






DreamBooth:Fine Tuning Text-to-Image Diffusion Models
DreamBooth: 微调文本到图像的扩散模型,用于主题驱动的生成
论文:
https://openaccess.thecvf.com/content/CVPR2023/papers/Ruiz_DreamBooth_Fine_Tuning_Text-to-Image_Diffusion_Models_for_Subject-Driven_Generation_CVPR_2023_paper.pdf
代码:
https://github.com/XavierXiao/Dreambooth-Stable-Diffusion
主要思想:
参考博主链接:
https://blog.csdn.net/qq_43800752/article/details/131057905?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522168619212316800222830521%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=168619212316800222830521&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~rank_v31_ecpm-4-131057905-null-null.142^v88^koosearch_v1,239^v2^insert_chatgpt&utm_term=DreamBooth%3A%20Fine%20Tuning%20Text-to-Image%20Diffusion%20Models%20for%20Subject-Driven%20Generation&spm=1018.2226.3001.4187
想让一个大模型适应你的主题,比如图1,你家的狗,你想把它P到各种地方,或者各种形态,你希望狗一定要像你家狗,但是P的地点和形态也要很真实和形象。本文就是解决这个问题,主要方式是正则化的微调。
首先,你先准备几张你家狗的图片(比如图1的四张),你想让你家狗游泳,那么我先用预训练的扩散模型生成1000张”一只狗在游泳“的图片,显然这种方式生成的狗各不相同。那么你想变成你家的狗,这是只需要把你家的狗当作一种唯一标识[V]。这时候我们用你家狗的4张图片作为训练集,然后在prompt上加入[V],”一只[V]狗“。这里不需要加入”在游泳“,我们只想让模型学到这个唯一标识符,然后训练好后,模型就会把[V]替换成狗,那么前面各不相同的狗就会都变成你家的狗了。
训练过程简单来说是:2个数据集,一个是模型生成的,一个是你自己的主题。2个文本prompts,一个是”a [V] 类别“,一个是"a 类别 …"。我们利用损失函数联合训练,训练的过程中,模型在学习”一个狗在游泳“的同时也学习”一个[V]狗“,那么模型就仅仅会改变狗的样子。损失函数见下面。
摘要:
大型文本到图像模型在人工智能的发展中实现了显著的飞跃,从给定的文本提示中实现了高质量和多样化的图像合成。这些模型缺乏模仿给定参考集中对象的外观和在不同上下文中合成它们的新表现的能力。在这项工作中,我们提出了一种新的文本到图像扩散模型的“个性化”方法。给定一个主题的几张图像作为输入,我们对预训练的文本到图像模型进行微调,使其学会将唯一标识符与特定主题绑定。一旦主题嵌入到模型的输出域中,就可以使用唯一标识符合成在不同场景中背景化的主题的新颖逼真图像。
介绍:
