






一、作者
黄汉秦 (江西财经大学)
二、原文地址
(2021 cnki)
三、主要内容
3.1 主要工作
- 本文提出基于语义信息的自闭症患者视觉显著区域检测算法,此外本算法设计了一种正负样本均衡的损失函数,以达到更好的训练效果。
- 本文提出了基于多标签监督学习的显著目标检测算法。本文共设计三个子模块,它们分别是显著目标监督模块、边缘信息监督模块和目标定位监督模块,以及一个PDM模块以此检测出更精准的结果。最后为了进一步提高模型的性能,将输出的显著图和特征图一同输入到细化网络中进行优化,得到最终稳定的显著图。
3.2 显著性区域检测算法
3.2.1 网络结构 (U-net)
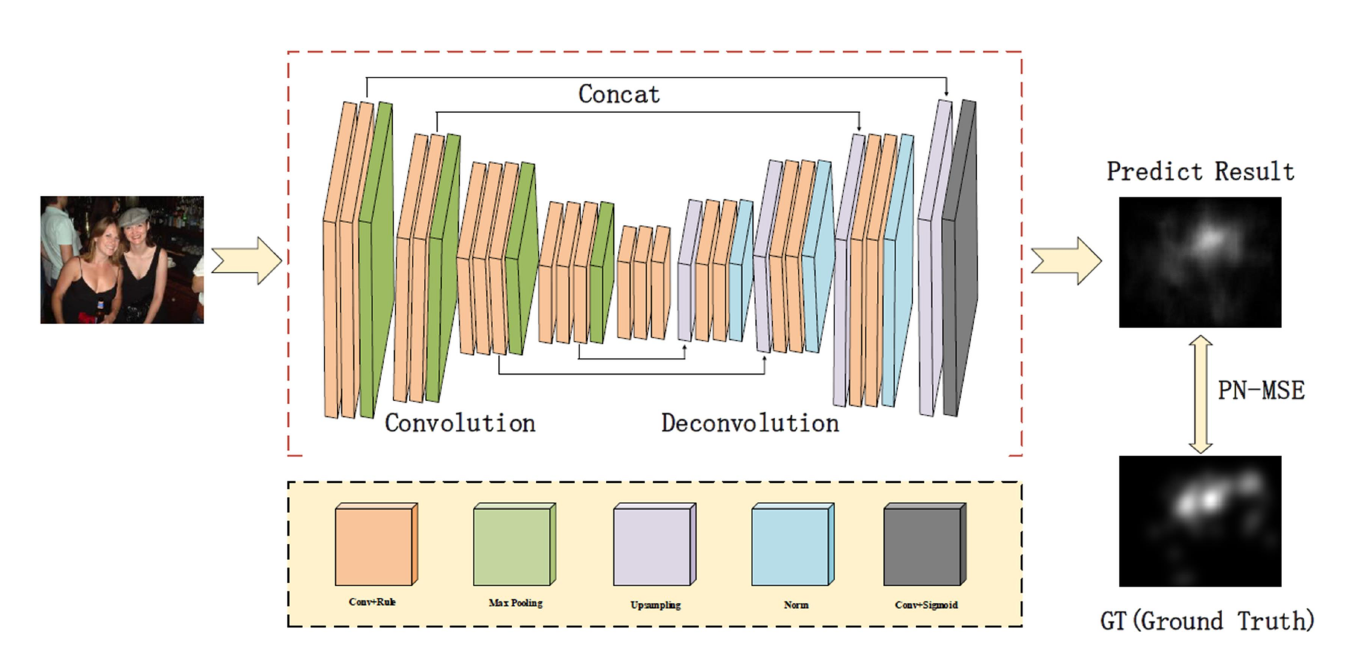
3.2.2 数据增强方式
- 平移、旋转、镜像、裁剪、尺度变换、亮度增强、色度增强、对比度增强和锐度增强
3.2.3 正负样本均衡 Loss
L o s s k + = 1 2 M + ∑ ( i , j ) ϵ C k − ( y i , j k − g ( i , j ) k ) 2 L o s s k − = 1 2 M − ∑ ( i , j ) ϵ C k − ( y i , j k − g ( i , j ) k ) 2 L o s s = 1 N ∑ k = 1 N ( L o s s k + + L o s s k − ) Loss_k^+ = \frac{1}{2M^+} \sum_{(i,j)\epsilon C_k^-}(y_{i, j}^k-g_{(i, j)}^k)^2 \\ Loss_k^- = \frac{1}{2M^-} \sum_{(i,j)\epsilon