






GAN Dissection: Visualizing and Understanding Generative Adversarial Networks
GAN 剖析:可视化和理解生成式对抗网络
论文地址:https://arxiv.org/pdf/1811.10597.pdf
代码:https://github.com/CSAILVision/gandissect
Demo:GAN Paint
Motivation:
作者称,论文《Network dissection:Quantifying interpretability of deep visual representations》提出,在分类网络中,当units(一个unit指一张特征图(channel=1))被上采样并阈值化之后可以近似定位到将要形成的object。
而后续工作《Interpreting deep visual representations via network dissection》提出,可以通过units和分割masks之间的一致性鉴别每个unit的语义.
同样是后续工作《Interpretable basis decomposition for visual explanation》提出,可以通过热力图解释单个网络决策,热力图高亮了网络中对分类预测贡献最多的区域.
主要思路:
毋庸置疑,生成式对抗网络证明了深度神经网络有多大的能力。机器学习生成效果惊人、高分辨率的图像这种方式是美好的,就仿佛它像我们一样理解这个世界。不过,正如其他出色的统计模型一样,它们最大的缺陷就是缺乏可解释性。
这项研究为理解生成式对抗网络带来了非常重要的进展,它让我们找到对从属于类别 c 的特定目标负责的生成器中的单位。
作者们称,我们可以观察到生成器的一个层,并且找到该层的单元的子集,在生成的图像中,这些单元决定 c 类别目标的生成。作者通过引入剖析(dissection)和干预(intervention)这两个步骤,为每一层级搜索出了一组「具有因果关系」的单元。此外,它可能是首次为理解生成式对抗网络的内部机制提供系统分析的一项工作。
符号规定:

