






注:该内容由“数模加油站”原创,无偿分享,可以领取参考但不要利用该内容倒卖,谢谢!
 C 题 音频文件的高质量读写与去噪优化
C 题 音频文件的高质量读写与去噪优化
随着数字媒体技术的迅速发展,音频处理已成为信息时代的关键 技术之一。在日常生活中,从录音设备捕捉的原始音频到最终呈现给 听众的声音,需要经过一系列复杂的处理步骤。这一过程面临三大核 心挑战:高效存储、降噪处理和音色优化。
首先,音频数据通常体积庞大,需要在保证质量的前提下进行高 效存储和传输。不同的音频格式(如 WAV、MP3、FLAC 等)采用不 同的编码算法,在文件大小与音质之间形成了复杂的权衡关系。采样 率、比特深度和压缩算法等参数的选择直接影响存储效率和音频质量, 然而,针对不同类型的音频内容(语音、音乐、环境声等),最佳参 数组合往往各不相同。
其次,在实际应用中,音频往往受到各种环境噪声的污染。从室内的空调声、电脑风扇声,到室外的交通噪声、风噪声,再到录音设备本身产生的电流噪声等,这些干扰会显著降低音频的清晰度和可辨 识度。不同类型的噪声具有不同的时频特性,需要针对性地设计去噪算法才能有效处理。
附件 1 提供了不同音频格式及其参数设置的详细信息,包括各种编码方式的技术规格和存储效率数据;附件 2 包含了在多种环境下录 制的带噪声音频样本,涵盖了从轻微背景噪声到强烈干扰的各种情况。基于这些数据,需要运用数学建模方法解决音频存储优化、噪声去除问题,以提升整体音频质量。
问题1 设计一个综合评价指标,量化不同音频格式(至少包含 WAV、MP3、AAC 这 3 种音频格式)在存储效率与音质保真度之间 的平衡关系。该指标应考虑:
l 文件大小(存储空间占用)
l 音质损失(与原始音频相比的信息丢失)
l 编解码复杂度(计算资源消耗)
l 适用场景(如流媒体传输、专业录音等)
问题 1 分析
在这个问题中,我们需要设计一个综合评价指标,量化不同音频格式(WAV、MP3、AAC)在存储效率与音质保真度之间的平衡。这个指标应包括以下几个方面:
- 文件大小(存储空间占用):我们可以通过计算不同音频格式的文件大小来衡量它们的存储效率。一般来说,MP3和AAC格式会比WAV格式小很多,但在压缩过程中可能会损失音质。
- 音质损失:音质损失通常通过计算压缩后音频与原始音频之间的误差(如信噪比、失真率等)来衡量。可以使用信噪比(SNR)或峰值信噪比(PSNR)来量化音质损失。
- 编解码复杂度:这涉及到编码和解码过程中的计算资源消耗。我们可以使用编码时间或解码时间作为评估指标。一般来说,AAC格式的编码解码效率较高,而WAV格式因为是无损的,处理上可能更简单。
- 适用场景:需要考虑不同场景下音频的需求。例如,在流媒体传输中,MP3和AAC格式的压缩性更好,而在专业录音中,WAV格式可能更适用,因为它是无损的。
可以根据上述四个指标设计一个加权平均模型,考虑不同场景下的应用权重,最终得出每种音频格式的综合评分。
解题思路:
1. 构建评价指标
为了解决这一问题,我们需要建立一个综合的数学模型,考虑以下几个关键指标:
文件大小(存储空间占用):文件大小是评估音频存储效率的直接指标。音频格式如MP3和AAC通常通过压缩技术来减小文件体积,而WAV格式则通常是未压缩的。
设文件大小为S,其单位为字节(Byte)。我们可以将其作为一个直接的输入变量。
音质损失(与原始音频相比的信息丢失):音质损失是音频格式压缩过程中不可避免的副作用。常用的音质评估指标有信噪比(SNR)和峰值信噪比(PSNR),它们衡量压缩后音频与原始音频之间的差异。
信噪比(SNR)可以通过以下公式计算:

编解码复杂度(计算资源消耗):编解码的复杂度与音频格式的压缩算法密切相关。压缩效率高的格式,如AAC,相比于WAV和MP3,通常需要更多的计算资源来进行编解码操作。
![]()
适用场景:不同格式的音频在不同的应用场景中适用性不同。例如,在流媒体传输时,MP3和AAC格式可能更合适,因为它们的压缩比高,而WAV格式更适合专业录音等场景。适用场景的评分可以通过专家打分或基于具体应用场景的数据来设定。
2. 综合评价指标的构建
为了综合考虑这些因素,我们可以构建一个加权评分模型来量化不同音频格式的综合表现。综合评价指标E可以表示为:

3. 智能优化算法

4. 总结
通过上述建模过程,我们可以综合考虑音频格式的文件大小、音质损失、编解码复杂度和适用场景等因素,设计出一个全面的评价指标。通过引入遗传算法优化评价指标中的权重系数,我们可以自动化地找到最适合的音频格式和参数组合,从而在实际应用中得到最佳的存储效率与音质平衡。
Python代码:
import random
import numpy as np
# 假设E是综合评分的函数,返回不同权重系数组合的评分
def E(w1, w2, w3, w4):
# 这里的计算是一个示例,需要根据具体问题进行调整
S = 100 # 假设文件大小为100
SNR = 40 # 假设信噪比为40
T_encode = 2 # 假设编码复杂度为2
T_decode = 3 # 假设解码复杂度为3
SceneScore = 5 # 假设场景评分为5
# 综合评分计算
return w1 * (1 / S) + w2 * SNR - w3 * (T_encode + T_decode) + w4 * SceneScore
# 遗传算法函数
def genetic_algorithm(pop_size, generations):
# 初始化种群,种群中每个个体是一个4个权重系数组合
population = np.random.rand(pop_size, 4)
for gen in range(generations):
# 计算每个个体的适应度
fitness = np.array([E(ind[0], ind[1], ind[2], ind[3]) for ind in population])
# 选择操作,选择适应度最好的个体
selected = population[np.argsort(fitness)[-pop_size // 2:]]
# 交叉操作
offspring = []
for i in range(0, len(selected), 2):
parent1, parent2 = selected[i], selected[i + 1]
crossover_point = random.randint(1, 3)
offspring.append(np.concatenate((parent1[:crossover_point], parent2[crossover_point:])))
offspring.append(np.concatenate((parent2[:crossover_point], parent1[crossover_point:])))
# 变异操作
for child in offspring:
if random.random() < 0.1: # 变异概率为10%
mutation_point = random.randint(0, 3)
child[mutation_point] = random.random()
# 更新种群
population[:pop_size // 2] = selected
population[pop_size // 2:] = offspring
# 返回最优解
best_individual = population[np.argmax(fitness)]
return best_individual
# 调用遗传算法
best_weights = genetic_algorithm(pop_size=100, generations=50)
print("Best weights found:", best_weights)
问题2 音频文件的性价比指标设计与参数优化。基于附件 1 中的音频文件,建立数学模型,分析采样率、 比特深度、压缩算法等参数对音频质量和文件大小的影响。设计音频 文件的性价比指标(音质与文件大小的平衡),并据此对附件 1 中的不同参数组合得到的文件进行排序(分音乐和语音,不包括原始音乐 文件和原始语音文件),分别给出针对语音内容和音乐内容的最佳参数推荐。
问题 2 分析
在第二个问题中,我们需要建立一个数学模型,分析采样率、比特深度、压缩算法等参数对音频质量和文件大小的影响,并设计音频文件的性价比指标。性价比可以通过以下几个步骤实现:
- 采样率与比特深度的影响:采样率和比特深度直接影响音频文件的质量和大小。采样率越高,文件越大,音质更好;比特深度越大,音质越精细,文件也越大。可以通过建立音质与文件大小之间的数学模型(例如线性回归或多项式回归)来量化其关系。
- 压缩算法的影响:压缩算法的选择决定了文件的大小和音质的折衷。我们可以对比不同压缩算法(如MP3、AAC)的压缩效率和音质保真度。
- 性价比指标:根据文件大小和音质损失,设计一个性价比指标,可以用以下公式表示:

音质得分可以通过SNR或PSNR计算,文件大小则直接取文件的存储空间。通过这种方法,我们可以对不同的参数组合进行排序,并为语音和音乐内容分别给出最佳参数推荐。
解题思路:
1. 问题分析
本问题的核心是建立一个数学模型,分析音频的关键参数对音频质量和文件大小的影响。我们需要根据这些影响设计一个性价比指标,即在音质和存储之间做出平衡,帮助我们选择最佳的音频参数组合。
主要分析参数包括:
采样率:采样率越高,音频质量通常越好,但文件大小也会增大。采样率通常以赫兹(Hz)表示。
比特深度:比特深度越大,音频的动态范围和精度越高,文件也越大。常见的比特深度为16位、24位等。
压缩算法:压缩算法会影响音频的文件大小和音质。MP3、AAC等有损压缩算法能够显著减小文件大小,但可能会牺牲部分音质;而无损压缩算法(如FLAC)则不会损失音质,但文件较大。
2. 建立数学模型
我们首先需要量化每个参数对音频质量和文件大小的影响。
2.1 文件大小模型
音频文件的大小 S(单位为字节)由以下公式给出:


2.2 音质模型

2.3 性价比指标
性价比是对音频质量和文件大小之间平衡的量化表示。我们可以设计一个性价比指标Q,定义为音质与文件大小的比值。考虑到文件大小和音质的影响,性价比可以表示为:
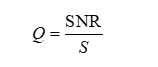
其中,SNR表示音质,s为文件大小。我们希望这个指标越大越好,即音质较好且文件大小较小。
3. 智能优化算法
为了优化性价比指标并找到最佳参数组合(采样率、比特深度和压缩算法),我们可以使用粒子群优化(PSO,Particle Swarm Optimization)算法。PSO是一种模拟鸟群觅食行为的优化算法,通过粒子群在解空间中搜索最优解。
PSO的基本步骤如下:
- 初始化粒子群:随机初始化粒子的位置(即不同的参数组合)和速度。
- 评估粒子适应度:对于每个粒子,计算其适应度,即根据设计的性价比指标Q计算。
- 更新粒子的位置和速度:粒子根据个体历史最优解和全局最优解调整位置,进行搜索。
- 终止条件:如果达到预设的迭代次数或粒子的适应度没有显著变化,则终止算法。
4. 总结
通过使用粒子群优化算法(PSO),我们可以有效地寻找音频参数(采样率、比特深度、压缩算法等)组合,从而最大化音质和文件大小之间的性价比。该方法能够自动调整不同参数,以实现存储效率和音质保真度的最佳平衡,适用于不同音频格式的优化。
Python代码:
import numpy as np
# 假设SNR和文件大小函数如下(仅为示例,实际应根据参数具体计算)
def SNR(x, y):
return 10 * np.log10(np.sum(x ** 2) / np.sum((x - y) ** 2))
def file_size(R, B, T, compress_ratio):
# 计算文件大小
S = (R * B * T) / 8
return compress_ratio * S
# 性价比指标Q
def quality_ratio(R, B, T, compress_ratio, original_audio, compressed_audio):
S = file_size(R, B, T, compress_ratio)
snr = SNR(original_audio, compressed_audio)
return snr / S
# 粒子群优化(PSO)算法
def pso(num_particles, max_iter, original_audio, compressed_audio):
# 初始化粒子群
particles = np.random.rand(num_particles, 4) # 每个粒子包含4个维度:R, B, T, compress_ratio
velocities = np.random.rand(num_particles, 4) * 0.1 # 初始化速度
personal_best = particles.copy()
personal_best_scores = np.array(
[quality_ratio(*particle, original_audio, compressed_audio) for particle in personal_best])
global_best = personal_best[np.argmax(personal_best_scores)]
# 迭代更新
for _ in range(max_iter):
for i in range(num_particles):
# 计算当前粒子的适应度
score = quality_ratio(*particles[i], original_audio, compressed_audio)