C_k^-}(y_{i, j}^k-g_{(i, j)}^k)^2 \\ Loss = \frac{1}{N} \sum_{k=1}^{N}(Loss_k^+ + Loss_k^-) Lossk+=2M+1(i,j)ϵCk−∑(yi,jk−g(i,j)k)2Lossk−=2M−1(i,j)ϵCk−∑(yi,jk−g(i,j)k)2Loss=N1k=1∑N(Lossk++Lossk−)
M + M^+ M+ :正样本的像素点数量 M − M^- M− :负样本的像素点数量 C k + , C k − C_k^+ , C_k^- Ck+,Ck− :正样本和负样本坐标集合
3.2.4 评价指标
- ROC曲线下的面积(Area Under the ROC Curve, AUC)
- 皮尔逊线性相关系数(Pearson Linear Correlation Coefficient, CC) C C ( p , g ) = c o v ( p , g ) σ p σ g CC(p, g)= \frac{cov(p, g)}{\sigma_p \sigma_g} CC(p,g)=σpσgcov(p,g)
- 受试者工作路径(Normalized Scanpath Saliency, NSS)
- KL散度(KullbackLeibler Divergence, KL)
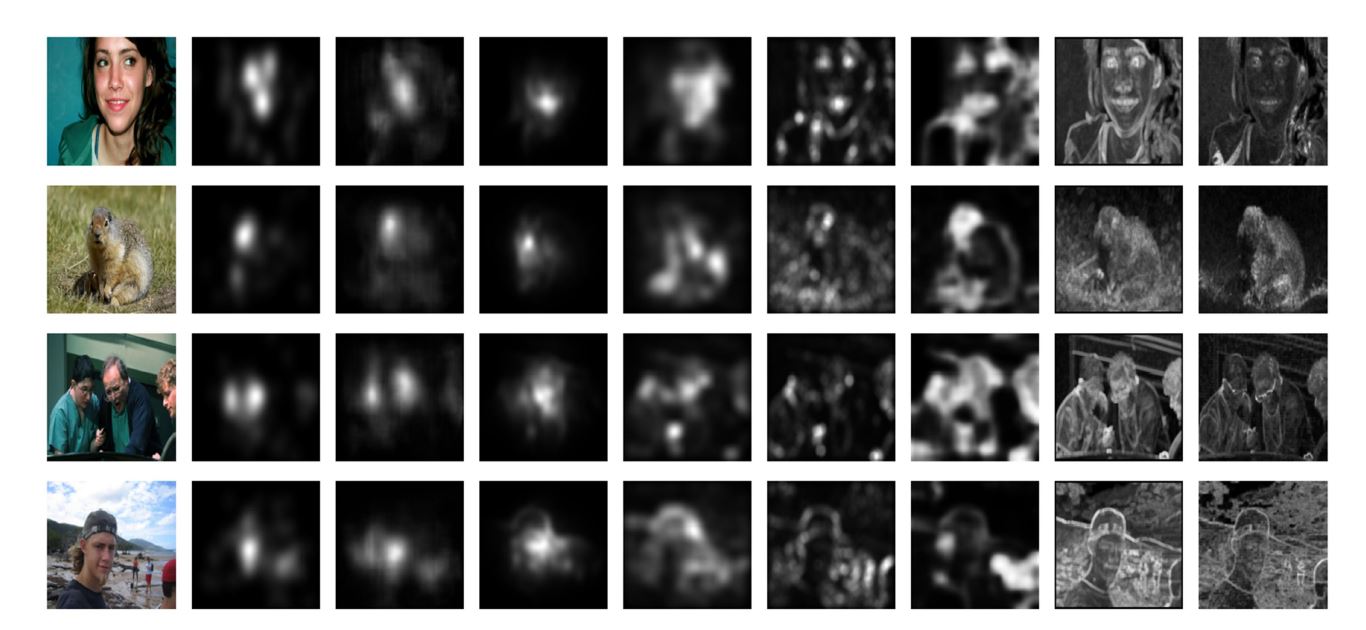
3.2.5 结果 (第三列)
3.3 显著性目标检测算法
3.3.1 网络结构图 (ResNet-50) (目标、边缘、定位)
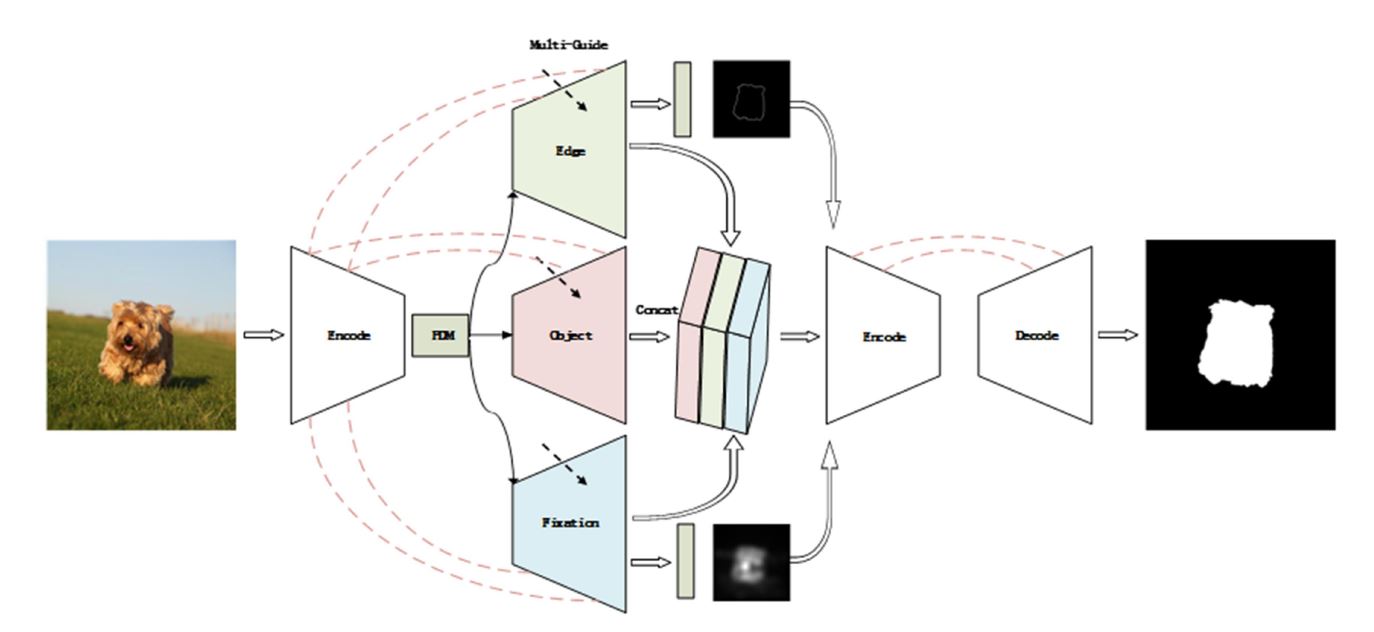
3.3.2 PDM模块 (空洞卷积)

