






总体实现要求
利用Python编写爬虫程序,从招聘网站上爬取数据,使用
Flume监控目录将数据存入到HDFS中,将存入的数据使用Hive进行的数据清洗,结果使用Sqoop存入MySQL,最后将分析的结果做数据可视化。
Scrapy 爬取数据数据
目标网站:51job.com
岗位名称:['数据分析', '大数据开发工程师', '数据采集','Python开发工程师']
爬取范围:全国
爬虫源码:点我
数据爬取结果

创建 Hive 处理数据表
Hive 创建的只是数据映射成的表规则

Flume 监控目录上传数据
使用Flume监控目录上传数据到 Hive 建表的路径下

上传成功

使用 Hive 处理数据
在Hive中查看数据

Hive 分析数据
(1) 分析“数据分析”、“大数据开发工程师”、“数据采集”等岗位的平均工资、最高工资、最低工资
insert overwrite directory '/res/one'
row format delimited fields terminated by '\t'
select "数据分析" as job_name,
round(avg((job_wages[0] + job_wages[1])/2),2) as job_mean,
min(job_wages[0]) as job_min,
max(job_wages[1]) as job_max
from jobdb.job
where job_name like '%数据分析%'
union
select "大数据开发工程师" as job_name,
round(avg((job_wages[0] + job_wages[1])/2),2) as job_mean,
min(job_wages[0]) as job_min,
max(job_wages[1]) as job_max
from jobdb.job
where job_name like '%大数据开发工程师%'
union
select "数据采集" as job_name,
round(avg((job_wages[0] + job_wages[1])/2),2) as job_mean,
min(job_wages[0]) as job_min,
max(job_wages[1]) as job_max
from jobdb.job
where job_name like '%数据采集%';

(2) 分析“数据分析”、“大数据开发工程师”、“数据采集”等大数据相关岗位在成都、北京、上海、广州、深圳的岗位数
insert overwrite directory '/res/two'
row format delimited fields terminated by '\t'
select
"数据分析" as job_name,
cd.chengdu as chengdu,
bj.beijing as beijing,
sh.shanghai as shanghai,
gz.guangzhou as guangzhou,
sz.shenzhen as shenzhen
from
(select
"数据分析" as job_name,
count(1) as chengdu
from jobdb.job
where job_name like '%数据分析%' and work_place like '%成都%') as cd
join
(select
"数据分析" as job_name,
count(1) as beijing
from jobdb.job
where job_name like '%数据分析%' and work_place like '%北京%') as bj
on cd.job_name = bj.job_name
join
(select
"数据分析" as job_name,
count(1) as shanghai
from jobdb.job
where job_name like '%数据分析%' and work_place like '%上海%') as sh
on bj.job_name = sh.job_name
join
(select
"数据分析" as job_name,
count(1) as guangzhou
from jobdb.job
where job_name like '%数据分析%' and work_place like '%广州%') as gz
on sh.job_name = gz.job_name
join
(select
"数据分析" as job_name,
count(1) as shenzhen
from jobdb.job
where job_name like '%数据分析%' and work_place like '%深圳%') as sz
on gz.job_name = sz.job_name
union
select
"大数据开发工程师" as job_name,
cd.chengdu as chengdu,
bj.beijing as beijing,
sh.shanghai as shanghai,
gz.guangzhou as guangzhou,
sz.shenzhen as shenzhen
from
(select
"大数据开发工程师" as job_name,
count(1) as chengdu
from jobdb.job
where job_name like '%大数据开发工程师%' and work_place like '%成都%') as cd
join
(select
"大数据开发工程师" as job_name,
count(1) as beijing
from jobdb.job
where job_name like '%大数据开发工程师%' and work_place like '%北京%') as bj
on cd.job_name = bj.job_name
join
(select
"大数据开发工程师" as job_name,
count(1) as shanghai
from jobdb.job
where job_name like '%大数据开发工程师%' and work_place like '%上海%') as sh
on bj.job_name = sh.job_name
join
(select
"大数据开发工程师" as job_name,
count(1) as guangzhou
from jobdb.job
where job_name like '%大数据开发工程师%' and work_place like '%广州%') as gz
on sh.job_name = gz.job_name
join
(select
"大数据开发工程师" as job_name,
count(1) as shenzhen
from jobdb.job
where job_name like '%大数据开发工程师%' and work_place like '%深圳%') as sz
on gz.job_name = sz.job_name
union
select
"数据采集" as job_name,
cd.chengdu as chengdu,
bj.beijing as beijing,
sh.shanghai as shanghai,
gz.guangzhou as guangzhou,
sz.shenzhen as shenzhen
from
(select
"数据采集" as job_name,
count(1) as chengdu
from jobdb.job
where job_name like '%数据采集%' and work_place like '%成都%') as cd
join
(select
"数据采集" as job_name,
count(1) as beijing
from jobdb.job
where job_name like '%数据采集%' and work_place like '%北京%') as bj
on cd.job_name = bj.job_name
join
(select
"数据采集" as job_name,
count(1) as shanghai
from jobdb.job
where job_name like '%数据采集%' and work_place like '%上海%') as sh
on bj.job_name = sh.job_name
join
(select
"数据采集" as job_name,
count(1) as guangzhou
from jobdb.job
where job_name like '%数据采集%' and work_place like '%广州%') as gz
on sh.job_name = gz.job_name
join
(select
"数据采集" as job_name,
count(1) as shenzhen
from jobdb.job
where job_name like '%数据采集%' and work_place like '%深圳%') as sz
on gz.job_name = sz.job_name

