









声明:文章是从本人公众号中复制而来,因此,想最新最快了解各类智能优化算法及其改进的朋友,可关注我的公众号:强盛机器学习,不定期会有很多免费代码分享~
目录
以往XGBoost只能在Python中运行,虽然运行较快,但是无法结合自己的智能优化算法进行结合,因为大多数智能优化算法都是基于Matlab平台开发的,如果能够利用Matlab实现XGBoost,那么结合24年新算法或自己改进的算法将会非常方便,也会有更多的创新点!
因此,今天给大家带来一期PSO-XGBoost实现时间序列预测的代码!最关键的是,XGBoost模型中附赠了五折交叉验证防止模型过拟合!
学会这一篇,你也可以自己替换任何优化算法优化XGBoost!
原理简介与流程图
以下原理简介是为了方便新手小白了解为什么可以选取这两个算法,以及为什么要用PSO优化XGBoost实现时间序列预测,没有任何公式,可放心阅读!
PSO算法是一种基于模拟鸟类觅食行为的群体智能优化算法。在有限维度的搜索空间内,将所有觅食的鸟类简化为一个粒子,将寻找的食物作为优化所得的最优解。经过每次寻优过程的迭代,找出每个粒子在时刻所对应的最优位置以及对应的种群最优位置,即Pbest与Gbest。
XGBoost算法基于boosting的算法,是目前最成功的机器学习算法之一,其特点包括具有较高精度,运行速率快且能防止过拟合。它是在Gradient Boosting Decision Tree(GBDT)算法的基础上优化而来,具有优秀的性能和速度。
