






Independent Encoder for Deep Hierarchical Unsupervised Image-to-Image Translation
深度分层无监督图像转化 兰州大学
文章链接:arxiv.org/pdf/2107.02494.pdf
代码:https://github.com/Elvinky/IEGAN
摘要:
图像到图像(I2I)翻译的主要挑战是使翻译后的图像逼真,并尽可能多地保留源域的信息。
为了解决这个问题,我们提出了一种新的架构,称为IEGAN,它去掉了每个网络的编码器,并引入了一个独立于其他网络的编码器。
模型优点:
1.首先,编码器不再接收来自发生器和鉴别器的损失,更直接、更全面地掌握图像信息。
2.其次,独立的编码器可以让每个网络更专注于自己的目标,这使得翻译后的图像更加真实。
3.编码器数量的减少实现了更统一的图像表示。然而,当独立编码器应用两个下采样块时,很难提取语义信息。
大多数I2I翻译框架由生成器和鉴别器组成。基于CycleGAN架构,每个生成器和鉴别器在分别转换和分类之前都进行编码。然而,生成器的编码器在I2I转换中存在编码能力瓶颈。与判别器编码器直接通过判别损失训练相比,发生器编码器接收到的梯度是由判别器反向传播的。这种训练对于发生器的编码器来说是间接的,这导致编码器学习到的隐藏向量对输入图像的响应不强。NICE-GAN提出了一种解决方案,即去掉发生器的编码器,使发生器和鉴别器共用一个鉴别器的编码器。
回顾每个组件的目标,编码器的目标是学习能够完全代表输入图像[2]特征的隐藏向量,解码器可以使用这个隐藏向量尽可能地恢复输入图像。鉴别器的最终目的是区分来自源域的平移图像和来自目标域[11]的真实图像。然而,鉴别器和编码器的目标不同,这使得鉴别器编码器学习的隐藏向量很好地完成了分类任务,但不适合生成任务。
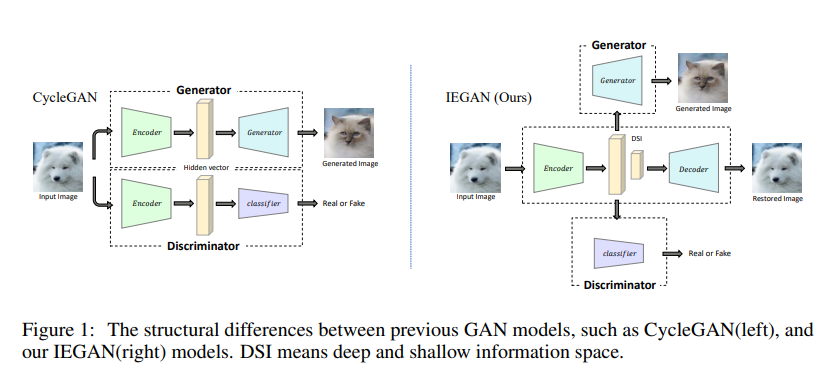
我们提出了一种新的体系结构,它细化了每个网络的目标,如图1所示。具体来说,我们去掉了生成器和鉴别器的编码器,并引入了一个独立的编码器,这意味着编码器不再受其他网络的影响。生成器和鉴别器在达到目标之前不需要编码,编码器的训练也独立于其他网络的训练。
以前的方法的性能取决于区域之间的形状和纹理的变化量。当独立编码器应用两个下采样块时,可以成功进行风格转移。但要完成具有显著形状变化的任务(例如,将猫转换为狗)是很费力的。独立编码器学习的隐藏向量只包含输入图像的特征信息(如颜色和纹理)。为了缓解这一问题,我们提出了由不同层的隐藏向量组成的深层和浅层信息空间(DSI,deep and shallow information space)。在无监督环境下,模型通过独立的编码器获得输入图像的DSI,然后要求解码器使用DSI恢复完全相同的输入图像。同时,DSI对不同层的隐藏向量进行合并和叠加,并将其传输给生成器和鉴别器。这样,生成器和鉴别器可以利用特征和语义信息来完成具有显著形状或纹理变化的任务。
方法:
该模型由四个核心网络组成:
生成器G(编码器Ex和解码器G构成)和F(编码器Ey和解码器F组成),
判别器Cx(编码器Ex和多层分类器Cx)和Cy(编码器Ey和多层分类器Cy)。
生成器需要先对图像进行编码,然后再进行转换。鉴别器首先对图像进行编码,然后对图像进行分类。但是,生成器和鉴别器实际上可以在不进行编码的情况下使用。

如果编码器嵌入到其他网络中,编码器的编码能力将受到其所属网络的限制。这是因为编码器的训练依赖于网络接收到的反向传播梯度。梯度取决于称为网络目标的损失函数。
编码器的目的是学习输入图像的DSI。
鉴别器的目标是将输入图像映射为向量,以确定域是否对齐,生成器的目标是转换另一个域中的图像,这意味着编码器的目标与生成器和判别器的目标不同。
如果编码器在鉴别器中,编码器的目标变成了分类,导致DSI丢失了与分类无关的信息。如果编码器在生成器中,编码器的损耗是由另一个网络产生的。
这样间接导致了DSI对输入图像的响应不强。
所以,编码器的训练现在不再接收其他网络产生的损失。而是接收解码器的输出图像Dx(Ex(x))和输入图像x之间的特征损失(Eq. 1)。
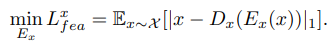
这样,编码器忽略了生成器或鉴别器的目标,专注于学习输入图像的DSI,从而保证了编码器的编码能力。同时,编码器将DSI传输给发生器G和鉴别器Cx。当编码器应用特征损失时,DSI还包含更多关于输入图像的信息。这样的编码器可以提高模型的生成能力,从而更容易翻译高质量的图像。
Ex和Ey:
当下采样块数量较小时,编码器只能获取特征信息。当下采样块数量增加时,即使编码器获得语义信息,解码器也很难恢复与输入图像相似的图像。通过在编码器和解码器之间增加跳跃式连接,构建U-net网络,可以巧妙地解决上述问题。本文利用U-net构建了一个独立编码器,即独立编码器包括一个编码器和一个解码器。为了提高编码器的编码能力,我们在编码器中加入了linear attention transformer。
生成器和鉴别器:
生成器G和F由不带编码器的U-GAT-IT-light生成器组成。该发生器包含六层AdaILN残差块和两个亚像素上采样层。鉴别器Cx和Cy由注意机制CAM和具有多尺度机制的下采样网络组成(即NICEGAN鉴别器出去编码器的结构)。
损失函数:
特征损失:除了这个损失,编码器在接下来的三次损失中保持不变。
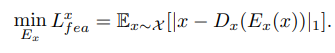
对抗损失:

循环一致损失:
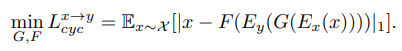
鉴别损失:
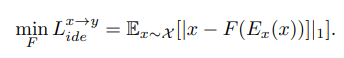
总损失函数:
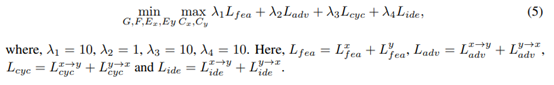
评估尺度:
FID和KID
语义信息一致性:
在I2I翻译过程中,并不是图像的每个部分都需要翻译。我们将需要翻译和不需要翻译的部分分别称为主题和背景。即使大多数时候我们只翻译主题,但背景仍然是图像信息的一部分。
背景信息从源域到目标域的丢失也是一种语义信息不一致。语义信息的一致性体现在背景信息的形状、纹理、颜色等方面。















 9415
9415











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









