







论文作者:Yike Liu,Jianhui Zhang,Haipeng Li,Shuaicheng Liu,Bing Zeng
作者单位:
论文链接:http://arxiv.org/abs/2504.12222v1
内容简介:
1)方向:视频去模糊
2)应用:视频去模糊
3)背景:尽管当前的视频去模糊方法取得了显著进展,但它们通常忽略了两个重要的先验信息来源:(1)视频编解码中生成的运动矢量(MVs)与残差信息(CRs),可作为高效的帧间对齐与纹理线索;(2)预训练扩散生成模型中蕴含的丰富现实世界知识,这些潜力尚未被充分利用。
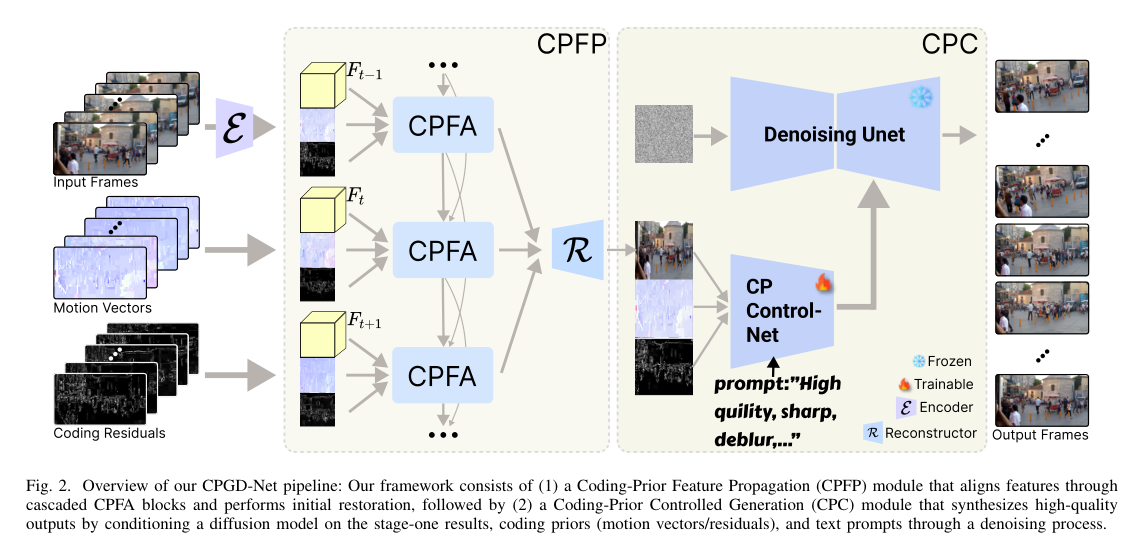
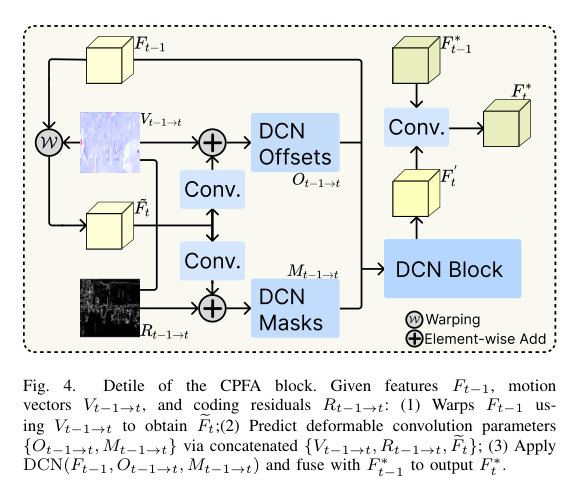
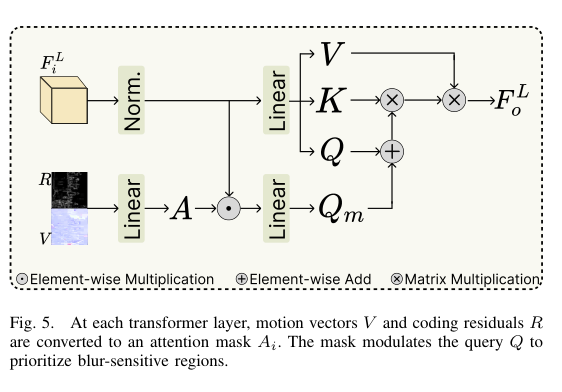
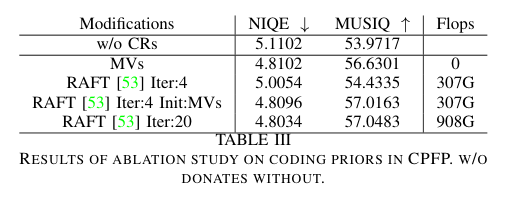
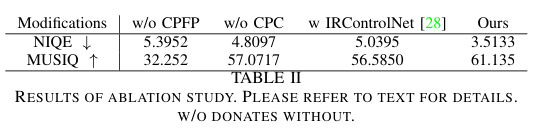
4)方法:本文提出一种新的两阶段框架 CPGDNet,结合了编码先验与生成式先验以实现高质量的视频去模糊。第一阶段是 编码先验特征传播模块(CPFP),利用运动矢量进行帧对齐,使用编码残差生成注意力掩码,解决运动误差和纹理变化问题。第二阶段是 编码先验控制生成模块(CPC),将编码先验引入预训练的扩散模型中,引导其增强关键区域并合成真实细节,从而提升去模糊效果。
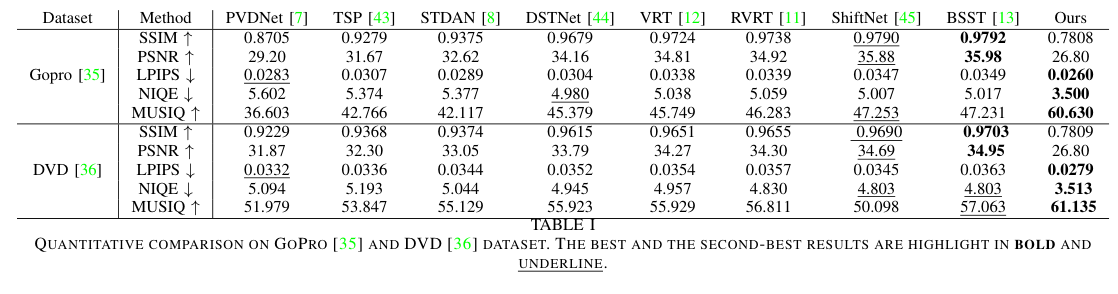
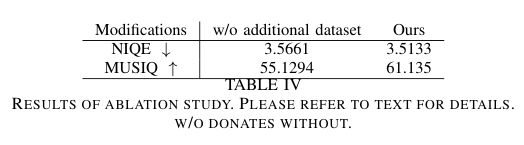
5)结果:实验结果显示,CPGDNet 在感知质量方面实现了业界领先的表现,在图像质量评价指标(IQA)上最多提升了30%。此外,作者将开放源码及包含编码先验增强的数据集,为后续研究提供资源支持。


























 6378
6378

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