XGBoost模型的主要超参数包括学习率(learning rate)、树的最大深度(max depth)、最大迭代次数(Max Iteration)。因为参数较多,且调参过程投机性、 随机性较大、计算量较大,所以采用粒子群优化算法和XGBoost模型相结合,通过PSO算法优化模型超参数的取值,减少参数选择过程中的随机性并提高计算速率,以此来提高模型的预测性能。
因此,流程图可绘制如下:
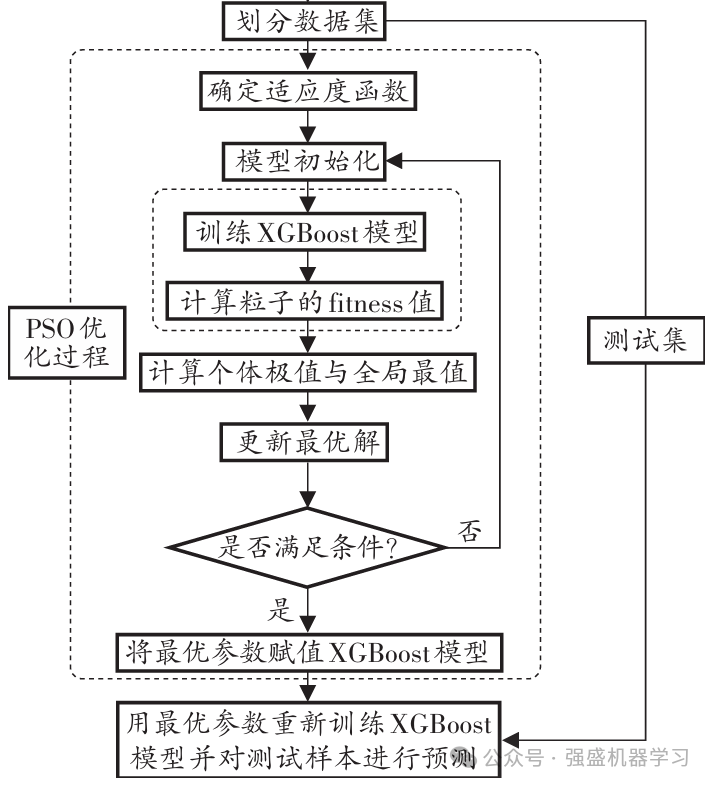
1)设置时间步长,将数据集的70%作为训练集,30%作为测试集;
2)初始化粒子及其速度,将学习率、树的最大深度、最大迭代次数设为代求参数,将RMSE作为适应度数值。
3)更新粒子速度与位置,计算其适应度值,更新个体最优值与全局最优值,并在训练集中进行五折交叉验证,从而防止过拟合;
4)判断是否满足终止条件,若不满足则继续更新个体最优值与全局最优值;若满足则输出最优参数;
5)选取最优参数组合,构建参数优化的XGBoost回归模型。
数据格式与替换方法
本期推文采用的是经典的Excel时间序列数据集,非常方便!即代码中所用数据为测试数据,无实际含义,其中第一列为时间(可放可不放,非必须),第二列为数据。
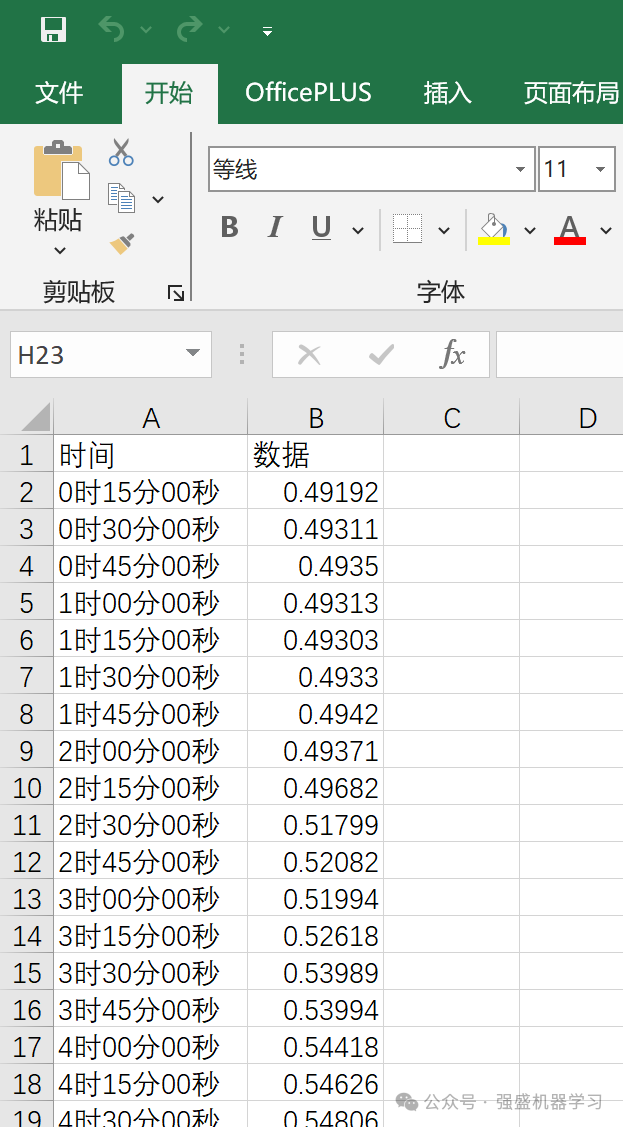
替换自己的数据集时,只需替换第二列数据即可,时间一列无需输入(因为代码不会识别时间),无需更改代码直接替换数据即可,非常方便,适合新手小白!
