









 本文详细解析了卷积神经网络(CNN)的结构,包括输入层、卷积层、激励层、池化层、全连接层及输出层的功能与工作原理。探讨了不同层的作用,如卷积层的特征提取,激励层的非线性映射,池化层的降维,以及全连接层的特征综合。并通过LeNet-5模型实例展示了CNN各层的具体应用。
本文详细解析了卷积神经网络(CNN)的结构,包括输入层、卷积层、激励层、池化层、全连接层及输出层的功能与工作原理。探讨了不同层的作用,如卷积层的特征提取,激励层的非线性映射,池化层的降维,以及全连接层的特征综合。并通过LeNet-5模型实例展示了CNN各层的具体应用。
卷积神经网络CNN的结构一般包含这几个层:
- 输入层:用于数据的输入
- 卷积层:使用卷积核进行特征提取和特征映射
- 激励层:由于卷积也是一种线性运算,因此需要增加非线性映射
- 池化层:进行下采样,对特征图稀疏处理,减少数据运算量。
- 全连接层:通常在CNN的尾部进行重新拟合,减少特征信息的损失
- 输出层:用于输出结果
- 归一化层(Batch Normalization):在CNN中对特征的归一化
- 切分层:对某些(图片)数据的进行分区域的单独学习(没接触过,就不整理了)
- 融合层:对独立进行特征学习的分支进行融合(没接触过,就不整理了)
1.输入层:
不做解释了~
如果输入为黑白图片,CNN的输入是一个 像素值*像素值 的二维矩阵,而彩色图片,CNN的输入则是一个 3*像素值*像素值 的三位矩阵,如果是文本而根据生存词向量的不同选择适合的矩阵。
2.卷积层:
卷积层(Convolutional layer),卷积神经网络中每层卷积层由若干卷积单元组成,每个卷积单元的参数都是通过反向传播算法最佳化得到的。卷积运算的目的是提取输入的不同特征,第一层卷积层可能只能提取一些低级的特征如边缘、线条和角等层级,更多层的网路能从低级特征中迭代提取更复杂的特征。
假设输入的是一个二维矩阵,我们定义 的 一个 3*3的卷积核,设移动的步长为1:从左到右扫描,每次移动 1 格,扫描完之后,再向下移动一格,再次从左到右扫描。
具体过程如动图所示:

卷积核:感受视野中的权重矩阵,大小一般用户来确定,而权重矩阵的值就是卷神经网络的参数,通常随机生成初值,通过训练来找到合适的值。
步长:每次卷积核移动的距离数,如果大于1时,可能会发生“出界”。
边界扩充(pad):通常补0。
通过卷积核扫描生成的下一层神经元矩阵被称为特征映射图
若我们使用 3 个不同的卷积核,可以输出3个特征映射图:(卷积核大小:5×5,布长stride:1)

3.激励层:
激励层主要对卷积层的输出进行一个非线性映射,为什么把线性映射变成非线性映射呐?
因为线性模型的表达能力往往不够!而激励函数可以为了增加整个网络的表达能力(即非线性)。
常见的激励函数:
1.Sigmoid函数
Sigmoid 是常用的非线性的激活函数,它的数学形式如下:
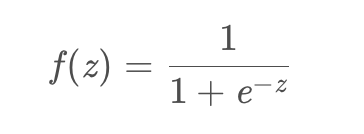
图像如下:
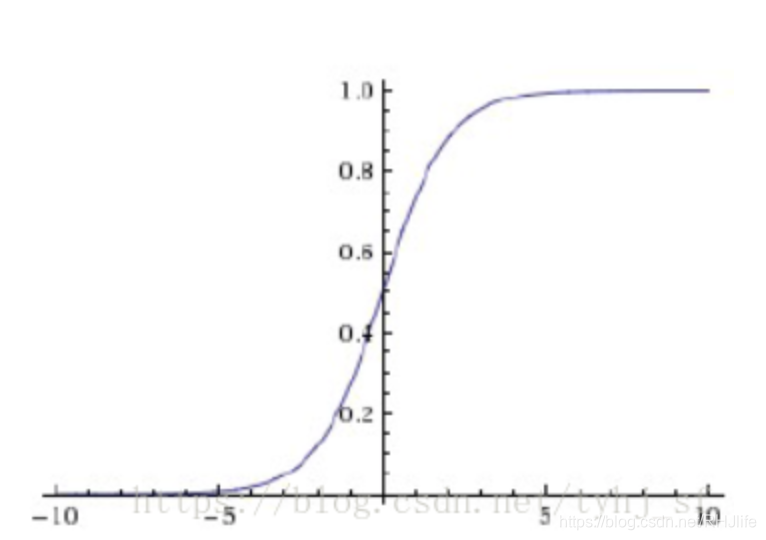
特点:
它能够把输入的连续实值变换为0和1之间的输出,特别的,如果是非常大的负数,那么输出就是0;如果是非常大的正数,输出就是1.