3.3.3 多标签生成
- 采用一阶 Sobel 算子提取的边缘
- 边缘膨胀

3.3.4 显著定位图 (COV算法预测的fixation)

3.3.5 Loss
- BCE
- Dice (显著图与标签图的两倍交集比上它们的像素和)
L d i c e = 1 − 2 ∑ ∣ ∣ G ⋂ P ∑ ∣ G ∣ + ∑ ∣ P ∣ L o s s = L b c e + L d i c e L_{dice}=1-\frac{2\sum||G \bigcap P}{\sum|G| + \sum |P|} \\ Loss = L_{bce} + L_{dice} Ldice=1−∑∣G∣+∑∣P∣2∑∣∣G⋂PLoss=Lbce+Ldice
3.3.6 评估指标
- MAE
- F-measure
3.3.7 结果 (最后一列)

四、研究内容展望
- 针对有监督的显著性检测算法,需要进一步优化模型,让学习到的模型尽可能落地使用,为解决生活问题提供帮助。一方面研究学者可以简化模型,提高算法检测精度的同时,缩短推理速度,让算法融合到应用程序中,方便各用户使用;另一方面可以探索日常生活场景下的显著性检测,让学术走出实验室,实验室大多是理想状态下的场景,具有分明的显著目标,算法往往很容易检测出来,然而这些场景下数据很难贴近生活,即使实验室下性能很好的模型,放到生活场景下很容易检测出错。
- 基于深度学习的无监督检测算法将是一个很好的研究切入点,可以彻底摆脱对标注数据的依赖,在降低成本的同时可以更好的提高模型鲁棒性。
好的提高模型鲁棒性。















 607
607











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