结果展示
这里设置训练集比例为70%,测试集比例为30%,种群数量为6,优化算法迭代次数为20,得到的结果如下所示(以上参数均可自行更改):
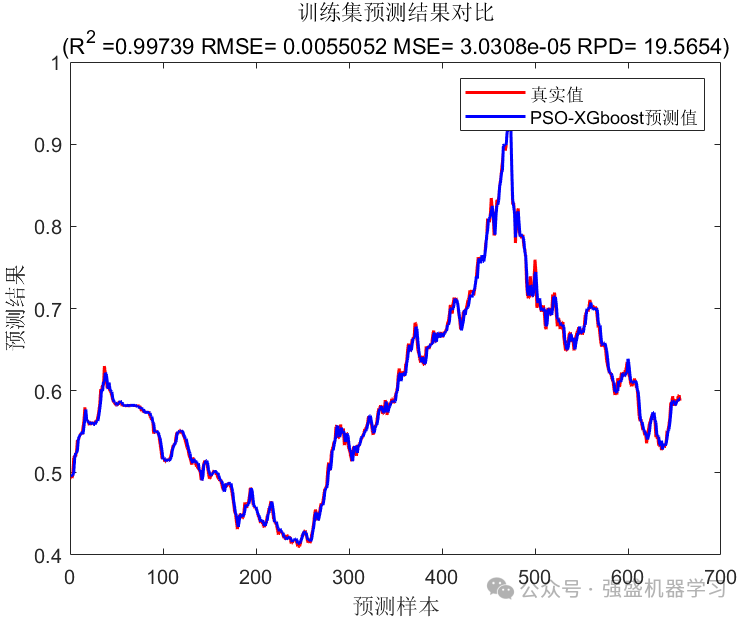
训练集预测结果图:
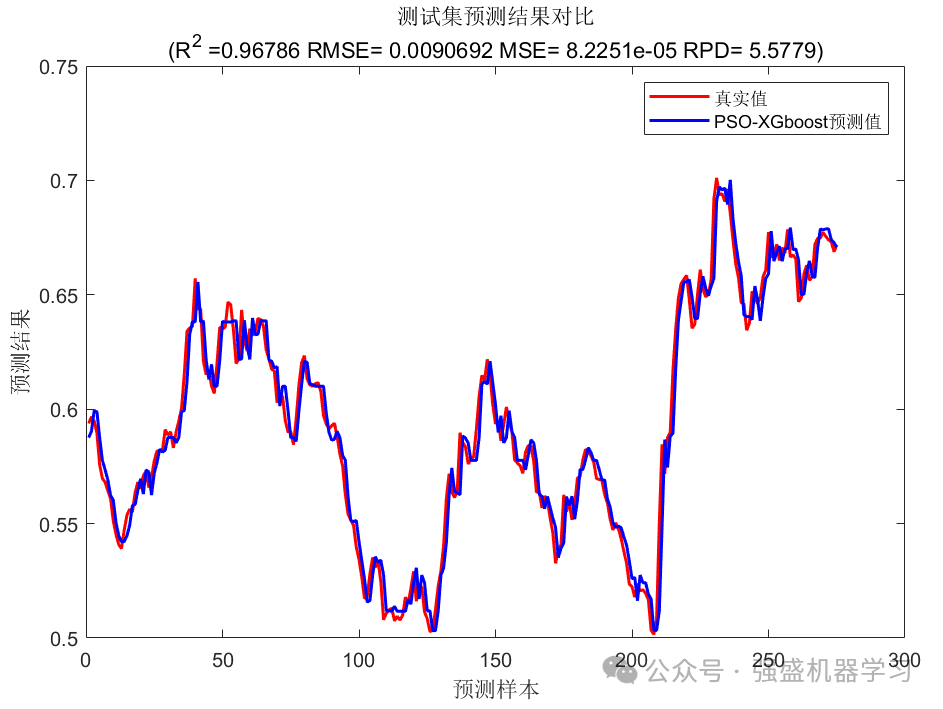
