def Downloed_ksin(ename, **kwargs):
# 英雄详情页
url = 'https://pvp.qq.com/web201605/herodetail/' + ename + '.shtml'
html = session.get(url=url, headers=header)
html.encoding = html.apparent_encoding
# 获取皮肤名称
skin_name = re.search(r'data-imgname="(.*?)">', html.text).group(1).split('|')
infor = {}
for num in range(len(skin_name)):
infor[skin_name[num]] = 'https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/' + ename + '/' + ename + '-bigskin-' + str(num+1) + '.jpg'
# 返回 {皮肤名称:链接} 形式
return infor
url_post = 'https://pvp.qq.com/web201605/js/herolist.json'
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.6; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36",
"Referer": "https://pvp.qq.com/web201605/herolist.shtml",
}
session = requests.session()
html = session.post(url=url_post, headers=header)
print(html)
for property in html.json():
ename = str(property["ename"])#获取英雄编号
cname = property['cname']#获取英雄名称
print(cname)
skin_url = Downloed_ksin(ename)#得到 {皮肤名称:链接} 形式
os.makedirs('skin' + '/' + str(cname))#创建目录
for v, k in skin_url.items():
img = requests.get(url=k, headers=header).content
with open('skin' + '/' + str(cname) + '/' + v + '.jpg', 'wb+') as imgfile:
imgfile.write(img)

















 3145
3145

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









