






[2020CVPR] ReusingDiscriminators for Encoding
NICEGAN:
论文地址:https://arxiv.org/pdf/2003.00273.pdf
摘要:
本文通过重用鉴别器对目标域图像进行编码,提出了一种新的鉴别器的作用。
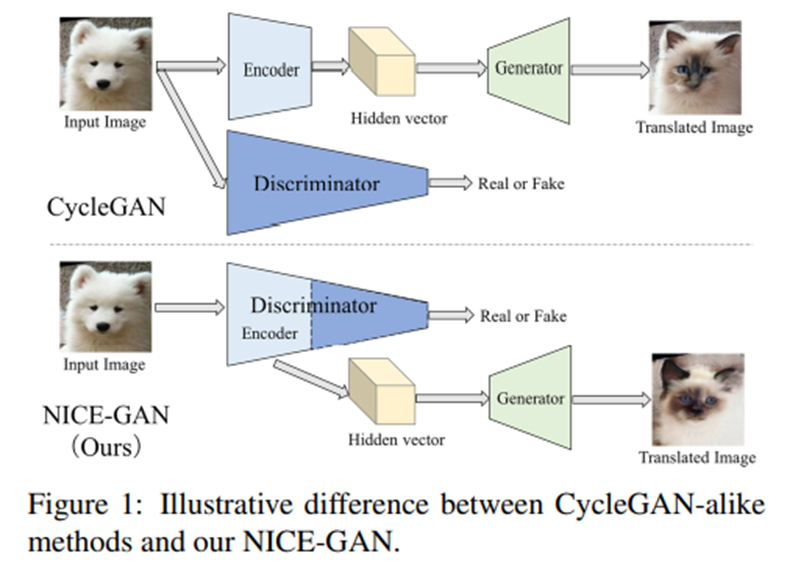
它们大多数都由每个域的三个组件组成:一个将输入图像嵌入到低维隐藏空间的编码器,一个将隐藏向量转换为其他域图像的生成器,以及一个使用GAN训练[9]进行域对齐的鉴别器。
我们仍然有兴趣问:是否有可能重新思考当前翻译框架中每个组件的作用?更重要的是,我们能否改变目前的公式。
鉴别器应该对输入图像进行某种语义编码,然后才能判断哪些图像是真的,哪些是假的。鉴别器的两个作用:编码和分类。DCGAN论文揭示了鉴别器的编码能力:在鉴别器中最后一个卷积层的前6个学习卷积特征中观察到对输入图像的强烈响应。
本文提出重用鉴别器进行编码。特别地,我们在鉴别器中重用特定数量的早期层作为目标域的编码器,如图1所示。这种重用具有双重优势:
1.实现了更紧凑的架构。由于编码器现在成为鉴别器的一部分,我们不再需要一个独立的编码组件。
2.编码器训练更有效。编码器的传统训练是通过反向传播来自生成器的梯度进行的,这是间接的。在这里,通过将其插入鉴别器,编码器直接通过鉴别损耗进行训练。此外,现代鉴别器已经使用了多尺度方案,以获得更强的表达能力;如果采用多尺度鉴别器,编码器的表达能力将从本质上继承。
我们方法的一个遗留问题是如何进行对手训练。对于传统方法,编码器与生成器一起训练以最小化GAN损耗,而鉴别器分别训练以最大化目标。在我们的框架中,编码器和鉴别器是重叠的,如果我们采用传统的训练设置——作为翻译的一部分的编码器被训练为最小化,同时它属于鉴别器,也被训练为最大化,这会带来不稳定性。为了消除这种不一致性,我们开发了一个解耦训练范式。具体地说,编码器的训练只与鉴别器相关,独立于生成器。
无监督翻译学习fx→y和fy→x,只提供边缘值p(x)和p(y)。无监督平移是不适定的,因为有无限多个条件概率对应于相同的边际分布。为了解决这个问题,目前的方法诉诸于添加额外的规则,如权重耦合、循环一致性和鉴别损失,本文采用了后两者。
No Independent Component for Encoding (NICE). 无独立编码组件:
形式上,我们将鉴别器Dy分为编码部分ED y和分类部分Cy。编码部分ED y将取代fy→x中的原始编码器,从而得到一个新的翻译fy→x(y) = Gy→x(ED y (y)).鉴别器Dx也是如此,我们定义ED x和Cx,并将平移函数重新表述为fx→y(x) = Gx→y(ED x (x))

