







前言
小编给大家编写了一个爬取小说的源码,这里分享给大家学习。
👉 小编已经为大家准备好了完整的代码和完整的Python学习资料,朋友们如果需要可以扫描下方CSDN官方认证二维码或者点击链接免费领取【保证100%免费】

一、小说下载
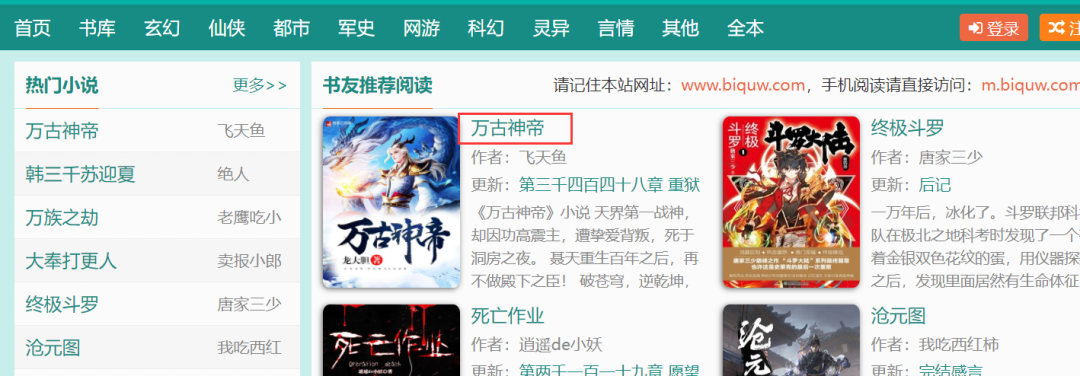
如果你想下载该网站上的任意一本小说的话,直接点击链接进去,如下图所示。
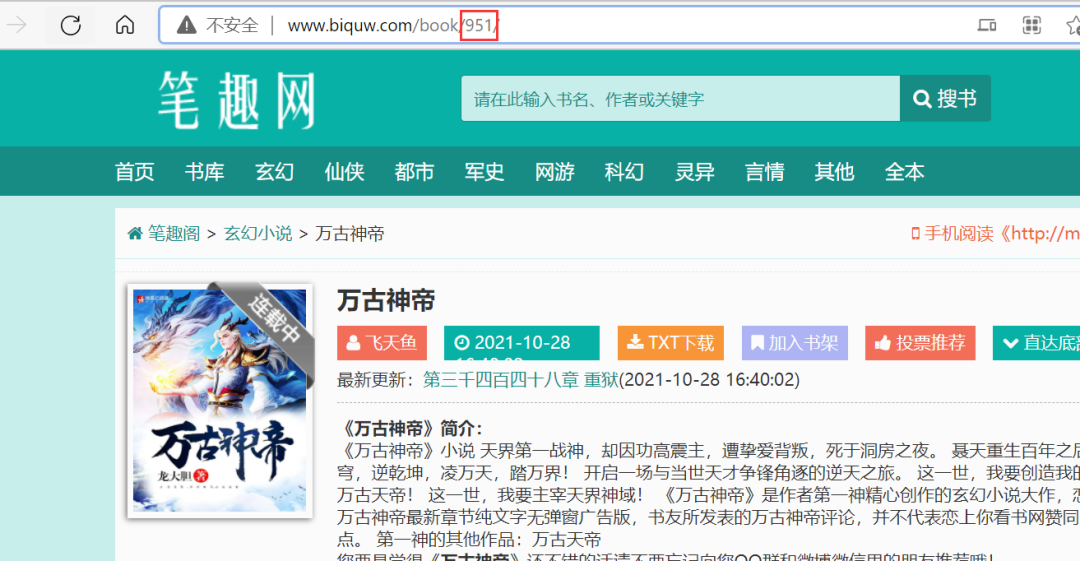
只要将URL中的这个数字拿到就可以了,比方说这里是951,那么这个数字代表的就是这本书的书号,在后面的代码中可以用得到的。
二、具体实现
这里直接丢大佬的代码了,如下所示:
# coding: utf-8
'''
笔趣网小说下载
仅限用于研究代码
勿用于商业用途
请于24小时内删除
'''
import requests
import os
from bs4 import BeautifulSoup
import time
def book_page_list(book_id):
'''
通过传入的书号bookid,获取此书的所有章节目录
:param book_id:
:return: 章节目录及章节地址
'''
url = 'http://www.biquw.com/book/{}/'.format(book_id)
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36'}
response = requests.get(url, headers)
response.encoding = response.apparent_encoding
response = BeautifulSoup(response.text, 'lxml')
booklist = response.find('div', class_='book_list').find_all('a')
return booklist
def book_page_text(bookid, booklist):
'''
通过书号、章节目录,抓取每一章的内容并存档
:param bookid:str
:param booklist:
:return:None
'''
try:
for book_page in booklist:
page_name = book_page.text.replace('*', '')
page_id = book_page['href']
time.sleep(3)
url = 'http://www.biquw.com/book/{}/{}'.format(bookid,page_id)
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36'}
response_book = requests.get(url, headers)
response_book.encoding = response_book.apparent_encoding
response_book = BeautifulSoup(response_book.text, 'lxml')
book_content = response_book.find('div', id="htmlContent")