测试集预测结果图:
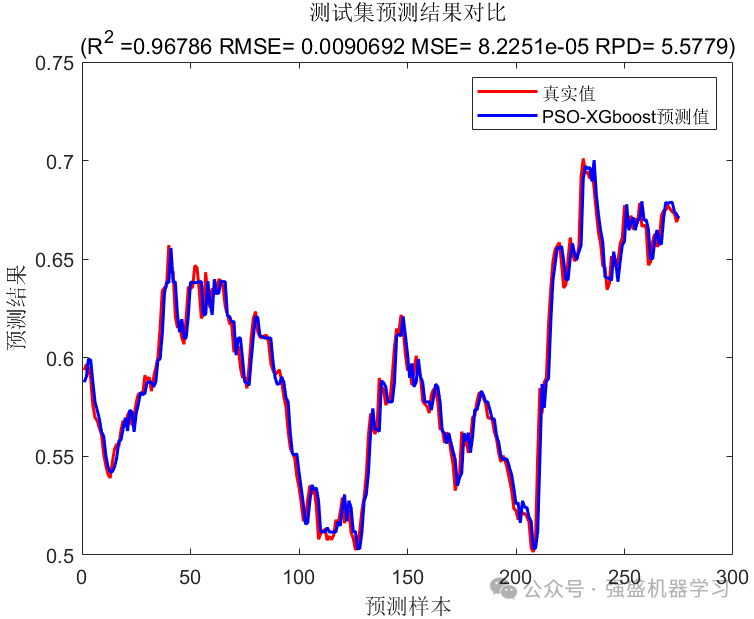
误差直方图:
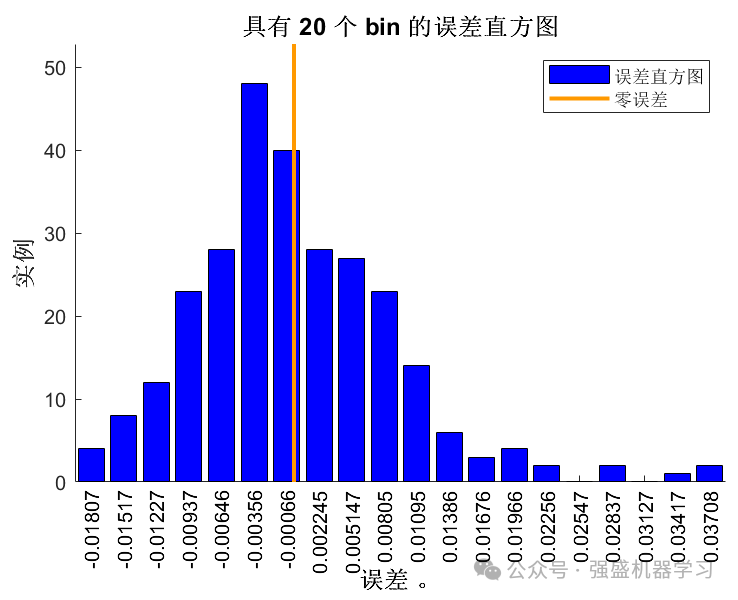
迭代曲线图:
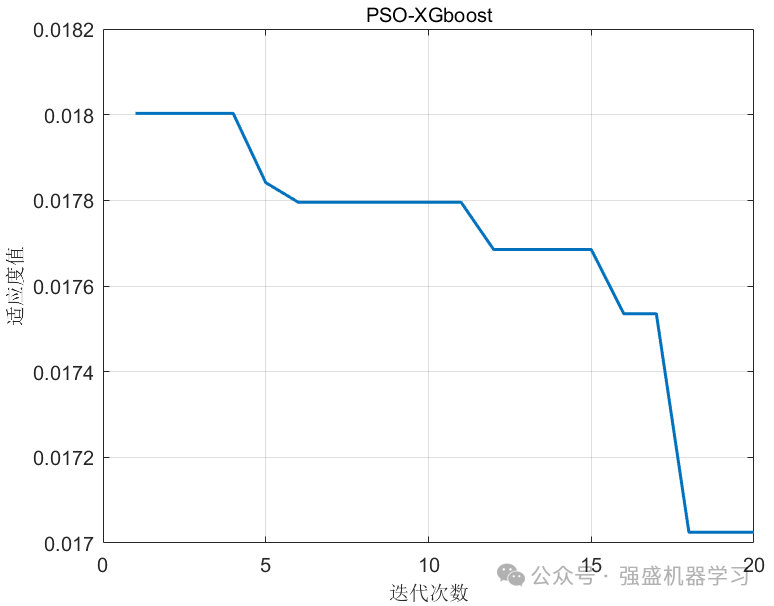
