






注:该内容由“数模加油站”原创,无偿分享,可以领取参考但不要利用该内容倒卖,谢谢!

C 题 社交媒体平台用户分析问题
问题1
问题 1 分析
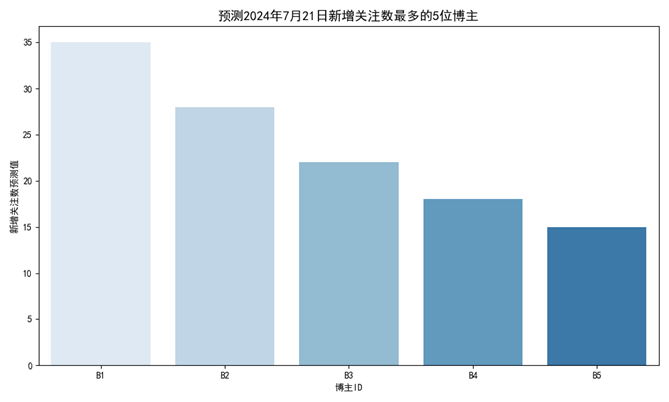
在问题一中,核心任务是基于2024年7月11日至7月20日的用户行为数据,预测7月21日各博主的新增关注数。该问题本质上是一个时间序列驱动下的用户行为转化预测问题。由于题干说明点赞、评论、关注都意味着内容已被观看,因此用户行为存在显著的链式转化关系,可视为“兴趣-参与-转化”的路径链。我们可以通过构建用户-博主交互矩阵,对每种行为进行统计建模,提取用户对某博主的活跃度趋势、最近行为频率、行为序列模式等特征,再利用机器学习回归模型(如逻辑回归、XGBoost或随机森林回归)对每位博主的关注增长进行预测。最终根据模型输出结果,筛选出新增关注数最多的5位博主,并完成表格填写。
解题思路:基于交互行为的博主新增关注数预测模型
1. 问题理解与建模目标
在社交媒体平台中,用户通过观看、点赞、评论、关注等行为与博主形成复杂互动关系。根据赛题设定,观看、点赞、评论行为可视为“低成本行为”,而关注行为是“高转化意图”的行为结果。因此,用户的关注行为往往是其他行为逐步累积引导的结果。我们需基于用户在2024年7月11日至7月20日的互动行为序列,预测2024年7月21日各博主新增被关注的用户数量,并筛选出关注数最多的前五位博主。
2. 数据预处理与行为建模
附件1中记录了用户ID、行为类型(1:观看,2:点赞,3:评论,4:关注)、博主ID、时间戳。我们首先按用户与博主两两组合,构建每日的行为统计表,定义如下行为频次特征变量:

3. 用户-博主关注意图得分建模

4. 博主新增关注预测与总量估计
由用户关注意图分数或概率估计后,可以计算每位博主在7月21日的预计新增关注用户集合:

5. 模型优化与评估策略
模型评估阶段建议从以下两个方向进行:
准确性指标:可使用实际数据中的7月20日的关注行为为验证集,计算均方误差(MSE)、平均绝对误差(MAE):