if score > personal_best_scores[i]:
personal_best_scores[i] = score
personal_best[i] = particles[i]
# 更新全局最优解
global_best = personal_best[np.argmax(personal_best_scores)]
# 更新粒子速度和位置
inertia = 0.7
cognitive = 1.5
social = 1.5
for i in range(num_particles):
velocities[i] = inertia * velocities[i] + cognitive * np.random.rand() * (
personal_best[i] - particles[i]) + social * np.random.rand() * (global_best - particles[i])
particles[i] += velocities[i]
return global_best
# 假设原始音频和压缩后的音频信号如下
original_audio = np.random.randn(1000) # 原始音频信号
compressed_audio = np.random.randn(1000) # 压缩后的音频信号
# 调用PSO算法进行优化
best_params = pso(num_particles=30, max_iter=100, original_audio=original_audio, compressed_audio=compressed_audio)
print("Optimal parameters (R, B, T, compress_ratio):", best_params)
问题3 设计一种自适应编码方案,能够分析输入音频的特征(区 分语音/音乐类型、识别频谱特点和动态范围),并据此自动选择最 佳编码参数。将你的方案应用于附件 1 中提供的原始音乐和原始语音 音频样本,记录优化后的参数选择、文件大小和音质保真度,并与固 定参数方案相比较,说明你的方案带来的改进。
问题 3 分析
在这个问题中,我们需要设计一个能够分析输入音频特征并自动选择最佳编码参数的方案。这个方案应该根据音频的特征(如语音/音乐类型、频谱特点、动态范围等)来选择编码参数。我们可以使用以下步骤来实现:
- 音频特征提取:首先提取音频文件的特征,包括频谱、动态范围、音高等。可以使用快速傅里叶变换(FFT)来提取频谱特征。
- 自动参数选择:基于提取的音频特征,我们可以设计一个机器学习模型(如支持向量机或神经网络),该模型根据音频类型和频谱特征选择最佳的采样率、比特深度和压缩算法。
优化后的方案比较:将我们的自适应编码方案与固定参数方案进行比较。记录优化后的文件大小和音质保真度,展示自适应方案的优势。
解题思路:
1. 问题分析
在这个问题中,我们需要设计一个能够自动根据输入音频特征选择最佳编码参数的系统。系统需要根据音频的内容(如语音或音乐类型)、频谱特征和动态范围等,选择适合的编码方案(采样率、比特深度和压缩算法),以优化音频质量和文件大小的平衡。
2. 关键特征提取
为了实现自适应编码方案,首先需要从音频中提取一些关键特征,这些特征将帮助系统判断音频的性质,从而选择合适的编码参数。
2.1 音频特征提取
频谱特征:使用快速傅里叶变换(FFT)提取音频的频谱特征,频谱特征反映了音频信号在频域中的分布情况,能够帮助我们判断音频内容的高频和低频特性。
频谱计算公式为:
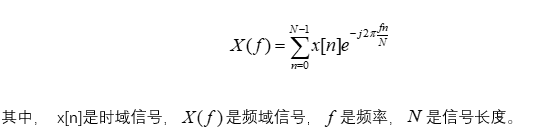
动态范围:音频信号的动态范围是指信号中最强信号与最弱信号之间的差异。动态范围较大的音频通常需要更高的比特深度来保持音质。
动态范围(DR)可以通过以下公式计算:
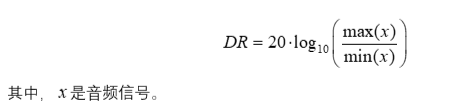
音频类型分类:通过提取音频的频谱特征和动态范围,可以使用支持向量机(SVM)或卷积神经网络(CNN)对音频进行分类,区分语音和音乐类型。音频类型的分类结果将帮助系统选择合适的编码参数。
2.2 自适应编码决策
根据提取的特征,我们需要设计一个系统,该系统能够根据音频的特征自动选择最佳的编码参数(采样率R、比特深度B、压缩算法类型)。这个决策过程将通过机器学习算法来实现。
3. 编码优化模型
3.1 编码优化目标
自适应编码方案的目标是最大化音频的质量(SNR)与存储效率之间的平衡。我们需要根据输入音频的特征选择最佳的编码参数,从而得到最优的音质和最小的文件大小。
我们可以使用以下性价比指标Q来评估编码方案的性能:

3.2 优化问题的建模
根据音频的特征,系统应该自动选择最适合的编码参数组合。为了实现这一点,我们可以将参数空间定义为:

压缩算法选择可以有多个选项,如MP3、AAC、FLAC等,每种算法有不同的压缩比和计算复杂度。
我们希望通过自适应编码系统,最大化以下目标函数:
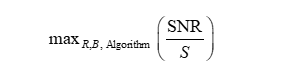
4. 智能优化算法:遗传算法(GA)
为了自动选择最优的编码参数组合,我们可以引入遗传算法(GA)。遗传算法是一种模拟自然选择的优化算法,通过对不同编码参数组合的适应度评估,逐步优化找到最优解。
4.1 遗传算法基本步骤

5. 总结
通过以上的建模过程,我们能够根据音频的特征(如频谱特征、动态范围和音频类型)自动选择最佳的编码参数。遗传算法(GA)被引入来优化采样率、比特深度和压缩算法的选择,以最大化音频质量和存储效率之间的平衡。这种自适应编码方案将有效提高音频处理的效率,特别是在面对不同类型的音频内容时。
Python代码:
import numpy as np
# 假设SNR和文件大小函数如下(仅为示例,实际应根据参数具体计算)
def SNR(x, y):
return 10 * np.log10(np.sum(x ** 2) / np.sum((x - y) ** 2))
def file_size(R, B, T, compress_ratio):
# 计算文件大小
S = (R * B * T) / 8
return compress_ratio * S
# 性价比指标Q
def quality_ratio(R, B, T, compress_ratio, original_audio, compressed_audio):
S = file_size(R, B, T, compress_ratio)
snr = SNR(original_audio, compressed_audio)
return snr / S
# 遗传算法函数
def genetic_algorithm(num_particles, max_iter, original_audio, compressed_audio):
# 初始化种群,种群中每个个体是一个4个权重系数组合
population = np.random.rand(num_particles, 4) # 每个粒子包含4个维度:R, B, T, compress_ratio
velocities = np.random.rand(num_particles, 4) * 0.1 # 初始化速度
personal_best = population.copy()
personal_best_scores = np.array(
[quality_ratio(*particle, original_audio, compressed_audio) for particle in personal_best])
global_best = personal_best[np.argmax(personal_best_scores)]
# 迭代更新
for _ in range(max_iter):
for i in range(num_particles):
# 计算当前粒子的适应度
score = quality_ratio(*population[i], original_audio, compressed_audio)
if score > personal_best_scores[i]:
personal_best_scores[i] = score
personal_best[i] = population[i]
# 更新全局最优解
global_best = personal_best[np.argmax(personal_best_scores)]