多尺度判别器Dx和Dy:
在这些方法中,不同尺度的鉴别器应用于不同大小的图像(小尺寸图像是通过下采样从原始图像获得的)。在本文中,我们考虑了一种更有效的方法,将单个输入的不同层的特征映射视为不同尺度的图像,然后将每一层的特征映射以相应的输入大小馈送到分类器进行判别,这类似于特征金字塔表示在目标检测中的应用(如SSD和FPN)。
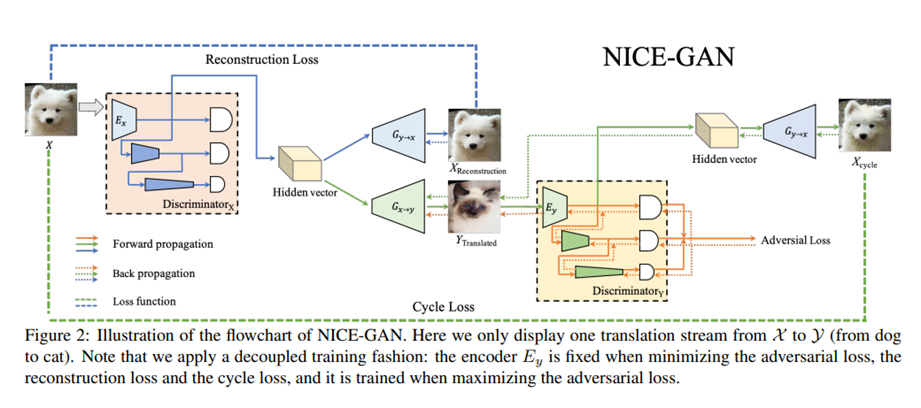
鉴别器Dx包含两部分:编码器Ex和分类器Cx:为了实现多尺度处理,分类器Cx进一步划分为三个子分类器:
C0 x (局部尺度)(10 x 10感受野),
C1x(中等尺度)(70 x 70感受野),
C2 x(全局尺度)(286 x 286感受野)。
C0 x直接与Ex的输出相连,然后在Ex上进行向下采样-卷积层,得到较小比例的特征映射,并将其串联成两个分支:一个分支与C1 x相连,另一个分支通过卷积层再向下采样,然后再进行C2 x。对于单个输入图像,C0 x, C1 x和C2 x都被训练来预测图像是真还是假。多尺度鉴别器如图2所示。
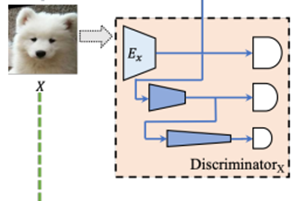
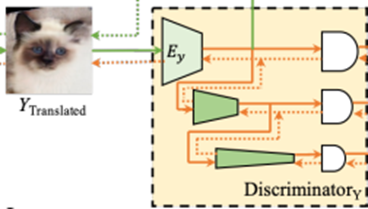
在多尺度设计的基础上,我们开发了残差注意(residual attention)机制,以进一步促进特征在鉴别器中的传播。
假设编码器包含K个的特征映射Ex = {Ekx} Kk=1 ,U-GAT-IT的思想是首先学习一个注意力向量w,其中的每个元素都计算每个特征映射的重要性。
通过a(x) = w × Ex(x)= {wk × Ekx (x)} Kk=1计算所参与的特征用于之后的分类。在U-GAT-IT之上,本文进一步考虑残差连接,我们用a(x) = γ × w × Ex(x) + Ex(x) 可训练参数γ决定了参与特征和原始特征之间的权衡。当γ=0,它返回到Ex(x)表示没有使用attention,否则,attention被激活。通过这种改进,我们的方法在调整不同特征图的重要性上变得更加灵活,从而在训练中获得了更好的效果,这将在我们的实验中得到验证。
生成器Gx→y和Gy→x。Gx→y和Gy→x均由6个残差块和上采样的2个sub-pixel卷积层组成。我们用AdaLIN轻质版本。此外,采用spectral normalization作为鉴别器,并进行周期一致性损失以防止发生器模式崩溃。
解耦合训练:
训练过程根据三种损失进行:对抗损失、身份重建损失和周期一致性损失。
由于编码器Ex不仅是判别器Dx的一部分,而且作为生成器Gx→y的输入,如果我们采用传统的对抗训练,会产生不一致。为了克服这一缺陷,我们将Ex的训练与生成器Gx→y的训练解耦。每项损失的计算细则如下。
对抗损失(Adversarial loss):
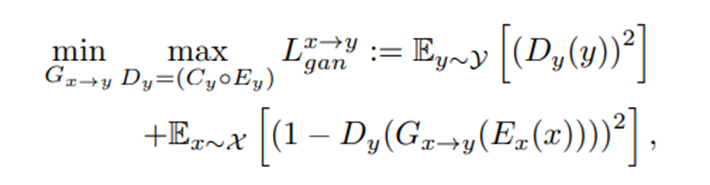
在这里,当最小化L x→y gan时,即训练判别器的时候,Ex和Ey权重冻结,都是固定的。
当最大化L x→y gan时,即训练生成器时,Ex,Ey可变。
在最小化对抗损失、重构损失和循环一致性损失时,编码器冻结权重,而在最大化对抗损失时训练编码器。
循环一致损失(Cycle-consistencyloss):
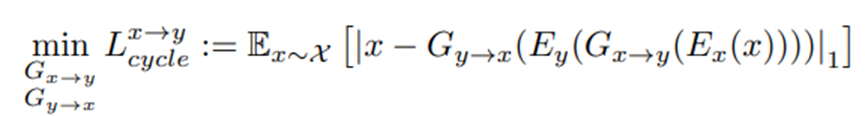
重建损失(Reconstruction loss):
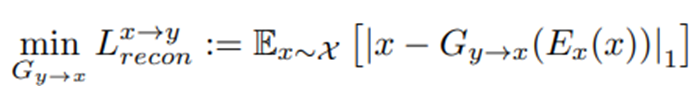
我们的重建基于共享潜在空间假设,重构损失是将源域真实样本的隐藏向量作为源域生成器的输入,使得转换到接近恒等映射。其中Ex仍然保持不变。
总损失函数:
判别器的最终目标:

生成器的最终目标:
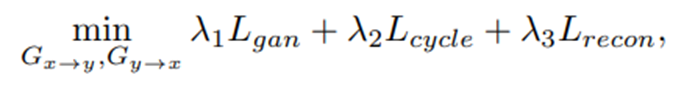
其中λ1 =1, λ2 = 10, λ3 = 10
解耦合训练策略解读:
NICE-GAN框架中的主要问题是编码器上的转换构造(translation)与判别(discrimination)之间存在矛盾的耦合——当我们通过GAN玩min-max游戏时,编码器与生成器一起训练以最小化对抗损失,而与判别器一起训练则为了使对抗损失最大化,这会导致训练目标的冲突。为了解决这个问题,作者提出了一种解耦训练策略,使编码器的训练仅与判别器相关联,而与生成器无关通过该策略——仅在最大化对抗损失(Discriminative Loss)的时候对编码器进行训练,否则将其冻结。
NICE-GAN前向传播和后向传播示意图。解耦的训练方式:在最小化对抗损失、重构损失和循环一致性损失时,编码器冻结权重,而在最大化对抗损失时训练编码器。
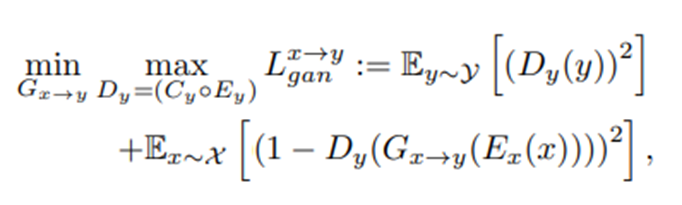
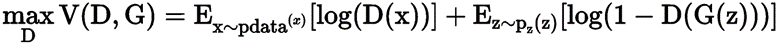
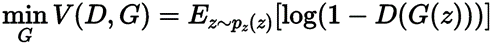
生成图像评价指标:
Human Preference:
为了比较不同方法生成的翻译输出的准确性,我们进行了人类感知研究。研究人员向志愿者展示了一张输入图像和三种不同方法的翻译输出,并给他们无限的时间来选择哪种翻译输出看起来更好。
Frchet初始距离(FID):
将生成样本的统计量与真实样本进行对比。FID对每个比较图像集的InceptionNet隐藏激活进行高斯分布拟合,然后计算Frchet距离(也称为Wasserstein-2距离),FID越低越好,对应生成的图像越接近真实