线性拟合图:
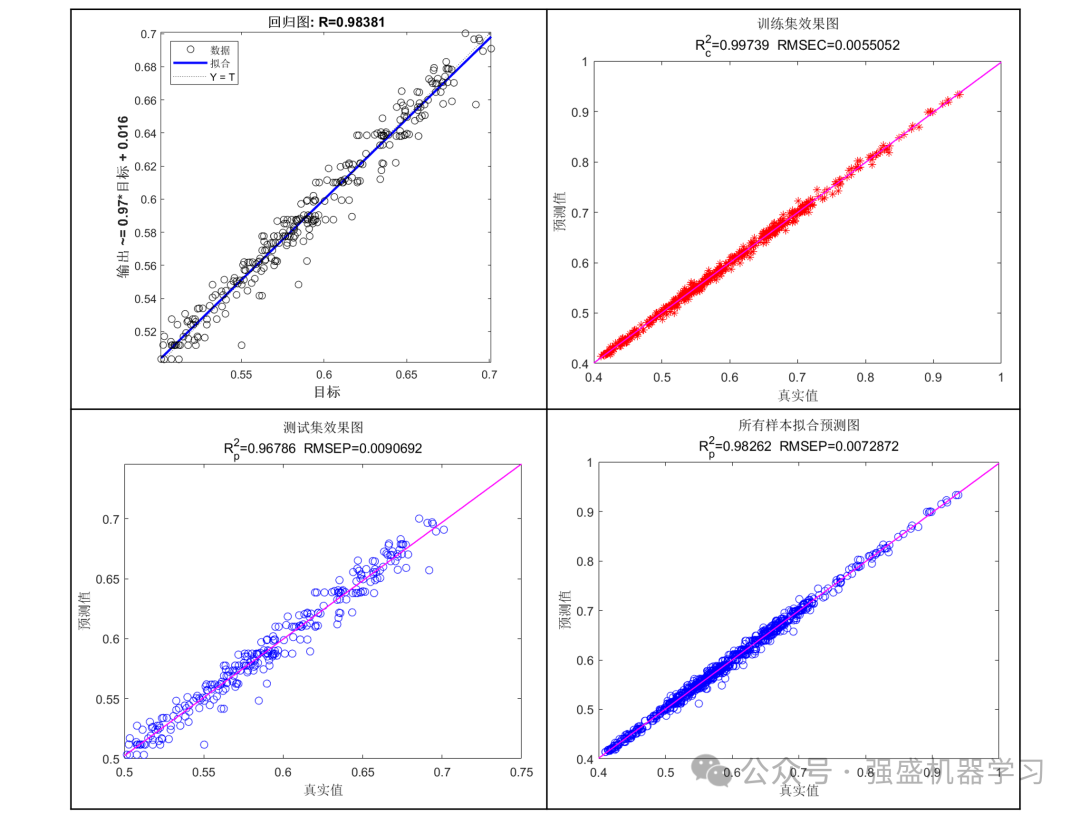
误差指标结果显示:
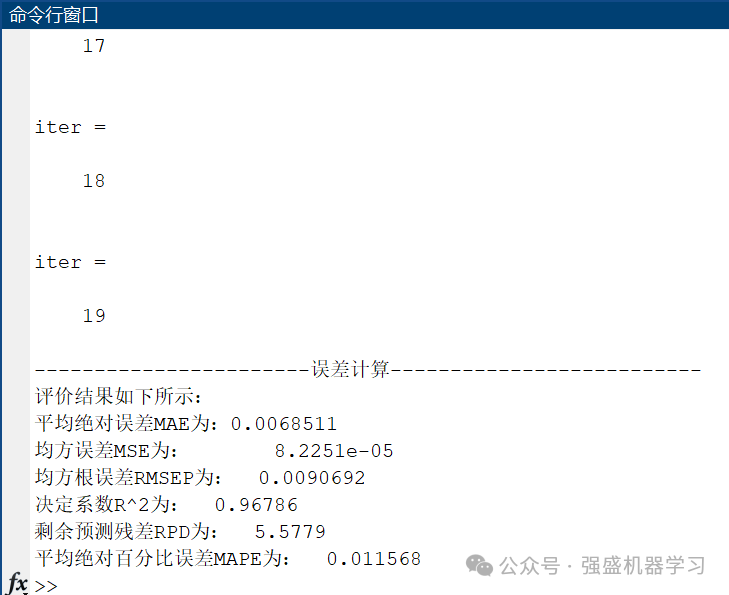
可以看到,真实值与预测值效果非常接近,且训练集和测试集误差不大,有效避免了过拟合的发生!