方法:
生成器 G 可以看做是一个潜在向量 z 到一个生成图像 x 的映射:
x=G(z)![]()
我们的目标是理解内部表示 r,它是生成器 G 中某个特定层的输出。
r=hz and x=f(r)=f(h(z))=G(z)![]()
我们希望通过观察类别 c 中的目标来更近地观察 r![]() 。而我们知道 r
。而我们知道 r![]() 包含了特定目标生成的编码信息,我们的目标就是理解该信息是如何在内部被 encode 到 r
包含了特定目标生成的编码信息,我们的目标就是理解该信息是如何在内部被 encode 到 r![]() 中的。作者声称,有一种方法可以将这些单元从为类别 c 目标的生成负责的 r
中的。作者声称,有一种方法可以将这些单元从为类别 c 目标的生成负责的 r![]() 中提取出来。(目标c在locations P的生成主要依赖于前半部分,不依赖于后半部分。(这里的locations P应该是指一个坐标下,跨越多个channels的pixels集合))
中提取出来。(目标c在locations P的生成主要依赖于前半部分,不依赖于后半部分。(这里的locations P应该是指一个坐标下,跨越多个channels的pixels集合))
rU,P=(rU,P,rU,P)![]()
其中 U=(U,U)![]() 表示特定层中所有单元的集合,U
表示特定层中所有单元的集合,U![]() 表示场景单元(具有因果关系的单元,单元的意思就是单个通道的feature map),P 表示像素位置。问题是,怎样表示这一分离?作者提出了两个步骤,作为理解生成式对抗网络「黑盒」的工具:剖析和干预。
表示场景单元(具有因果关系的单元,单元的意思就是单个通道的feature map),P 表示像素位置。问题是,怎样表示这一分离?作者提出了两个步骤,作为理解生成式对抗网络「黑盒」的工具:剖析和干预。
剖析(Dissection):
用剖析测量单元 u 和 类别 c 之间的一致性。我们想要确定这些在 r 中有明确表示的场景类别。这一目标主要通过比较两张图像来实现。
首先我们按照GAN的正常过程得到第一张样本图像x,然后让它在语义分割网络中运行
这就会返回与场景(例如树)类别相关的语义分割像素位置图片scx![]() 。
。
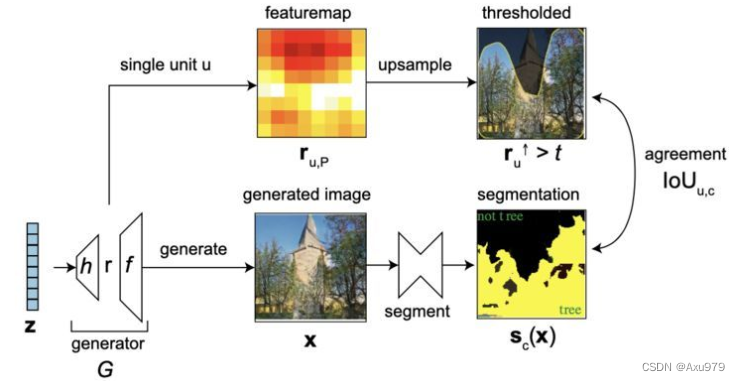
然后通过将中间层的表征向量r![]() 中分离出与类别c有关的特征图ru,P
中分离出与类别c有关的特征图ru,P![]() ,接着对该图像进行上采样处理,从而使其与图片scx
,接着对该图像进行上采样处理,从而使其与图片scx![]() 的维度匹配。之后根据固定标准的tu,c
的维度匹配。之后根据固定标准的tu,c![]() 进行二值化阈值处理,从而针对特定单元「触发」哪些像素这一难以抉择的问题作出决策。
进行二值化阈值处理,从而针对特定单元「触发」哪些像素这一难以抉择的问题作出决策。
IoUu,c≡Ez∣(ru,P↑>tu,c)∧sc(x)∣Ez∣(ru,P↑>tu,c)∨sc(x)∣,wheretu,c=argmaxI(ru,P↑>t;sc(x))H(ru,P↑>t,sc(x)),![]()
最终,我们计算出两个输出的空间一致性,空间一致性的值越高,单元 u 对类别 c 的具有因果关系的影响就越大。通过为每一单元执行这一操作,我们最终可以找出,哪些层级在 r 架构中有明确的表示。tu,c![]() 取信息质量率(information quality ratio)的最大值。它是从提前选择好的单独的验证集中计算得来的,与当前训练的数据无关。