with open("./{}/{}.txt".format(bookid,page_name), 'a') as f:
f.write(book_content.text.replace('\xa0', ''))
print("当前下载章节:{}".format(page_name))
except Exception as e:
print(e)
print("章节内容获取失败,请确保书号正确,及书本有正常内容。")
if __name__ == '__main__':
bookid = input("请输入书号(数字):")
# 如果书号对应的目录不存在,则新建目录,用于存放章节内容
if not os.path.isdir('./{}'.format(bookid)):
os.mkdir('./{}'.format(bookid))
try:
booklist = book_page_list(bookid)
print("获取目录成功!")
time.sleep(5)
book_page_text(bookid, booklist)
except Exception as e:
print(e)
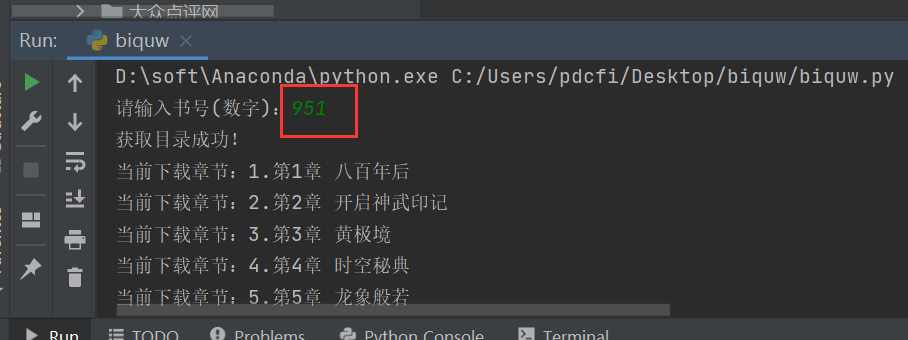
print("获取目录失败,请确保书号输入正确!")程序运行之后,在控制台输入书号,即可开始进行抓取了。
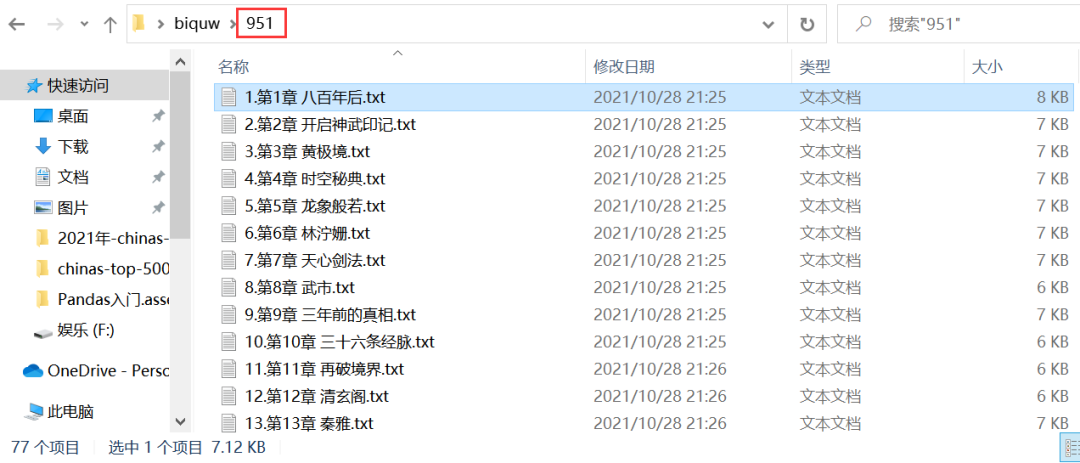
在本地也会自动新建一个书号命名的文件夹,在该文件夹下,会存放小说的章节,如下图所示。
三、常见问题
在运行过程中小伙伴们应该会经常遇到这个问题,如下图所示。
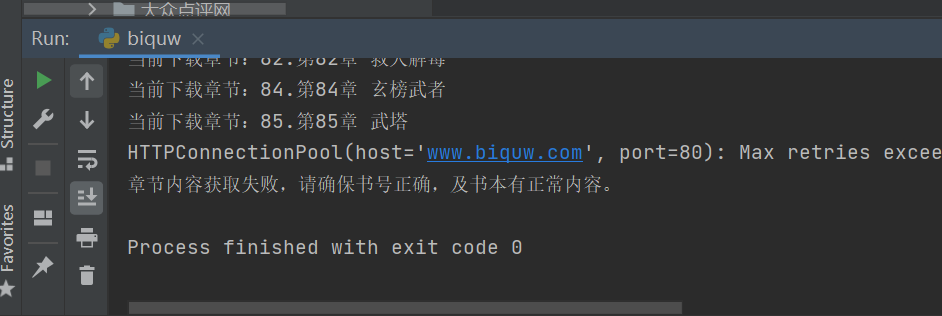
这个是因为访问太快,网站给你反爬了。可以设置随机的user-agent或者上代理等方法解决。
![]()
四、总结
我是Python进阶者。这篇文章主要给大家介绍了小说内容的获取方法,基于网络爬虫,通过requests爬虫库和bs4选择器进行实现,并且给大家例举了常见问题的处理方法。
本文仅仅做代码学习交流分享,大家切勿爬虫成疾,在爬虫的时候,也尽可能的选择晚上进行,设置多的睡眠,爬虫适可而止,千万别对对方服务器造成过压,谨记!谨记!谨记!
结语
学会了Python就业还是不用愁的,这些行业在薪资待遇上可能会有一些区别,但是整体来看还是很好的,我也不会说往哪个方向发展是最好的,各取所长选择自己最感兴趣的去学习就好。
作为一个IT的过来人,我自己整理了一些python学习资料,希望对你们有帮助。
朋友们如果需要可以点击下方链接或微信扫描下方二维码都可以免费获取【保证100%免费】。
CSDN大礼包:《2024最新Python全套学习礼包》【安全链接,放心点击】

编程资料、学习路线图、源代码、软件安装包等!
① Python所有方向的学习路线图,清楚各个方向要学什么东西
② 100多节Python课程视频,涵盖必备基础、爬虫和数据分析
③ 100多个Python实战案例,学习不再是只会理论
④ 华为出品独家Python漫画教程,手机也能学习
















 1111
1111

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