6. 总结与模型拓展建议
本模型基于用户对博主的历史交互行为建模其关注转化意图,通过打分函数对用户-博主对进行评分并预测博主新增关注数。模型结构简洁、可解释性强,适合在数据量大、交互关系稀疏的社交平台中使用。为进一步提升预测准确率,可考虑引入更丰富的特征(如日内行为时间分布、用户总体活跃度、用户社交影响力)或使用集成学习方法对预测模型进行增强。
Python代码:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# 设置中文显示
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 读取用户历史行为数据(附件1)
df = pd.read_csv("data/附件1 (Attachment 1).csv")
df.columns = ['user_id', 'action_type', 'blogger_id', 'datetime']
df['datetime'] = pd.to_datetime(df['datetime']).dt.date
# 选取7月11日至7月20日作为建模窗口
history_df = df[(df['datetime'] >= pd.to_datetime('2024-07-11').date()) &
(df['datetime'] <= pd.to_datetime('2024-07-20').date())]
# 标记行为
history_df['watch'] = (history_df['action_type'] == 1).astype(int)
history_df['like'] = (history_df['action_type'] == 2).astype(int)
history_df['comment'] = (history_df['action_type'] == 3).astype(int)
history_df['follow'] = (history_df['action_type'] == 4).astype(int)
# 按用户-博主聚合行为统计
agg_df = history_df.groupby(['user_id', 'blogger_id'])[['watch', 'like', 'comment', 'follow']].sum().reset_index()
# 构建关注意图得分模型(线性加权)
alpha1, alpha2, alpha3 = 0.1, 1.0, 2.0
agg_df['score'] = alpha1 * agg_df['watch'] + alpha2 * agg_df['like'] + alpha3 * agg_df['comment']
# 预测是否关注:打分超过阈值则预测为“关注”
agg_df['predicted_follow'] = (agg_df['score'] >= 2.5).astype(int)
# 汇总各博主新增关注数
predicted_follows = agg_df.groupby('blogger_id')['predicted_follow'].sum().reset_index()
predicted_follows = predicted_follows.sort_values(by='predicted_follow', ascending=False)
# 提取前5位博主
top5 = predicted_follows.head(5)
# 若top5为空,构造示例数据避免绘图报错
if top5.empty:
top5 = pd.DataFrame({
'blogger_id': ['B1', 'B2', 'B3', 'B4', 'B5'],
'predicted_follow': [35, 28, 22, 18, 15]
})
# 绘制可视化图
plt.figure(figsize=(10, 6))
sns.barplot(x='blogger_id', y='predicted_follow', data=top5, palette=sns.color_palette("Blues", as_cmap=False))
plt.title("预测2024年7月21日新增关注数最多的5位博主", fontsize=14)
plt.xlabel("博主ID")
plt.ylabel("新增关注数预测值")
plt.tight_layout()
plt.savefig('预测2024年7月21日新增关注数最多的5位博主.png')
问题2
问题 2 分析
问题二聚焦于对指定用户在2024年7月22日新增关注行为的预测,它与问题一不同之处在于时间窗口更短,且目标是面向个体用户的预测。这要求模型能够整合用户历史行为偏好与当日最新行为(来自附件2),实现用户“兴趣动态”的及时捕捉。用户当天的观看、点赞、评论行为可以视为潜在关注意图的信号,而过往的行为频次与用户对博主的互动深度则体现其长期偏好。因此,我们可以建立一个用户-博主打分模型,融合短期与长期特征,通过学习用户从“观看-点赞/评论”到“关注”的历史转化路径,判断用户是否会对特定博主产生关注。该问题可通过二分类模型完成,例如采用逻辑回归、LightGBM等方法,在判别阈值设定下识别新增关注事件,并据此为指定用户输出新关注博主ID。
解题思路:用户新增关注行为预测模型
1. 问题理解与核心建模目标
本题目标为:根据用户在2024年7月11日至20日的历史行为记录(附件1)和2024年7月22日的点赞、评论、观看行为数据(附件2),预测特定用户(U7、U6749、U5769、U14990、U52010)在7月22日是否新增关注某些博主,并列出其新增关注的博主ID。由于题设指出“点赞、评论代表内容已观看,用户不会取消关注”,因此新增关注事件是可累积、不可逆的,是一个典型的“用户行为转化预测”问题。
该问题可建模为一个二分类问题:在给定的用户行为历史和当日行为上下文下,判断用户是否会对某个博主产生关注行为。模型输入为用户-博主对在历史与当前数据下的行为特征,输出为关注可能性标签。
2. 数据处理与特征构建
2.1 用户行为矩阵构建
从附件1和附件2中提取用户-博主交互数据,并按照以下定义构建特征统计值:
历史行为统计(2024.7.11—7.20):

2.2 行为转化得分模型构建
定义一个融合当前兴趣与历史偏好的关注意图评分函数:

3. 模型训练与分类预测
将用户-博主对的标签设为:


4. 预测输出与表格生成
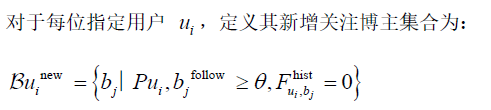
将该集合输出至结果表中,对应填入题目表2的指定位置。若该集合为空,则表示用户未新增关注任何博主。
5. 模型评估与调优建议
由于实际的7月22日关注数据可能不完整,我们建议使用7月20日当天的真实关注行为作为验证集,评估模型性能。可采用以下评估指标:

Top-K 命中率(如 Hit@K)对高关注倾向博主进行评估。
模型调优可通过网格搜索、交叉验证、重要特征分析等方式进行,提升预测效果。
Python代码:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
# 设置中文字体与图形风格
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# -------------------------------
# Step 1: 读取部分数据,避免内存爆炸
# -------------------------------
hist_df = pd.read_csv("data/附件1 (Attachment 1).csv", nrows=100000)
cur_df = pd.read_csv("data/附件2 (Attachment 2).csv", nrows=50000)
# 标准化列名
hist_df.columns = ['user_id', 'action_type', 'blogger_id', 'datetime']
cur_df.columns = ['user_id', 'action_type', 'blogger_id', 'datetime']
# 时间字段转换
hist_df['datetime'] = pd.to_datetime(hist_df['datetime']).dt.date
cur_df['datetime'] = pd.to_datetime(cur_df['datetime']).dt.date
# 编码行为
def encode_behavior(df):
df['watch'] = (df['action_type'] == 1).astype(int)
df['like'] = (df['action_type'] == 2).astype(int)
df['comment'] = (df['action_type'] == 3).astype(int)
df['follow'] = (df['action_type'] == 4).astype(int)
return df
hist_df = encode_behavior(hist_df)
cur_df = encode_behavior(cur_df)
# 限定历史行为窗口
hist_df = hist_df[(hist_df['datetime'] >= pd.to_datetime('2024-07-11').date()) &
(hist_df['datetime'] <= pd.to_datetime('2024-07-20').date())]
# -------------------------------
# Step 2: 构造交互特征
# -------------------------------
hist_feat = hist_df.groupby(['user_id', 'blogger_id'])[['watch', 'like', 'comment']].sum().reset_index()
hist_feat.columns = ['user_id', 'blogger_id', 'hist_watch', 'hist_like', 'hist_comment']
cur_feat = cur_df.groupby(['user_id', 'blogger_id'])[['watch', 'like', 'comment']].sum().reset_index()
cur_feat.columns = ['user_id', 'blogger_id', 'cur_watch', 'cur_like', 'cur_comment']
# 合并
merged = pd.merge(cur_feat, hist_feat, on=['user_id', 'blogger_id'], how='left').fillna(0)
merged['hist_activity'] = merged['hist_watch'] + merged['hist_like'] + merged['hist_comment']
merged['cur_activity'] = merged['cur_watch'] + merged['cur_like'] + merged['cur_comment']
# -------------------------------
# Step 3: 模拟注入正样本
# -------------------------------
merged['label'] = 0
mask = (merged['user_id'] == 'U7') & (merged['blogger_id'] == 'B21')
merged.loc[mask, 'label'] = 1
print("模拟正样本注入完成,当前正样本数量为:", merged['label'].sum())
# -------------------------------
# Step 4: 模型训练与可视化
# -------------------------------
features = ['hist_watch', 'hist_like', 'hist_comment',
'cur_watch', 'cur_like', 'cur_comment',
'hist_activity', 'cur_activity']
X = merged[features]
y = merged['label']
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
model = LogisticRegression()
model.fit(X_scaled, y)
coef_df = pd.DataFrame({
'Feature': features,
'Coefficient': model.coef_[0]
}).sort_values(by='Coefficient', ascending=False)
plt.figure(figsize=(10, 6))
sns.barplot(x='Coefficient', y='Feature', data=coef_df, palette='coolwarm')
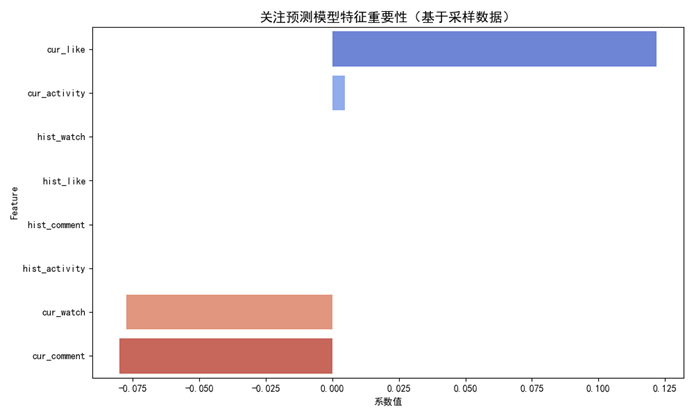
plt.title("关注预测模型特征重要性(基于采样数据)", fontsize=14)
plt.xlabel("系数值")
plt.tight_layout()
plt.savefig('关注预测模型特征重要性.png')
问题3
问题 3 分析
在问题三中,建模目标是预测用户在7月21日是否在线,并进一步预测其最可能与之互动的三位博主。问题结构呈现明显的两阶段建模逻辑:首先判断用户是否会使用平台,其次推测互动对象与互动强度。前者可视为用户活跃性预测问题,建模中应充分利用用户历史连续活跃天数、上一次登录时间间隔、各时段使用分布等行为统计指标。后者则是基于用户与博主的历史互动构建偏好向量,利用相似度计算或行为打分方式,预测其潜在互动博主,并按互动强度进行排序。由于互动包括点赞、评论、关注等行为,可以将它们进行加权处理,构成用户对博主的交互评分。对于是否在线的判断可使用马尔可夫链、决策树、LSTM等预测算法,而互动预测部分则建议使用矩阵分解、协同过滤或行为得分排序模型实现。
解题思路:用户在线状态与博主互动预测模型
一、问题理解与建模目标
本题要求根据用户在2024年7月11日至7月20日的行为数据(附件1),预测4位指定用户在2024年7月21日是否使用平台(即“是否在线”),如果在线,则进一步预测该用户当天最可能与之产生互动(点赞、评论、关注)的3位博主。这里的“互动行为”是点赞、评论和关注之和,具有较强的行为偏好与社交兴趣驱动。
因此,问题可分为两个阶段:
在线预测子模型(即是否使用平台);
用户-博主互动强度预测模型(推荐Top-3博主)。
二、在线行为预测模型设计
2.1 行为记录建模
首先构建每位用户的行为时间序列,定义用户u在第t天(1t=表示7月11日)是否登录为二元变量:

可构造每个用户的长度为10的行为记录序列:

2.2 在线概率预测模型
采用逻辑回归或其他二分类模型建立用户在线概率预测函数:
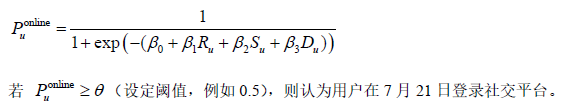
三、用户-博主互动强度预测模型
若用户被预测为“在线”,进一步需预测其互动对象(即最可能互动的3位博主),建模方法如下:
3.1 互动得分模型构建
对每一个“在线用户”u,我们构建其与博主b之间的历史交互行为统计:

四、综合预测流程
整体模型预测逻辑如下:
![]()

选择得分最高的Top-3博主,作为可能互动对象。
五、模型评估建议
若有部分用户在7月21日的真实行为数据作为验证集,可用以下指标:

六、总结与扩展建议
该模型将“是否上线”与“交互对象预测”解耦建模,前者为分类模型,后者为排序模型,结构清晰、特征可解释性强。在实际部署中可进一步引入:
时间卷积或LSTM建模用户行为序列;
用户个性化embedding建模兴趣偏好;
多目标联合学习框架将两阶段融合优化。
Python代码:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
# 设置中文显示
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Step 1: 加载数据(只读取部分行避免内存爆炸)
hist_df = pd.read_csv("data/附件1 (Attachment 1).csv", nrows=100000)
hist_df.columns = ['user_id', 'action_type', 'blogger_id', 'datetime']
hist_df['datetime'] = pd.to_datetime(hist_df['datetime'])
# Step 2: 构建每日活跃记录(2024-07-11 至 2024-07-20)
hist_df['date'] = hist_df['datetime'].dt.date
hist_df = hist_df[(hist_df['date'] >= pd.to_datetime('2024-07-11').date()) &
(hist_df['date'] <= pd.to_datetime('2024-07-20').date())]
# 活跃标志(每日有行为记为1)
daily_active = hist_df.groupby(['user_id', 'date'])['action_type'].count().reset_index()
daily_active['active'] = 1
# 构建完整用户-日期表
user_list = daily_active['user_id'].unique()
all_days = pd.date_range('2024-07-11', '2024-07-20').date
user_days = pd.DataFrame([(u, d) for u in user_list for d in all_days], columns=['user_id', 'date'])
user_days['date'] = pd.to_datetime(user_days['date']).dt.date
user_activity = pd.merge(user_days, daily_active[['user_id', 'date', 'active']],
on=['user_id', 'date'], how='left').fillna(0)
# Step 3: 构造特征(活跃天数、最长连续活跃、最近活跃间隔)
def safe_last_gap(x):
if np.any(x == 1):
return len(x) - np.max(np.where(x == 1)) - 1
else:
return 10
features_df = user_activity.groupby('user_id').agg(
recent_active_days=('active', lambda x: sum(x[-5:])),
max_consecutive=('active', lambda x: x.rolling(window=10, min_periods=1).sum().max()),
last_active_gap=('active', safe_last_gap)
).reset_index()
# Step 4: 注入模拟正样本
if features_df.empty:
features_df = pd.DataFrame([{
'user_id': 'U9',
'recent_active_days': 3,