取信息质量率(information quality ratio)的最大值。它是从提前选择好的单独的验证集中计算得来的,与当前训练的数据无关。
通过上述过程我们就得到了和实体类c相关联的单元u ,通常这些的单元会有多个,为了显示相对的重要性,需要将其进行按照IOU值的大小进行排序,顺序越靠前的自然和c的关联性越大。
在得到了一组相关的单元后,我们想知道哪些对于最后的输出样本是起到至关重要的作用呢?相关的不同的单元的组合又是如何影响最后的输出的?
干预(intervention):
用干预测量单元集 U 在类别 c 上具有因果关系的影响。现在我们尝试为每一类别找到最佳分离效果。
这就意味着一方面,我们消除(抑制)弱的单元,以期待让场景类别从生成图像中消失;而另一方面,我们又放大具有因果关系的单元对于生成图像的影响。通过这种方式,我们可以了解到它们对于显示场景类别 c 起到了多大的作用。最终,我们将类别 c 从两张图像中分割出来并进行比较。它们语义映射的一致性越小,类别的分离效果就越好。
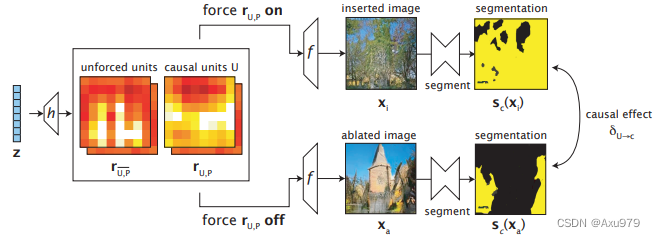
因此,按照前面的设置,当我们确定关闭某些单元时,就令rU,P=0![]() ;当打开某些单元时,就令rU,P=k
;当打开某些单元时,就令rU,P=k![]() ,k
,k![]() 这里是一个常数。然后重新分解r
这里是一个常数。然后重新分解r![]() 得到:
得到:
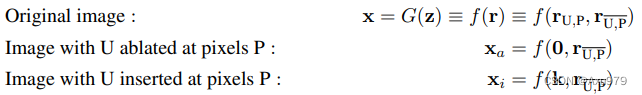
其中rU,P![]() 表示和r
表示和r![]() 无关的部分。
无关的部分。
然后,这里使用了比较xi![]() 和xa
和xa![]() 中树是否存在以及对所有位置和图像的平均效果来量化评估,即语义映射的一致性越小,类别的分离效果就越好。语义映射的一致性用the average causal effect(ACE)来衡量:
中树是否存在以及对所有位置和图像的平均效果来量化评估,即语义映射的一致性越小,类别的分离效果就越好。语义映射的一致性用the average causal effect(ACE)来衡量:
s![]()
因为相关联的单元(featruemap)不止一个,因此需要确定的是一组可以使得δU→c![]() 值达到最大的单元集合U。然而接下来会出现一个新的问题:我们相关探究相关的不同单元的组合是如何影响最后的输出,但是简单的穷举搜索所有单元组合是不大现实的。对此,作者引入了一个优化的连续干扰项α∈[0,1]d
值达到最大的单元集合U。然而接下来会出现一个新的问题:我们相关探究相关的不同单元的组合是如何影响最后的输出,但是简单的穷举搜索所有单元组合是不大现实的。对此,作者引入了一个优化的连续干扰项α∈[0,1]d![]() ,其中αU
,其中αU![]() 的每一维都表示了对于u的干涉程度。按照以下的设置,来求δU→c
的每一维都表示了对于u的干涉程度。按照以下的设置,来求δU→c![]() 的最大值:
的最大值:
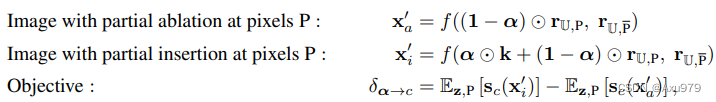
使用L2正则化来优化α![]() :
:
α*=argminα(-δα→c+λ∥α∥2)![]()
然后用SGD来寻找结果,最后α*![]() 对所有单元的组合进行排序,找出因果关系最大的单元集。
对所有单元的组合进行排序,找出因果关系最大的单元集。
去除的单元组合越多,关于数的像素数量越少,建筑的面积就越大:

实验:
1.研究和实体类相关联的单元所表示的特征是否和人们关注的特征一致:
换句话说,就是单层feature map上采样并阈值化后和在生成出的图片上对一类物体做分割得到的mask之间的相似性

可视化两个GAN中激活层中的独立单元,每个图像的单元特征被上采样和阈值化。我们可以看出,在关于餐厅(dining room)的图像中,有大量单元和桌子相关联;而在关于客厅(living room)的图像中,相关联单元最多的是沙发,这样也符合人类的判断准则。
2.研究表示某一实体时,不同相关单元的可解释性
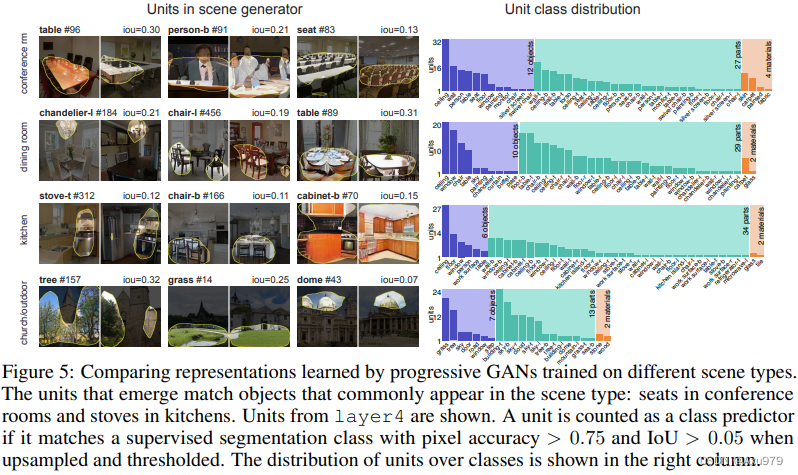
如上图所示:利用语义分割得到的结果中,GAN所关注的是天花板、人、桌子、卓伟等:在关于厨房的图像中,GAN所关注的是天花板,桌子、椅子等;从中可以看出,GAN所种带你关注的单元主和和人的关注点是一致的。
3.研究网络的不同层的单元与输出实体之间的关联性
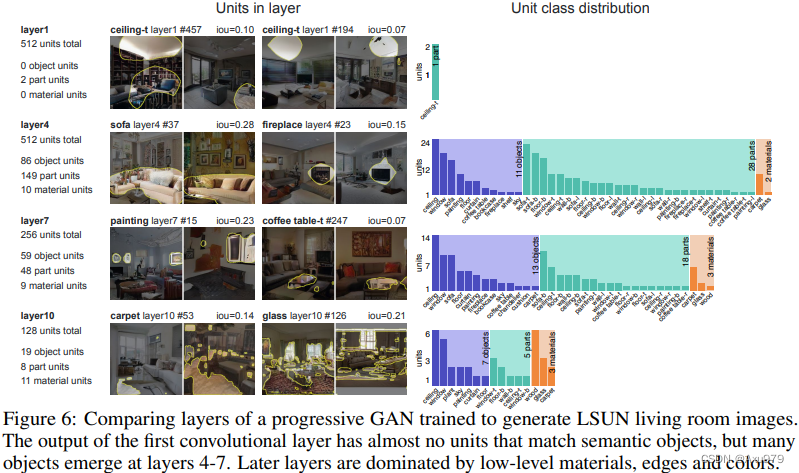
如上图所示,当网络越深时,它所包含的的单元所表达的语义信息和输出结果之间的关联越大,特别在10层以上的单元主要是匹配局部的像素模式,如材质、颜色等。
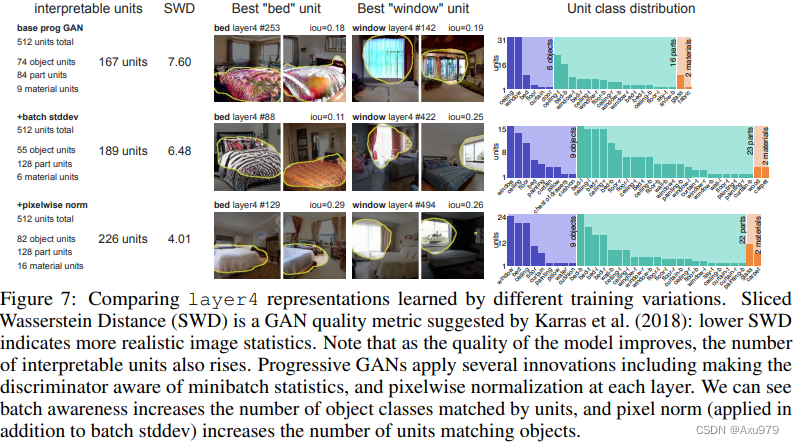
4.研究不同的模型的单元的可解释性
如上图所示,随着模型质量的提高,可解释单元的数量会增加,添加minibatch sddev statistics和pixelwise normalization对于效果都有很大的影响。作者发现,在discriminator上提供minibatch标准差,不仅提升真实性,还能提高units表示出的多样性。
5.研究为什么有时候GAN会产生不好的生成样本,以及如何改进其效果。

从上图可以看出,在质量不高的生成图像中,会有很多artifact-causing units造成的伪影(artifact),当我们将其去掉后发现,生成的样本质量有了显著的提高,并且超过了其他新的GAN的变体。
6.研究不同单元对生成图像的相对重要性

通过实验发现,在和某一实体相关联的诸多的单元中,有些一处后只是会影响图像质量,有些则根本无法移除。例如,我们可以移除会议室的窗户,但无法移除会议室的桌子和椅子。
7.研究插入的单元和原有单元的上下文关系:
在图中不同位置添加门时候发现,在大多数位置不能添加门,可以添加门的位置用黄色框突出显示,右上角图显示了门单元插入的平均因果效应,取决于干预位置的背景对象类。我们发现,GAN允许在建筑物中添加门,特别是在有窗户和砖块的合理位置,相反,在天空或者树上触发一扇门是不可能的。Intervention为我们提供了一种方法来加强对GAN如何加强对象之间的关系的洞察,例如我们试图在第四层中添加一个门,如果对象不适合上下文,那么可以否决该选择。
结果:

a) 由渐进式的生成式对抗网络生成的教堂图像; b) 给定预训练的渐进式生成式对抗网络,我们确定了对生成「树」这一场景类别负责的单元;c) 我们或者可以抑制将树从图像上「去掉」的那些单元…; d) 或者增大图像中树的密度。















 3049
3049











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









