







 针对基于知识的问答(KBQA)中的问题,本文提出了一种新的代码风格的上下文学习方法,旨在减少逻辑形式的生成错误,并提高零样本泛化的性能。通过将逻辑形式的生成转换为代码生成任务,利用大型语言模型(LLM)的代码生成能力,实验结果显示该方法能有效降低格式错误率,同时在WebQSP、GrailQA和GraphQ数据集上实现新的SOTA。该方法还包括使用元函数、逐步推理和检索增强策略,以提高LLM在KBQA任务中的表现。
针对基于知识的问答(KBQA)中的问题,本文提出了一种新的代码风格的上下文学习方法,旨在减少逻辑形式的生成错误,并提高零样本泛化的性能。通过将逻辑形式的生成转换为代码生成任务,利用大型语言模型(LLM)的代码生成能力,实验结果显示该方法能有效降低格式错误率,同时在WebQSP、GrailQA和GraphQ数据集上实现新的SOTA。该方法还包括使用元函数、逐步推理和检索增强策略,以提高LLM在KBQA任务中的表现。

摘要
现有的基于知识的问题分类方法通常依赖于复杂的训练技术和模型框架,在实际应用中存在诸多局限性。最近,大型语言模型(LLM)中出现的上下文学习(ICL)功能为KBQA提供了一个简单且无需训练的语义解析范例:给定少量问题及其标记的逻辑形式作为演示示例,LLM可以理解任务意图并生成新问题的逻辑形式。然而,目前功能强大的LLM在预训练期间几乎没有暴露于逻辑形式,导致高格式错误率。为了解决这个问题,我们提出了一种代码风格的上下文学习方法的KBQA,它转换到更熟悉的代码生成过程中的LLM的不熟悉的逻辑形式的生成过程。在三个主流数据集上的实验结果表明,该方法极大地缓解了生成逻辑表单时的格式错误问题,同时在少镜头设置下在WebQSP、GrailQA和GraphQ上实现了新的SOTA。
1 引言
基于知识的问答(KBQA)是NLP社区长期研究的问题。由于问题的复杂性和多样性,性能良好的模型通常具有复杂的建模框架或特殊的训练策略。然而,这些设计也导致模型需要大量的标记数据来帮助参数收敛,导致它们难以应用于新的领域。最近,大型语言模型(LLM)具有强大的泛化能力,受益于大量自然语言语料库和开源代码的预训练(图1顶部)。此外,上下文学习(ICL)功能的出现允许LLM在观察少量标记数据的同时完成复杂的推理任务。
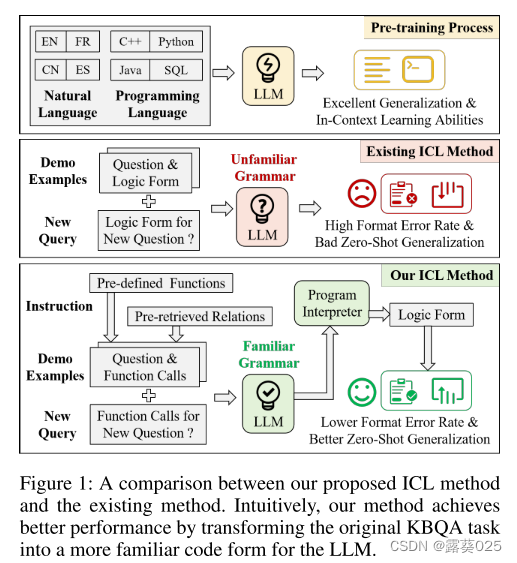
KB-BINDER是第一个基于ICL范式的KBQA方法。具体来说,KB-BINDER使用多个(问题,逻辑形式)对作为演示示例,并引导LLM生成正确的逻辑形式根据这些演示示例,查看新问题(图1中)。
然而,我们发现这种最新的方法仍然存在几个严重的问题:
- (1)高格式错误率。由于逻辑形式的高度专业化,它们很难全部出现在LLM的训练语料中。因此,通过几个演示示例来生成具有正确格式的逻辑形式是具有挑战性的。在我们的初步实验中,强大的GPT3.5-turbo生成的逻辑形式在GrailQA上的格式错误率超过15%。如果没有繁琐的句法分析和纠错步骤,生成的逻辑形式甚至不能提供问题的最终答案;
- (2)低零样本泛化性能。在零样本泛化场景中,与测试问题相关的知识库(KB)领域架构先验无法通过训练集中的数据获得。换句话说,这意味着从训练集创建的演示示例在这种情况下,无法提供足够的信息来回答问题。考虑到标注的数据通常只覆盖知识库中的一小部分知识,这个问题不可避免地会影响到实际应用的性能。
要解决这些问题,关键是要深入了解LLM的行为。值得庆幸的是,一些关于LLM的经验观察提供了理想的见解,其中包括
- (1) 将原始任务转换为代码生成任务将降低后处理的难度;
- (2) 逐步推理可以提高LLM在复杂推理任务上的性能;
- (3) 检索增强有助于LLM处理不常见的事实知识。
受上述有价值的观察的启发,我们为KBQA提出了一种新的代码风格的上下文学习方法,它将逻辑形式的一步生成过程转换为Python中函数调用(Function Call)的渐进生成过程(图1底部)。
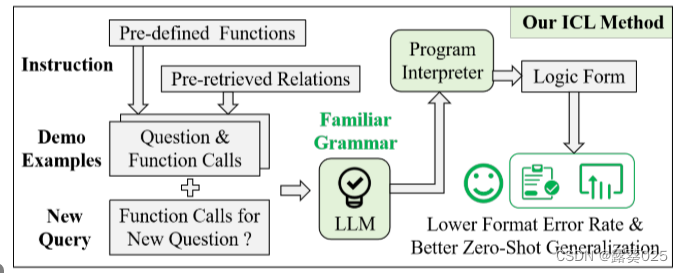
具体来说,我们首先为S-Expression定义了七个元函数,S-Expression是KBQA的一种流行逻辑形式,并在Python中实现了这些函数。请注意,此步骤使所有S表达式能够通过有限数量的预定义元函数调用生成。对于一个测试问题,我们在训练集中抽取了一些(question,S-Expression)对,并将它们转换为(question,function call sequence),其中函数调用序列可以在Python解释器中执行以输出S-Expression。最后,元函数的Python实现、所有(问题、函数调用序列)对和测试问题以代码形式重新格式化,作为LLM的输入。并期望LLM为新问题补充一个完整的函数调用序列,以获得正确的逻辑形式。此外,我们还发现了一种简单有效的方法来提高零次泛化场景下的性能:将测试问题视为查询,在知识库中检索相关关系,并将该关系提供给LLM以供参考。
我们的贡献可以总结如下:
- 我们提出了一种新的代码风格的上下文学习方法的KBQA。与现有的方法相比,我们的方法可以有效地减少格式错误率的逻辑形式生成的LLM,同时提供额外的中间步骤在推理过程中。
- 我们发现,提前提供与问题相关的关系作为LLM的参考可以有效地提高零次泛化场景中的性能。
- 基于ICL方法设计了一个无需训练的KBQA模型KB-Coder。在WebQSP、GrailQA和GraphQ上的大量实验表明,我们的模型在少镜头设置下实现了SOTA。在允许访问完整训练集的同时,与当前的监督SOTA方法相比,无需训练的KB-Coder实现了具有竞争力或更好的结果。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