大模型的缺点:这样的先验学习将“狗”这个词与可以在图像中以不同姿势和上下文出现的狗的各种实例绑定在一起。虽然这些模型的综合能力是前所未有的,但它们缺乏模仿给定参考集中主题外观的能力,以及在不同上下文中合成相同主题的新表现的能力。主要原因是其输出域的表达性有限;即使是对一个物体最详细的文字描述也可能产生具有不同外观的实例。此外,即使是文本嵌入在共享语言视觉空间中的模型也不能准确地重建给定主题的外观,而只能创建图像内容的变体。例如图2所示:
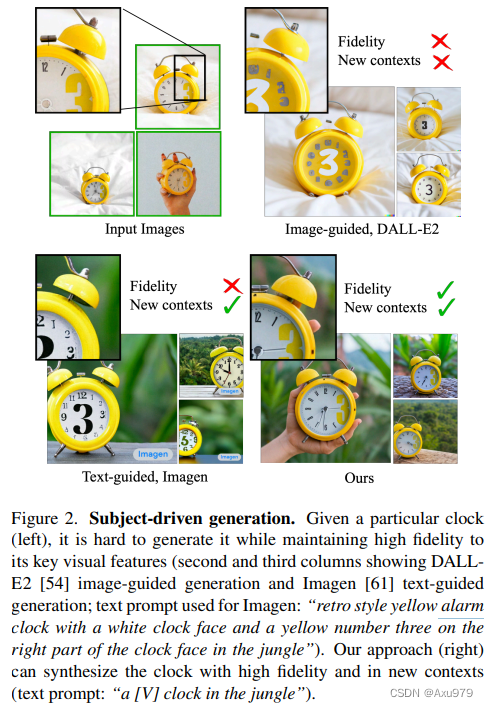
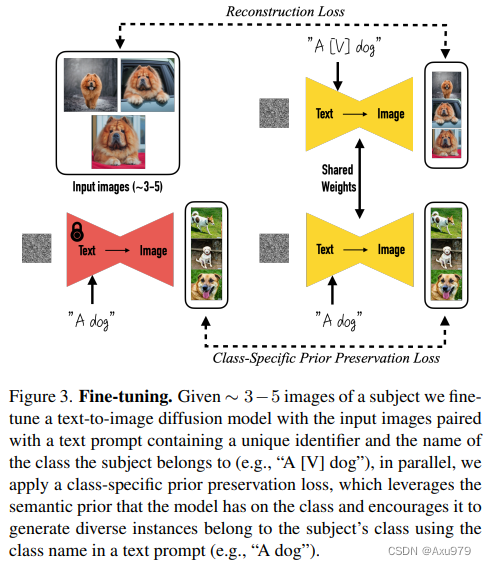
我们的目标是扩展模型的语言视觉词典,这样它就可以将新单词与用户想要生成的特定主题绑定在一起。一旦新字典被嵌入到模型中,它就可以使用这些单词合成新的逼真的主题图像,将其置于不同的场景中,同时保留其关键的识别特征。这种效果类似于一个“神奇的照相亭”——一旦拍摄了几张被摄者的照片,在简单直观的文字提示的引导下,照相亭就会生成被摄者在不同条件和场景下的照片(图1)。即给定一个主题的几张图像(~3-5),我们的目标是将主题(subject)植入模型的输出域中,这样它就可以用唯一的标识符(a unique identifier)进行合成。为此,我们提出了一种技术,用罕见的令牌标识符(token identifiers)来表示给定的主题,并对预训练的、基于扩散的文本到图像框架进行微调。

我们对文本到图像模型进行微调,输入图像和文本提示包含一个唯一标识符,后跟主题的类名(例如,“a [V] dog”)。后者使模型能够使用其关于主题类的先验知识,而特定于类的实例则与唯一标识符绑定。为了防止语言漂移(language drift)导致模型将类名(例如“dog”)与特定实例相关联,我们提出了一种自生的、特定于类的先验保存损失(an autogenous, class-specific prior preservation loss),它利用嵌入在模型中的类的语义先验,并鼓励它生成 与我们的主题相同的类 的不同实例(例如生成与输入图像一样的狗)。
方法:
我们的第一个任务是将主题实例植入到模型的输出域中,这样我们就可以在模型中查询主题的各种新图像。一个自然的想法是使用主体的few-shot数据集来微调模型。
在微调生成模型(如GANs)时,必须非常小心,因为它可能导致过拟合和模型崩溃,以及不能很好地捕获目标分布。关于这些陷阱,我们观察到一个奇特的发现,基于一个使用扩散损失的仔细的微调设置,大的文本到图像的扩散模型似乎擅长于整合新的信息到他们自己的领域而不会忘记 先前的信息 或者 过拟合于一小组训练图像。
为few-shot个性化设计prompt:
我们的目标是在扩散模型的“字典”中“植入”一个新的(唯一标识符,主题)对。为了绕过为给定图像集编写详细图像描述的开销,我们选择了一种更简单的方法,并将主题的所有输入图像标记为“a [identifier] [class noun](一个[标识符][类名词])”,其中[标识符]是链接到主题的唯一标识符,[类名词]是主题的粗略类描述符(例如猫,狗,手表等)。我们在句子中使用类描述符是为了将类的先验性与我们唯一的主题联系起来,并发现使用错误的类描述符或没有类描述符会增加训练时间和语言漂移,同时降低性能。
Rare-token Identifiers(Rare-token标识符):
稀有令牌标识符: 我们通常发现现有的英文单词(例如"unique"、“special”)不够理想,因为模型必须学习将它们从原来的含义中解脱出来,并重新将它们与我们的主题联系起来。这就需要一个在语言模型和扩散模型中都具有较弱先验的标识符。一种危险的方法是从英语中选择随机字符并将它们连接起来生成一个稀有标识符(例如"xxy5syt00")。