缺点:
1)在深度神经网络中梯度反向传递时导致梯度爆炸和梯度消失,梯度爆炸发生的概率非常小,但梯度消失发生的概率比较大。2)Sigmoid 的 output 不是0均值(即zero-centered)。这是不可取的,因为这会导致后一层的神经元将得到上一层输出的非0均值的信号作为输入。
2.tanh函数
tanh函数解析式:
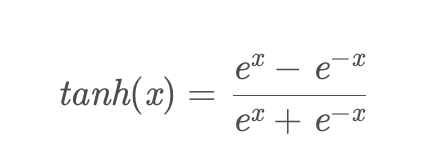
tanh函数及其导数的几何图像如下图:
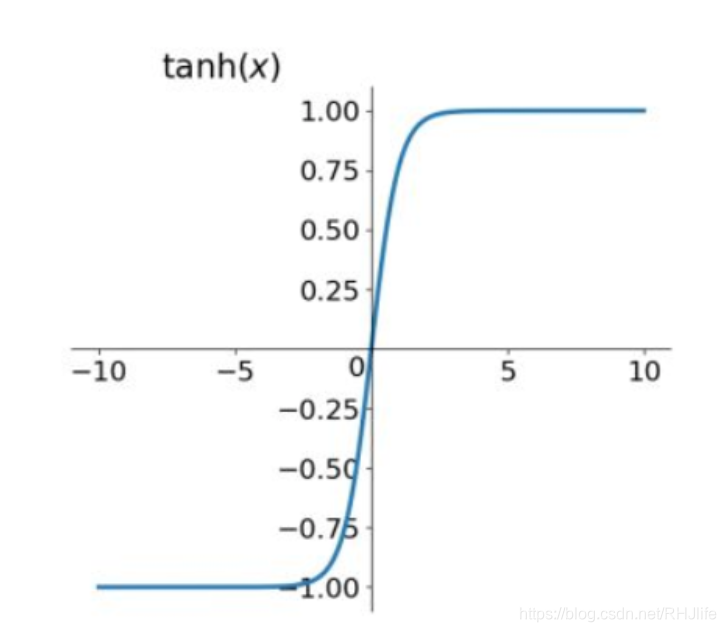
特点:它解决了Sigmoid函数的不是zero-centered输出问题,然而,梯度消失(gradient vanishing)的问题和幂运算的问题仍然存在。
3.Relu函数
Relu函数的解析式:
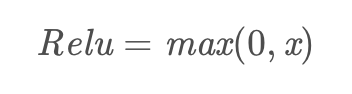
Relu函数及其导数的图像如下图所示:
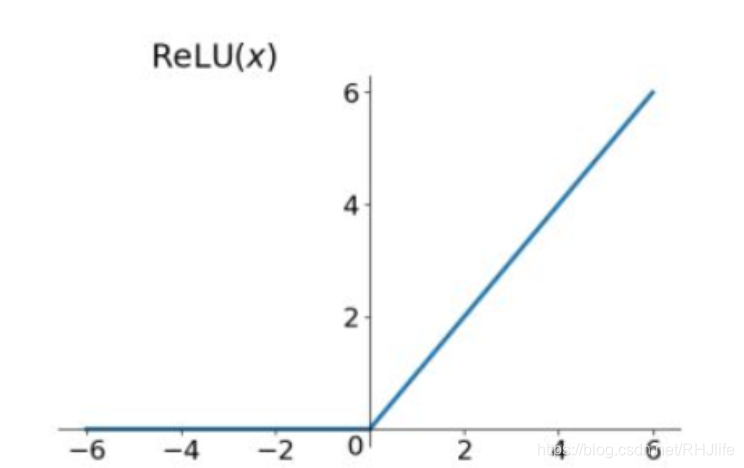
特点(优):
1) 解决了gradient vanishing问题 (在正区间)
2)计算速度非常快,只需要判断输入是否大于0
3)收敛速度远快于sigmoid和tanh
缺点:
1)ReLU的输出不是zero-centered
2)Dead ReLU Problem,指的是某些神经元可能永远不会被激活,导致相应的参数永远不能被更新。
尽管存在这两个问题,但是还是目前最常用的~
其他的例如:Leaky ReLU函数(PReLU)、ELU (Exponential Linear Units) 函数、MaxOut函数不在详细介绍。
(通常卷积层为:卷积层+激活层,即如果模型中卷积层后面没有激活层,则说明卷积层中包含了激活层)
4.池化层:
池化实际上是一种形式的降采样,有多种不同形式的非线性池化函数,而其中“最大池化(Max pooling)”是最为常见的。它是将输入的图像划分为若干个矩形区域,对每个子区域输出最大值,这种机制能够有效地原因在于,在发现一个特征之后,它的精确位置远不及它和其他特征的相对位置的关系重要。池化层会不断地减小数据的空间大小,因此参数的数量和计算量也会下降,这在一定程度上也控制了过拟合。通常来说,CNN的卷积层之间都会周期性地插入池化层。
