






主要内容:隐语机器学习算法介绍,不同机器学习算法的安全假设
讲师:胡东文—SF联邦学习工程方向负责人
环境:我们以v1.6.1b0版本为例,通过secretnote进行介绍。
一、预处理和隐私求交
1. 数据结构:DataFrame 和 FedNdarray
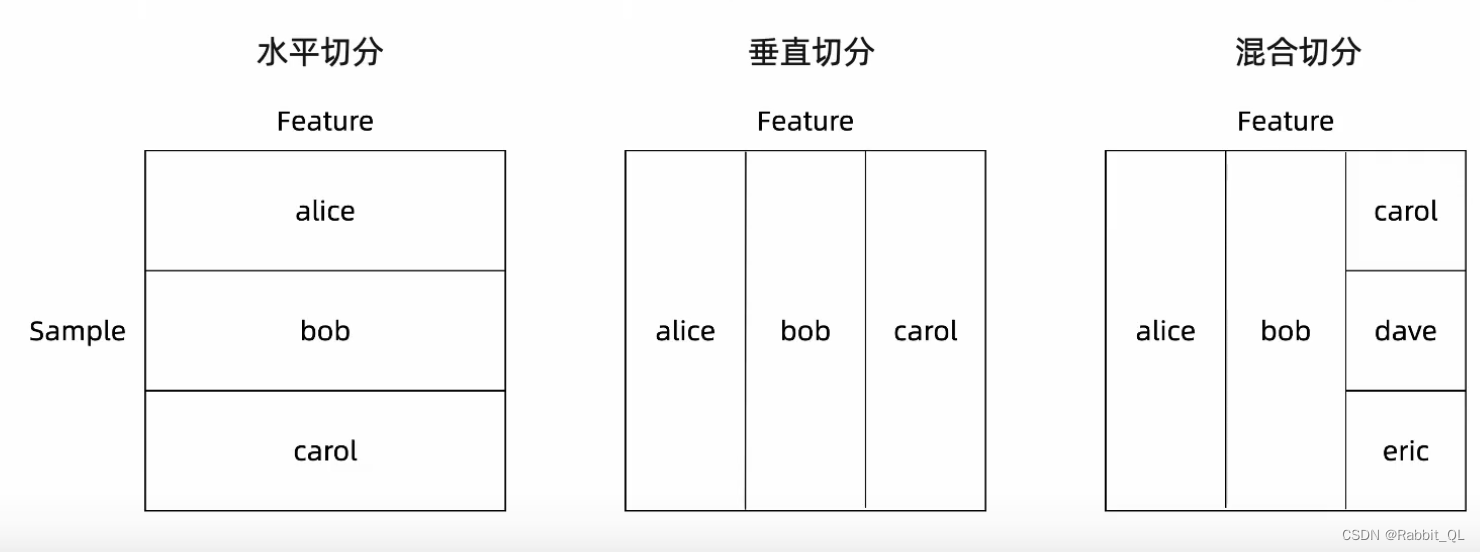
(左:HDtaFrame、中:VDataFrame、右:MixDataFrame)
-
构建联邦表
联邦表是一个跨多方的虚拟概念。
联邦表中各方的数据存储在本地,不允许出域。
-
除了拥有数据的一方之外,没有人可以访问数据存储。
-
联邦表的任何操作都会由Driver调度给每个Worker,执行指令会逐层传递,直到特定拥有数据的Worker的Python Runtime。
-
框架确保只有 Worker.device 和 Object.device相同的时候才能够操作数据。
-
联合表旨在从中心角度管理和操作多方数据
-
接口方面和
pandas.DataFrame对齐,以降低多方数据操作的成本。
-
-
DataFrame
与pandas的DataFrame类似,作为联邦表格数据的封装。DataFrame由多个参与方的数据块构成,支持数据水平、垂直切分和混合切分,分别对应3组API:HDataFrame、VDataFrame、MixDataFrame。
-
VDataFrame底层如下:
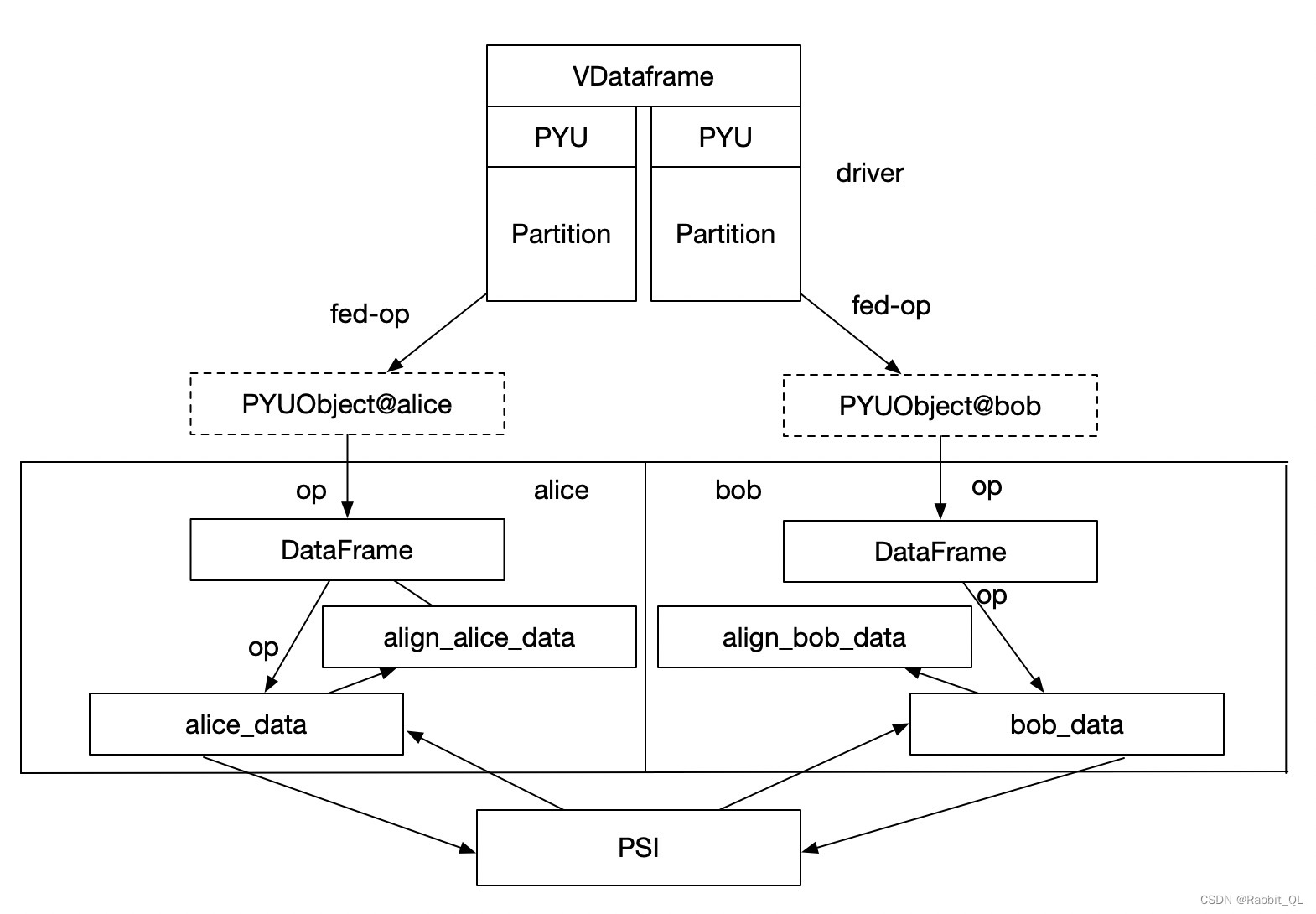
-
-
FedNdarray
与numpy的ndarray类型,作为联邦ndarray的封装,同样由多个参与方的数据块构成,支持水平切分和垂直切分,对应统一的API:FedNdarray
2. 如何进行预处理
DataFrame和FedNdarray提供了一些读写api可供直接使用。
-
可以直接使用DataFrame API处理数据
在SecretFlow中提供了类似于
pandas.read_csv的接口来将各方数据的CSV读取成为一个联邦数据集。-
对于水平场景有
secretflow.horizontal.read_csv。 -