核初始距离(KID):
与FID类似,KID通过计算Inception表征之间最大均值差异的平方来度量两组样本之间的差异。此外,与所说的依赖经验偏差的FID不同,KID有一个三次核的无偏估计值,它更一致地匹配人类的感知。与FID不同的是,KID有一个简单的无偏估计器,这使得它更可靠,特别是当初始特征通道比图像数量多得多的时候。较低的KID表示真实图像和生成图像之间有更多的视觉相似性。
我们的KID实现基于https://github.com/mbinkowski/MMD-GAN,其中隐藏的表示来自Inception-v3 pool3层。
网络结构:
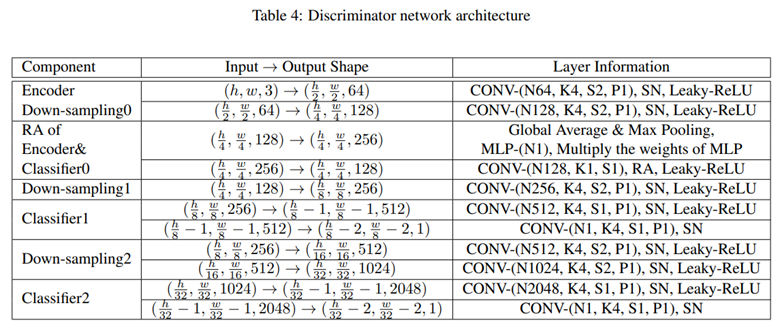
判别器网络结构:
生成器网络结构:

对于生成器网络,除最后一个输出层外,我们在解码器中使用自适应层实例归一化。对于鉴别器网络,采用Leaky-ReLU负斜率为0.2,并对各层进行光谱归一化。在AdaLIN中,我们用softmax代替clip来限制ρ∈[0,1]。此外,我们将全局平均和最大池化的特征映射在Classifier0之前拼接,使得MLP-(N1)的输入通道为256。
N是输出通道数; K为核大小; S是边长; P是padding大小
AdaLIN是自适应层实例归一化;LIN是层实例规范化;SN为光谱归一化;RA是添加residual connection在CAM层中。
ResidualAttention(RA):
对于residual attention(RA)模块,参数γ是特定于任务的。可训练参数γ决定了attended featrues和original featrues之间的权衡。γ接近0,说明更关注全局特征,因为在这些任务中,翻译图像的整体内容比关注局部细节更有必要。
















 2074
2074











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