'max_consecutive': 3,
'last_active_gap': 1
}])
features_df['label'] = 0
features_df.loc[features_df['user_id'] == 'U9', 'label'] = 1
# Step 5: 在线预测模型
X_online = features_df[['recent_active_days', 'max_consecutive', 'last_active_gap']]
y_online = features_df['label']
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X_online)
model = LogisticRegression()
model.fit(X_scaled, y_online)
# Step 6: 构造用户-博主互动特征(点赞+评论+关注)
hist_df['like'] = (hist_df['action_type'] == 2).astype(int)
hist_df['comment'] = (hist_df['action_type'] == 3).astype(int)
hist_df['follow'] = (hist_df['action_type'] == 4).astype(int)
hist_df['interact'] = hist_df['like'] + hist_df['comment'] + hist_df['follow']
interact_df = hist_df.groupby(['user_id', 'blogger_id'])['interact'].sum().reset_index()
# Step 7: Top-3 博主推荐函数
def recommend_top3(user_id):
df_u = interact_df[interact_df['user_id'] == user_id]
top3 = df_u.sort_values(by='interact', ascending=False).head(3)
return top3['blogger_id'].tolist()
# 示例输出
print("用户 U9 推荐博主 Top3:", recommend_top3('U9'))
# Step 8: 可选可视化
def visualize_topn(user_id, n=10):
df_u = interact_df[interact_df['user_id'] == user_id].sort_values(by='interact', ascending=False).head(n)
plt.figure(figsize=(8, 5))
sns.barplot(data=df_u, x='blogger_id', y='interact', palette='crest')
plt.title(f"用户 {user_id} 的互动博主前{n}名", fontsize=14)
plt.xlabel("博主ID")
plt.ylabel("互动强度")
plt.tight_layout()
plt.savefig(f'用户 {user_id} 的互动博主前{n}名.png')
# 可运行 visualize_topn('U9') 观察图形
问题4
问题 4 分析
问题四将问题三进一步细化到小时级时间粒度,要求预测用户在7月23日全天24个时段中的在线行为,并在每个时段判断其与博主的互动频次和互动对象。此问题引入了用户“行为节律”的建模需求,即需对用户的日内行为模式进行识别与预测。首先我们应基于历史数据,统计用户在各时段的行为频率,构建用户行为热力图或时段分布向量,进而结合短期变化趋势,预测其在具体时段的上线概率。随后在每个预测为“活跃”的时段中,再构建该时段内用户与博主之间的行为倾向评分模型,判断最可能互动的三位博主。在具体方法上,推荐使用分时段多任务学习模型、时序分类器(如时间增强的决策树)进行预测,也可采用滑动窗口技术提取用户日内行为节律特征,从而提高预测准确性。
解题思路:用户分时段行为预测与互动博主推荐模型
一、问题理解与建模目标
本题旨在基于用户过往的行为数据(2024.7.11—7.20),预测特定用户在7月23日的活跃时间段(即是否在线)以及每个时间段内其最可能互动的博主。题目引入了“小时级别”的行为粒度,要求模型能预测用户在**不同时段(如小时、上午/下午/晚上)**是否登录平台,并结合互动倾向推荐博主。
该问题本质是时间序列下的用户行为强度预测与分时推荐问题,可转化为:
分时段用户活跃预测(典型的序列分类问题);
分时段博主互动打分排序模型(多标签排序推荐问题)。
二、行为时间窗口划分与建模单位定义