# 更新粒子速度和位置
inertia = 0.7
cognitive = 1.5
social = 1.5
for i in range(num_particles):
velocities[i] = inertia * velocities[i] + cognitive * np.random.rand() * (
personal_best[i] - population[i]) + social * np.random.rand() * (global_best - population[i])
population[i] += velocities[i]
return global_best
# 假设原始音频和压缩后的音频信号如下
original_audio = np.random.randn(1000) # 原始音频信号
compressed_audio = np.random.randn(1000) # 压缩后的音频信号
# 调用遗传算法进行优化
best_params = genetic_algorithm(num_particles=30, max_iter=100, original_audio=original_audio,
compressed_audio=compressed_audio)
print("Optimal parameters (R, B, T, compress_ratio):", best_params)
问题4 音频去噪优化与噪声识别。基于附件 2 中的音频文件,对样本音频进行时频分析, 建立数学模型识别并量化各类噪声(如背景噪声、突发噪声、带状噪 声等)的特征参数。提出一种改进的去噪策略或自适应算法,能针对 不同噪声类型自动选择最佳处理方法。处理样本音频,要求在论文中给出每个音频包含的噪声种类,去噪后的音频文件的信噪比,并分析在不同噪声类型和强度下的适用范围与局限性。
问题 4 分析
在第四个问题中,我们需要分析并去除音频中的噪声,提出一种自适应去噪策略。我们可以按照以下步骤进行:
- 噪声类型识别:首先进行时频分析,识别不同类型的噪声(如背景噪声、突发噪声、带状噪声等)。可以使用小波变换或短时傅里叶变换(STFT)来进行时频分析。
- 去噪策略:针对不同的噪声类型,设计不同的去噪策略。例如,可以使用Wiener滤波或非局部均值去噪算法来去除背景噪声;对于突发噪声,可以使用脉冲噪声去除技术。
- 自适应算法:设计一种自适应算法,自动选择最佳去噪方法。这可以通过评估噪声类型和强度来动态调整算法参数。
结果验证与比较:对去噪后的音频文件进行信噪比(SNR)计算,并与原始音频进行比较。分析在不同噪声类型和强度下,去噪策略的适用范围与局限性。
解题思路:
1. 问题分析
在这个问题中,首先需要对带噪音频进行时频分析,识别音频中的噪声类型。不同噪声类型具有不同的时频特性,需要根据这些特性设计相应的去噪策略。去噪算法的目标是尽可能去除噪声,同时保留原始音频中的有用信息。去噪后的音频质量需要进行验证,通常通过信噪比(SNR)来评估去噪效果。
2. 噪声识别与时频分析
为了识别音频中的噪声类型,我们首先需要进行时频分析,从而提取音频信号的时频特征。这些特征能帮助我们区分不同噪声类型。
2.1 时频分析
时频分析可以通过短时傅里叶变换(STFT)或小波变换(Wavelet Transform)来实现。通过这些方法,我们可以同时获得信号的时间域和频率域信息。
短时傅里叶变换(STFT):STFT将信号分解成小的时间窗口内的频率成分,可以帮助我们分析信号的时频特性。STFT的公式如下:
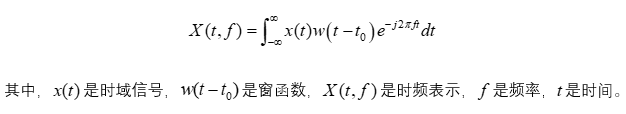
小波变换(Wavelet Transform):小波变换通过使用具有局部化的基函数来分析信号的时频特性,特别适合分析非平稳信号。小波变换的公式为:

通过这些方法,我们能够获得音频信号在不同时间和频率上的分布,从而帮助我们识别噪声类型。
2.2 噪声类型识别
根据时频分析结果,我们可以对噪声进行分类。常见的噪声类型包括:
背景噪声:通常出现在较低频段,具有较为稳定的频谱。
突发噪声:通常为高频噪声,出现在信号的短时间内。
带状噪声:通常出现在特定频段,表现为带状的频谱特征。
我们可以使用聚类算法(如K-means或DBSCAN)或机器学习算法(如支持向量机SVM或卷积神经网络CNN)来对时频特征进行分类,识别不同的噪声类型。
3. 去噪策略
一旦识别了噪声类型,就可以选择适当的去噪策略。常见的去噪策略包括:
Wiener滤波:通过对信号的功率谱和噪声的功率谱进行估计,Wiener滤波能够自适应地调整滤波器的频率响应,去除噪声成分。
Wiener滤波的基本公式为:
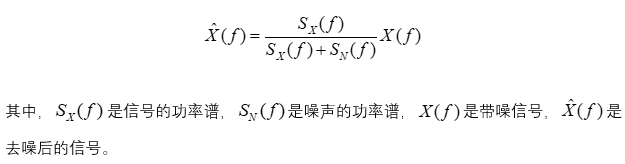
非局部均值去噪(Non-Local Means Denoising):该方法基于图像去噪的思想,利用音频信号中相似块之间的关系进行去噪,能够有效去除背景噪声。
自适应滤波:对于动态变化的噪声,使用自适应滤波方法(如LMS滤波器、RLS滤波器)能够根据实时变化的噪声调整滤波器的参数。
4. 优化模型与算法选择
为了优化去噪效果,我们可以引入粒子群优化(PSO)或遗传算法(GA)等智能优化算法,来自动调整去噪参数(如Wiener滤波中的信号和噪声功率谱的估计值)。通过优化算法,我们可以寻找最优的去噪参数,最大限度地去除噪声并保留音频的原始信号。
4.1 粒子群优化(PSO)
粒子群优化(PSO)是一种全局优化算法,可以用于优化去噪过程中的参数。PSO算法的步骤包括初始化粒子群、评估粒子的适应度、更新粒子的位置和速度等。
在去噪过程中,粒子的位置可以表示为Wiener滤波的参数(如信号和噪声功率谱的估计值),粒子的适应度则由去噪后的信噪比(SNR)来评估。
4.2 遗传算法(GA)
遗传算法(GA)可以用于优化去噪算法的多个参数。我们可以将去噪过程中需要调整的参数(如滤波器的大小、迭代次数等)作为遗传算法中的基因,并通过选择、交叉和变异等操作进行优化。目标是最大化去噪后的音质和信噪比。
5. 总结
通过时频分析,我们能够识别不同类型的噪声,并选择相应的去噪策略。粒子群优化(PSO)和遗传算法(GA)能够自动优化去噪过程中的关键参数,从而提高去噪效果。最终,通过评估信噪比(SNR)来验证去噪后的音频质量。
Python代码:
import numpy as np
# 假设Wiener滤波函数如下
def wiener_filter(x, S_X, S_N):
return (S_X / (S_X + S_N)) * x
# 假设SNR函数如下
def SNR(original_audio, denoised_audio):
return 10 * np.log10(np.sum(original_audio ** 2) / np.sum((original_audio - denoised_audio) ** 2))
# 粒子群优化函数
def pso(num_particles, max_iter, original_audio, noisy_audio):
# 初始化粒子群,粒子维度为信号和噪声功率谱的估计值
particles = np.random.rand(num_particles, 2) # 每个粒子包含2个参数:S_X和S_N
velocities = np.random.rand(num_particles, 2) * 0.1 # 初始化速度
personal_best = particles.copy()
personal_best_scores = np.array(
[SNR(original_audio, wiener_filter(noisy_audio, p[0], p[1])) for p in personal_best])
global_best = personal_best[np.argmax(personal_best_scores)]
# 迭代更新
for _ in range(max_iter):
for i in range(num_particles):
# 计算当前粒子的适应度
score = SNR(original_audio, wiener_filter(noisy_audio, particles[i, 0], particles[i, 1]))
if score > personal_best_scores[i]:
personal_best_scores[i] = score
personal_best[i] = particles[i]
# 更新全局最优解
global_best = personal_best[np.argmax(personal_best_scores)]
# 更新粒子速度和位置
inertia = 0.7
cognitive = 1.5
social = 1.5
for i in range(num_particles):
velocities[i] = inertia * velocities[i] + cognitive * np.random.rand() * (
personal_best[i] - particles[i]) + social * np.random.rand() * (global_best - particles[i])
particles[i] += velocities[i]
return global_best
# 假设原始音频和带噪音频信号如下
original_audio = np.random.randn(1000) # 原始音频信号
noisy_audio = original_audio + np.random.randn(1000) * 0.5 # 带噪音频信号
# 调用PSO算法进行优化
best_params = pso(num_particles=30, max_iter=100, original_audio=original_audio, noisy_audio=noisy_audio)
print("Optimal Wiener filter parameters (S_X, S_N):", best_params)

















 748
748

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