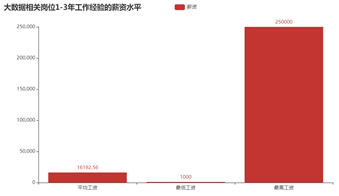
(3) 分析大数据相关岗位1-3年工作经验的薪资水平(平均工资、最高工资、最低工资)
insert overwrite directory '/res/three'
row format delimited fields terminated by '\t'
select
'大数据相关岗位1-3年工作经验' as job_name,
round(avg((job_wages[0] + job_wages[1])/2),2) as job_mean,
min(job_wages[0]) as job_min,
max(job_wages[1]) as job_max
from jobdb.job
where job_name like '%大数据%' and work_experience REGEXP '.*[123].*';

查看处理完成的数据
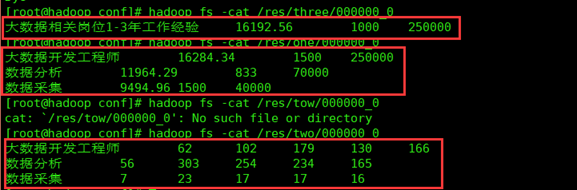
使用 Sqoop 传输
# HDFS 传输到 MySQL 第一张表
sqoop export \
--connect 'jdbc:mysql://127.0.0.1:3306/shixun?useUnicode=true&characterEncoding=utf-8' \
--username 'root' \
--password '123456' \
--table 'one' \
--export-dir '/res/one/000000_0' \
--fields-terminated-by '\t' \
-m 1
# HDFS 传输到 MySQL 第二张表
sqoop export \
--connect 'jdbc:mysql://127.0.0.1:3306/shixun?useUnicode=true&characterEncoding=utf-8' \
--username 'root' \
--password '123456' \
--table 'two' \
--export-dir '/res/two/000000_0' \
--fields-terminated-by '\t' \
-m 1
# HDFS 传输到 MySQL 第三张表
sqoop export \
--connect 'jdbc:mysql://127.0.0.1:3306/shixun?useUnicode=true&characterEncoding=utf-8' \
--username 'root' \
--password '123456' \
--table 'three' \
--export-dir '/res/three/000000_0' \
--fields-terminated-by '\t' \
-m 1

传输MySQL完成

最终结果可视化
(1) 分析“数据分析”、“大数据开发工程师”、“数据采集”等岗位的平均工资、最高工资、最低工资

(2) 分析“数据分析”、“大数据开发工程师”、“数据采集”等大数据相关岗位在成都、北京、上海、广州、深圳的岗位数
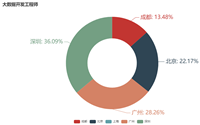
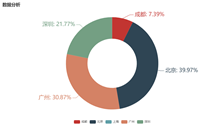
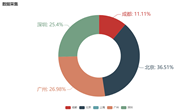
(3) 分析大数据相关岗位1-3年工作经验的薪资水平(平均工资、最高工资、最低工资)















 3155
3155











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