对于垂直场景有
secretflow.vertical.read_csv。首先准备好两方的数据csv文件,垂直场景两方数据并不强制要求对齐,因为这里提供了PSI的能力。
-
Alice: datapath (alice机器能访问到的本地路径)
-
Bob: datapath (bob机器能访问到的本地路径)
垂直场景是各方的schema不同,但是每一方都拥有每一个column的全部数据。不再需要比较器和聚合器。但是各方数据不一定是对齐的,我们需要在读取时候通过
PSI来进行数据对齐。-
path_dict:数据路径
-
spu: 用于求交使用的spu设备
-
keys: 用于求交的keys(支持多列求交)
-
drop_keys: 求交后需要删去的ID列名
from secretflow.data.vertical import read_csv v_alice_path = "/root/vertical_cancer_party1.csv" v_bob_path = "/root/vertical_cancer_party2.csv" alice, bob = sf.PYU('alice'), sf.PYU('bob') path_dict = { alice: v_alice_path, # The path that alice can access bob: v_bob_path, # The path that bob can access } vdf = read_csv(path_dict)</span> -
-
-
使用
VDataFrame/HDataFrame本身提供的数据处理方法-
count用于统计非缺失值数据量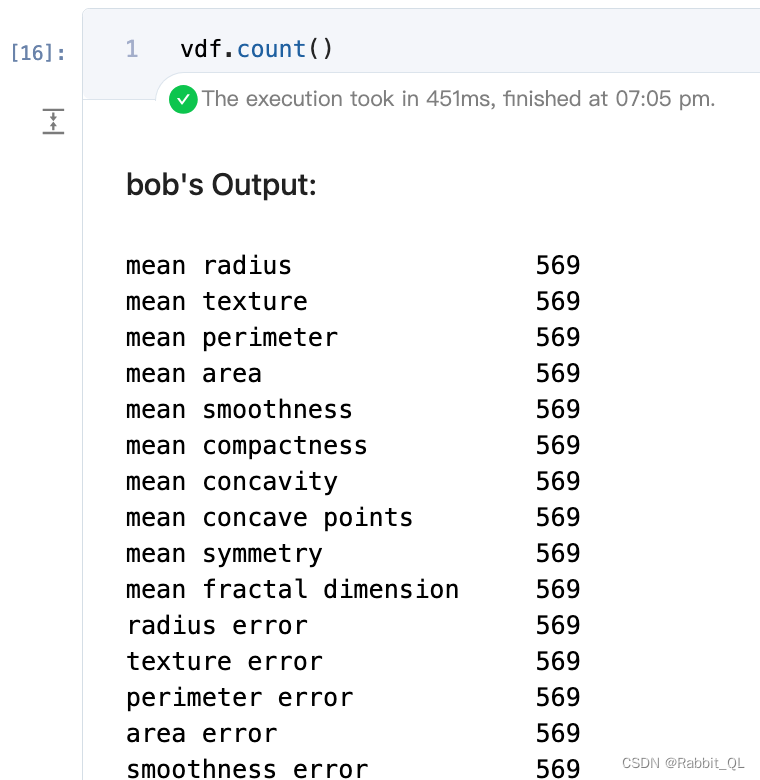
-
fillna用于填充缺失值:指定特征和填充值
-
-
使用
sf.preprocessing包含的各类预处理组件处理
from secretflow.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scaled_vdf = scaler.fit_transform(vdf[["worst area", "worst symmetry"]])-