实际上,分词器可能会将每个字母分开分词,并且这些字母对于这些字母的先验概率较高。我们经常发现这些标记具有与使用常见英文单词类似的弱点。我们的方法是在词汇表中查找稀有标记,然后使用解分词器将这些标记反转为文本空间,以最小化标识符具有强先验的概率。我们在词汇表中进行稀有标记查找,并获得一系列稀有标记标识符f ( V ^ ),其中f是一个分词器,它将字符序列映射到标记,并且V ^是来自标记f ( V ^ )的解码文本。序列的长度可以是可变的k,我们发现k = { 1 , . . . , 3 }的相对较短的序列效果较好。然后,通过在f ( V ^ )上使用去分词器反转词汇表,
我们获得了定义我们独特标识符V ^的字符序列。对于Imagen,我们发现使用对应于3个或更少Unicode字符(无空格)的标记的均匀随机抽样,并使用T5-XXL分词器范围{5000, …, 10000}的标记效果良好。
(分词器(Tokenizer)是一种将文本分解为离散单元(如单词、子词或字符)的工具或算法。
在自然语言处理中,分词是文本预处理的重要步骤之一,它将连续的字符序列切分成有意义的单元,以便进一步处理和分析。
例如将"我喜欢学习机器学习"分成"我 喜欢 学习 机器学习"。)
Class-specific Prior Preservation Loss(特定类别的先验保持损失):
根据我们的经验,通过微调模型的所有层来获得最大主体保真度的最佳结果。这包括以文本嵌入为条件的微调层,这导致了语言漂移的问题。
语言漂移是语言模型中观察到的问题,其中预训练于大型文本语料库并随后针对特定任务进行微调的模型逐渐失去了语言的句法和语义知识。据我们所知,我们是第一个发现类似现象影响扩散模型的人,其中模型逐渐忘记了如何生成与目标主题属于相同类别的主题。另一个问题是产出多样性降低的可能性。文本到图像扩散模型自然具有大量的输出多样性。当对一小部分图像进行微调时,我们希望能够以新颖的视角,姿势和清晰度生成主题。然而,在主体的输出姿势和视图中存在减少可变性的风险(例如,捕捉到几个镜头的视图)。我们观察到,这种情况经常发生,特别是当模型训练时间过长时。为了缓解上述两个问题,我们提出了一种自生的类特异性先验保存损失,以鼓励多样性并防止语言漂移.
我们的方法是用模型自己生成的样本来监督模型。这允许它生成类先验的不同图像,并保留关于类先验的知识,它可以将这些知识与关于主题实例的知识结合使用。具体来说,我们生成数据xpr = x (zt1,cpr) 是通过使用祖先采样器对具有随机初始噪声zt1 ~ N (0,I)和条件向量cpr := (f(“a [class noun]”)) 的冷冻预训练扩散模型进行采样。
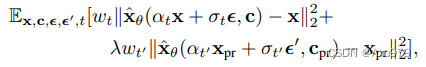
其中第二项是先验保存项,它用自己生成的图像监督模型,λ控制这一项的相对权重。图3演示了使用类生成的样本和先验保存损失进行的模型微调。尽管很简单,但我们发现这种先验保存损失在鼓励输出多样性和克服语言漂移方面是有效的。我们还发现,我们可以训练模型进行更多的迭代,而不会有过拟合的风险。我们发现~ 1000次迭代对于Imagen, λ = 1,学习率为10−5,对于Stable Diffusion,学习率为5×10−6,并且在主题数据集大小为3-5张图像的情况下,足以获得良好的结果。在此过程中,生成约1000个“a [class noun]”样本-但可以使用的更少。















 1449
1449











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