池化层通常会分别作用于每个输入的特征并减小其大小。假设每隔2个元素从图像划分出2*2的区块,然后对每个区块中的4个数取最大值,这将会减少75%的数据量,如下图

5.归一化层:
两个作用:防止梯度爆炸和梯度消失。
防止梯度消失:神经网络在反向传播的过程中,每一层的梯度的计算都要乘以上层传过来的梯度,要是每一层的梯度值都比较小,那么在反向传播的过程中越传播梯度越小,就会导致梯度消失。以sigmoid激活函数的神经网络为例:
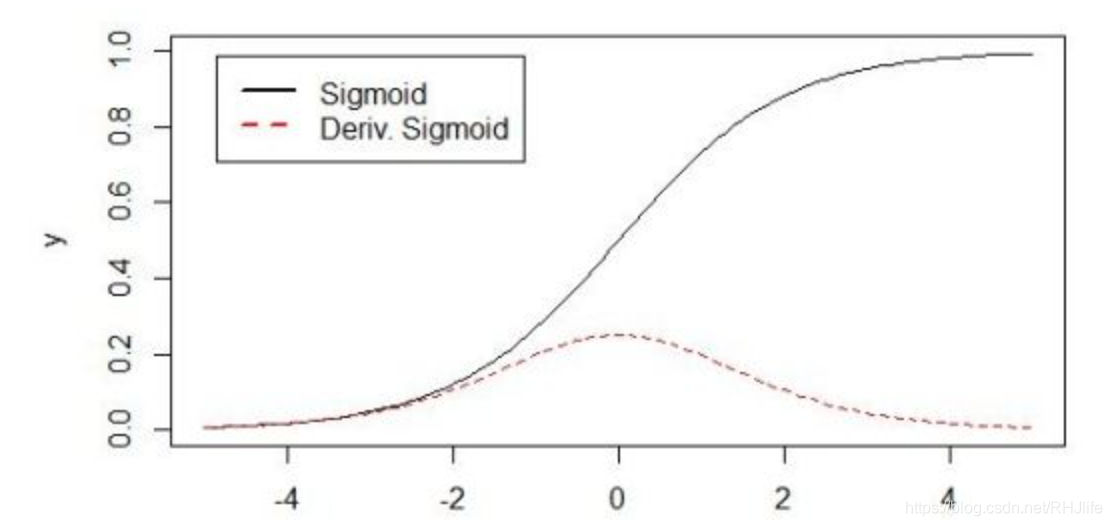
Sigmoid函数的函数曲线和相应的梯度如上图所示,可以看到sigmoid函数在零附近的梯度是最大的,而经过归一化之后的特征图数据变成了均值为零,方差为一的分布,恰好在零的周围,梯度相对在离零远的地方大了很多。这样在训练反向传播的过程中不断的前向传播不至于梯度消失。
防止梯度爆炸:神经网络在反向传播的过程中,每一层的梯度的计算都要用本层的数据(特征图)乘以上层传过来的梯度得到本层的梯度。本层的数据被归一化限制在均值为零,那么相乘的时候就不会发生梯度爆炸。
6.全连接层和输出层
全连接层主要对特征进行重新拟合。全连接层的每一个结点都与上一层的所有结点相连,用来把前边提取到的特征综合起来。全连接层在整个网络卷积神经网络中起到“分类器”的作用。输出层主要准备做好最后目标结果的输出。
以LeNet-5模型为例:
(LeNet-5的相关信息可自行百度)

第零层,输入层(INPUT):32*32*1图像像素的图片,LeNet-5模型接受的输入层大小为32x32x1
第一层,卷积层(C1):这一层的输入就是第零层的图片。第一个卷积层 过滤器/卷积核 的尺寸为5x5,深度为6不使用全0填充,步长为1。因为没有使用全0填充,所以这 一 层的输出的尺寸为32-5+1=28,深度为6。这 一 个卷积层总共有5x5x1x6+6=156 个参数,其中6个为偏置项参数。因为下一层的节点矩阵有28x28x6=4704个节点,每个节点和5x5=25个当前层节点相连,所以本层卷积层总共有4704x(25+1)= 122304个连接 。