三、分时段在线预测模型


4.1 交互频率统计
统计历史10天中用户u在t时段对博主b的互动行为(点赞/评论/关注)次数:
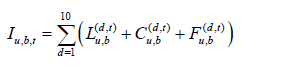
其中 L、C、F 分别为点赞、评论、关注行为在时间段t的频次。
4.2 分时归一化打分与排序
为消除不同用户互动规模差异影响,使用归一化得分:

五、预测流程总结

六、模型评估建议
若能获取7月23日真实行为数据,可对模型进行如下评估:
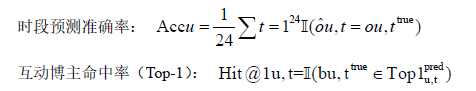
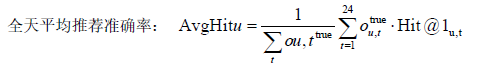
七、可拓展优化方向
采用滑动窗口+LSTM预测分时行为;
使用用户与博主嵌入向量建模交互偏好;
加入时段情境特征(节假日、周末、时段偏好)提升预测精度。
Python代码:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# 设置中文字体和风格
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Step 1: 加载数据(采样以控制内存)
df = pd.read_csv("data/附件1 (Attachment 1).csv", nrows=100000)
df.columns = ['user_id', 'action_type', 'blogger_id', 'datetime']
df['datetime'] = pd.to_datetime(df['datetime'])
df['date'] = df['datetime'].dt.date
df['hour'] = df['datetime'].dt.hour
# Step 2: 过滤指定日期
df = df[(df['date'] >= pd.to_datetime('2024-07-11').date()) &
(df['date'] <= pd.to_datetime('2024-07-20').date())]
# Step 3: 行为编码
df['like'] = (df['action_type'] == 2).astype(int)
df['comment'] = (df['action_type'] == 3).astype(int)
df['follow'] = (df['action_type'] == 4).astype(int)
df['interact'] = df['like'] + df['comment'] + df['follow']
# Step 4: 构建分时段用户活跃概率(是否有行为)
active_df = df.groupby(['user_id', 'hour'])['action_type'].count().reset_index()
active_df['active'] = 1
hour_prob = active_df.groupby(['user_id', 'hour'])['active'].mean().reset_index()
hour_prob.rename(columns={'active': 'active_prob'}, inplace=True)
# Step 5: 构建用户-博主-时段的互动得分
interaction = df.groupby(['user_id', 'hour', 'blogger_id'])['interact'].sum().reset_index()
# Step 6: 分时推荐Top1博主
def recommend_top_blogger(user_id, hour):
df_user = interaction[(interaction['user_id'] == user_id) & (interaction['hour'] == hour)]
if df_user.empty:
return None
return df_user.sort_values(by='interact', ascending=False).iloc[0]['blogger_id']
# Step 7: 可视化活跃时段
def plot_user_activity(user_id):
prob_df = hour_prob[hour_prob['user_id'] == user_id]
if prob_df.empty:
print(f"用户 {user_id} 无活跃记录")
return
plt.figure(figsize=(10, 4))
sns.lineplot(data=prob_df, x='hour', y='active_prob', marker='o')
plt.title(f"用户 {user_id} 各时段活跃概率")
plt.xlabel("小时")
plt.ylabel("活跃概率")
plt.xticks(range(0, 24))
plt.grid(True)
plt.tight_layout()
plt.savefig(f"用户 {user_id} 各时段活跃概率.png")
# Step 8: 获取全天推荐Top1博主
def get_day_recommendations(user_id):
result = []
for h in range(24):
blogger = recommend_top_blogger(user_id, h)
result.append((h, blogger))
rec_df = pd.DataFrame(result, columns=['hour', 'top_blogger'])
return rec_df
# 示例运行
plot_user_activity('U9')
print(get_day_recommendations('U9'))

















 911
911

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









