






文章链接:https://arxiv.org/pdf/2104.00854.pdf
《The Spatially-Correlative Loss for VariousImage Translation Tasks》
不同图像转换任务的空间相关性损失
简介:
我们提出了一种新颖的空间相关损失,该损失简单、高效,并且能够有效地保持场景结构的一致性,同时支持未配对图像到图像(I2I)转换期间的大外观变化。以前的方法通过使用像素级周期一致性或特征级匹配损失来尝试这一点,但这些损失的领域特定性质阻碍了跨大领域间隙的翻译。为了解决这个问题,我们利用自相似的空间模式作为定义场景结构的一种手段。我们的空间相关损失只针对捕获图像中的空间关系,而不是域外观。我们还引入了一种新的自监督学习方法,为每个特定的翻译任务显式地学习空间相关的地图。这种新的损耗可以很容易地集成到现有的网络架构中,因此具有广泛的适用性。
为了缓解场景结构差异的问题,提出了一些用于比较输入和输出图像之间内容的损失函数:
包括:
(a)像素级:图像重建损失和周期一致性损失;
(b)特征级感知损失[12,25]和PatchNCE损失。
缺点:
1.像素级损耗并没有明确地将结构和外观解耦。
2.特征级损失有助于继续合并特定于领域的结构和外观属性。最后,大多数特征级损失计算使用固定ImageNet预训练网络(例如VGG16),不能正确适应任意域。
在这项工作中,我们的目标是设计一个领域不变的表示来精确地表达场景结构,而不是使用原始像素或特征来耦合外观和结构,经典的低级自相似度(self-similarity)被用于匹配和图像分割,而深度学习中的特征级自相似度表现为自我注意映射。我们提出一个假设,即同一类别中的所有区域都表现出某种形式的自相似性。例如:尽管马和斑马在外观上存在巨大差异,但当场景结构相同(即姿势相同)时,自相似性的空间模式也相同。我们相信网络可以学习自我相似性的更深层次的表示(不仅仅是视觉上的),可以编码完整的物体形状,即使物体内部的外观有变化。

我们的基本空间相关映射,称为FSeSim,是通过计算从预先训练的网络中提取的特征的Fixed Self-Similarity来获得的。虽然这个在某些任务上取得了与最先进的方法相比甚至更好的结果,但由于从ImageNet预训练网络中提取的特征倾向于逼真的图像,其通用性是有限的。
为了获得更一般的空间相关图,可以使用Learned Self-Similarity,称为LSeSim,是通过使用一种对比损失的形式来表示的,在这种形式中,我们鼓励相同的结构更接近,而不管它们的外观如何,并且即使它们具有相似的外观,也会相互分离不同的结构。为此,该模型学习了一个域不变的空间相关性映射(domain-invariant spatially-correlative map),其中具有相同的场景结构会导致相似的映射,即使图像来自不同的域。
方法介绍:
目的:保留场景结构,并适当转变外观
计算每个图像内深层特征的自相似度,然后比较图像之间的自相似模式。
FSeSim:
我们直接比较 从固定预训练网络(例如VGG16)中提取的特征 的自相似模式。
给定一个域中的图像x和另一个域中对应的平移图像y,我们使用一个简单的网络(例如VGG16)提取特征fx和fy, 以映射的形式计算自相似度。我们称其为空间相关映射,形式如下:

即将图像x中输入到网络中,提取出一堆特征图fx。选取一个小patch,fxi是一个查询点xi的特征,而fx*是这个小patch中Np个点的特征。将这个patch中的查询点xi和其余Np个点做向量相乘,即得到这个查询点xi和该patch中其他点的特征空间关系,得到Sxi。例如下图中的红色查询点。
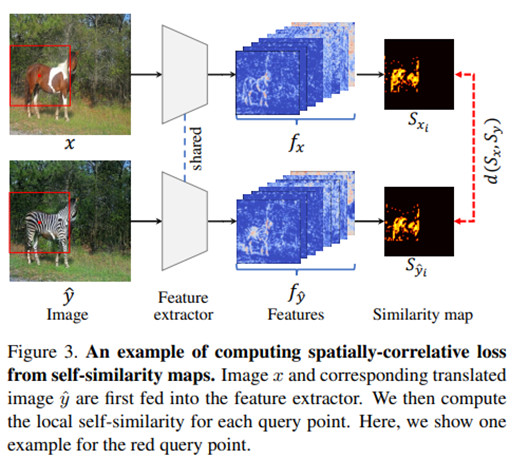
接下来,将整个图像的结构表示为多个空间相关映射的集合Sx=[Sx1, Sx2, Sx3,…, Sxs] ∈ R Ns×Np, Ns是整个空间采样的patch数,Np是每个patch中的采样点。然后,我们比较输入x和平移图像y之间的多个结构相似图:

LSeSim:
我们另外引入了一个 学习正确比较自相似模式的 结构表征模型,其中我们使用对比infoNCE损失来学习这样一个没有标签监督的网络。FSeSim为结构一致性提供了强大的监督,但它并没有明确地学习特定翻译任务的结构表示。我们建议为每个任务额外学习一个结构表示网络,称作可学习的自相似度learned self-similarity。
为了帮助生成一对 用于自监督学习的 相似的patch特征,我们通过应用 结构保留 (structure-preserving transformations.)转换来创建增强图像。
v = Sxi ∈ R 1×Np 是查询patch的空间映射图,v += Sxˆi ∈R 1×Np是正例patch采样,
v−∈ R K×Np是负例patch采样。查询patch与增强图像Xaug中相同位置i的patch正配对,与Xaug中其他位置采样的patch负配对,或与其他图像y采样的patch负配对。使用的负补丁数量为K = 255。
、
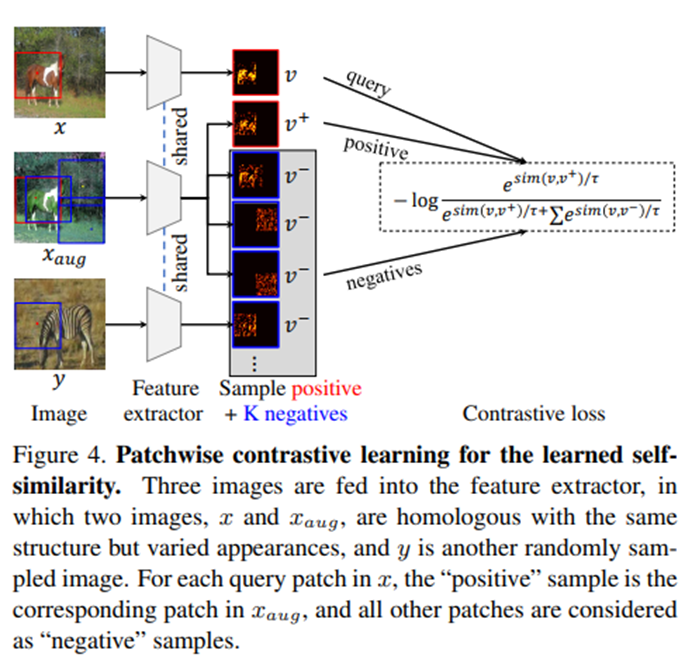
我们的LSeSim设计如图4所示。对比损失为:

sim(v,v +) = v T v +/|v||v+| 是余弦相似度,τ是一个温度参数。
总的来说,我们通过共同最小化以下损失来训练网络:
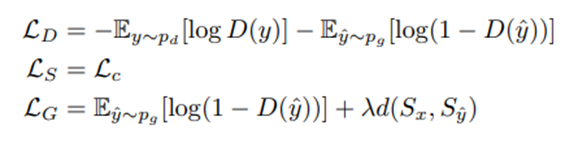
LD为鉴别器D(·)的对抗损失,y^为平移后的图像,LS为结构表示网络f(·)的对比损失。LG是生成网络G(·)的损失,由风格损失项和结构损失项组成。λ是一个在风格和内容之间进行权衡的超参数。
误差图可视化分析:
本节说明LSeSim可用作生成图像结构的评估手段之一。

我们考虑一个场景,给定一个语义图x,任务是将其转换为一个逼真的图像y。我们分别对比 一个理想结果(配对的基本真理yalign) 和 一个错误结果(另一个图像yunalign) 的在不同损失下的结构误差。在这样的设置下,一个好的结构损失应该惩罚错误的结果,同时支持理想的结果。
像素级损失在域间相差较大情况下,两张图误差都很大。而感知损失在对齐和未对齐图像上报告显著错误。PatchNCE通过计算特征的余弦距离缓解了这一问题,但可以看到,由于提取的特征由颜色和纹理等外观属性组成,在对齐结果的许多区域损失图仍然保留了较高的误差。
LSeSim导致对齐图像(左)的误差很小,即使它们在完全不同的领域,但对于不对齐图像(右)的误差很大。LSeSim可以更好地帮助保存场景结构,即使跨越较大的域。
实验以及评估尺度:
在实验中,在这个任务中,选择了CycleGAN作为参考架构,将循环一致性损失替换为我们的F/LSeSim损失。FSeSim是基于imagenet预训练的VGG16,其中使用了来自relu3 1和relu4 1层的特征。LSeSim采用了与FSeSim相同的结构,但权重不是固定的,此外还包括两个卷积层,实现为1 × 1卷积核,以选择更好的特征。对于构建对比损失的patch的选择,我们发现在网格上对patch位置的随机采样比均匀采样表现得更好,从而在训练结构表示网络时具有更好的收敛性。我们设置λ = 10在FSeSim和τ =0.07在LSeSim。
Frechet Inception Distance (FID),通过在深度特征域内比较生成图像与真实图像分布之间的距离来评估生成图像的视觉质量。















 761
761











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