第二层,池化层(S2):这一层的输入为第一层的输出,是一个28x28x6的节点矩阵。本层采用的过滤器大小为2x2,长和宽的步长均为2,所以本层的输出矩阵大小为14x14x6。
第三层,卷积层(C3):本层的输入矩阵大小为14x14x6,使用的过滤器大小为5x5,深度为16。本层不使用全0填充,步长为1。本层的输出矩阵大小为 10x10x16。按照标准的卷积层 ,本层应该有5x5x6x16+16=2416个参数,10x10x16(25+1)=41600个连接 。
第四层,池化层(S4):本层的输入矩阵大小为10x10x16,采用的过滤器大小为2×2,步长为2。本层的输出矩阵大小为5x5x16。
第五次,卷积层(C5):本层的输入矩阵大小为5x5x16,使用的过滤器的大小为5×5,深度为120,。本层不使用全0填充,步长为1.本层的输出矩阵大小为1x1x120。总共有5x5x16x120+120=48120个参数。本层也可以作如下理解:(本层的输入矩阵大小为5x5x16,因为过滤器的大小就是5×5,所以和全连接层没有区别,在之后的 TensorFlow 程序实现中也会将这一层看成全连接层。如果将5x5x16矩阵中的节点拉成一个向量,那么这一层和全连接层输入就一样了。)
第六层,全连接层(F6):本层的输入节点个数为120个,输出节点个数为84个,总共参数为120x84+84=10164个。
第七层,输出层(Output):本层的输入节点个数为84个,输出节点个数为10 个,分别代表数字0到9,总共参数为84x10+10=850个。
往往卷积(卷积后要激活)之后需要池化来进行降为,要输出时需要先进行全连接层来提取特征。
资料整理来自于百度百科、https://www.cnblogs.com/MrSaver/p/10355963.html、https://www.zhihu.com/question/54053174/answer/675647304、https://blog.csdn.net/cxmscb、https://blog.csdn.net/Sophia_11/article/details/85043685等多篇文章的学习。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