注意!Matlab实现XGBoost模型需要安装C++编译器,过程非常简单,文件夹内也附带了教程,不用担心!关键你的Matlab需要正版,没有的小伙伴可以去淘宝买一个,也就十几块,非常便宜!
部分代码展示
%% 清空环境变量
warning off % 关闭报警信息
close all % 关闭开启的图窗
clear % 清空变量
clc % 清空命令行
%% 导入数据(时间序列的单列数据)
result = xlsread('数据集.xlsx');
%% 数据分析
num_samples = length(result); % 样本个数
kim = 6; % 延时步长(kim个历史数据作为自变量)
zim = 1; % 跨zim个时间点进行预测
%% 划分数据集
for i = 1: num_samples - kim - zim + 1
res(i, :) = [reshape(result(i: i + kim - 1), 1, kim), result(i + kim + zim - 1)];
end
%% 数据集分析
outdim = 1; % 最后一列为输出
num_size = 0.7; % 训练集占数据集比例
num_train_s = round(num_size * num_samples); % 训练集样本个数
f_ = size(res, 2) - outdim; % 输入特征维度
%% 划分训练集和测试集
P_train = res(1: num_train_s, 1: f_)';
T_train = res(1: num_train_s, f_ + 1: end)';
M = size(P_train, 2);
P_test = res(num_train_s + 1: end, 1: f_)';
T_test = res(num_train_s + 1: end, f_ + 1: end)';
N = size(P_test, 2);
%% 数据归一化
[p_train, ps_input] = mapminmax(P_train, 0, 1);
p_test = mapminmax('apply', P_test, ps_input);
[t_train, ps_output] = mapminmax(T_train, 0, 1);
t_test = mapminmax('apply', T_test, ps_output);
%% 数据转置 为适应模型的建立
p_train = p_train'; p_test = p_test';
t_train = t_train'; t_test = t_test';
%% 参数设置
fun = @getObjValue; % 目标函数
dim = 3; % 优化参数个数
lb = [100, 3, 0.0001]; % 优化参数目标下限(最大迭代次数,深度,学习率)
ub = [800, 10, 0.1]; % 优化参数目标上限(最大迭代次数,深度,学习率)
SearchAgents_no = 6; % 种群数量
Max_iteration = 20; % 最大迭代次数
params.objective = 'reg:linear'; % 回归函数
%% 优化算法
[Best_score ,Best_pos, curve] = PSO(SearchAgents_no, Max_iteration, lb, ub, dim, fun);可以看到,代码注释非常清晰,也方便大家换成自己的算法!
完整代码获取
本文为时间序列单列预测模型,如果想要多变量回归或分类预测可售前后台私信我免费更换~
如果完整代码,可点击下方小卡片,再后台回复关键词:
PSOXGB
其他更多需求或想要的代码均可点击下方小卡片,再后台私信,看到后会秒回~
更多代码链接:更多代码链接















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