例如,这里进行MinMaxScaler处理,转换之后的range应该在[0,1]

-
安全提示:一些预处理算子会计算并公开用于辅助计算的统计值,或者一些统计接口本身就会计算和公开统计值。请在使用前仔细评估这些统计值是否包含隐私信息。
例如,是否能够公开最大值/最小值。
3. 隐私求交PSI
隐私求交(Private Set Intersection)是一种使用密码学方法,获取两份数据内容的交集的算法。PSI过程中不泄露任务交集以外的信息。
-
在垂直拆分场景中,隐私求交常用于第一步的数据对齐,然后可以进一步做数据分析或机器学习建模。同时,数据对齐本身也可以作为一个独立的功能。
-
因此,在隐语中 PSI 有两种使用方式,分别如下:
-
spu.psi接口
-
data.vertical.read_csv接口
-
-
同时隐语支持多种 PSI 算法,可根据参与方数量、带宽、算力、数据不平衡度等不同场景合理选择。
二、决策树模型和线性回归模型
1. 决策树模型
隐语支持多种决策树算法(XGB),同时支持回归和二分类训练,可根据使用场景和安全性需求选用。
| 算法 | SS-XGB | SecureBoost | 水平XGBoost |
|---|---|---|---|
| API | secretflow.ml.boost.ss_xgb_v.Xgb | secretflow.ml.boost.sgb_v.Sgb | |
| 场景 | 垂直切分 | 垂直切分 | 水平切分 |
| 安全性 | 可证安全,安全性依赖使用的秘密分享协议安全性 | 非可证安全,存在可能导致数据泄露的已知攻击 | 非可证安全性,泄露的中间信息可参考文档(SecretFlow) |
| 性能 | 通信成本更高,一般情况下会更慢 | 计算量更大,但通信量小,通常来说更快 |
2. 线性回归模型
隐语支持多种线性回归模型,满足不同的使用场景,并有一些针对性的优化。

-
SSRegression是纯秘密分享实现的,通信量较大。
三、神经网络算法
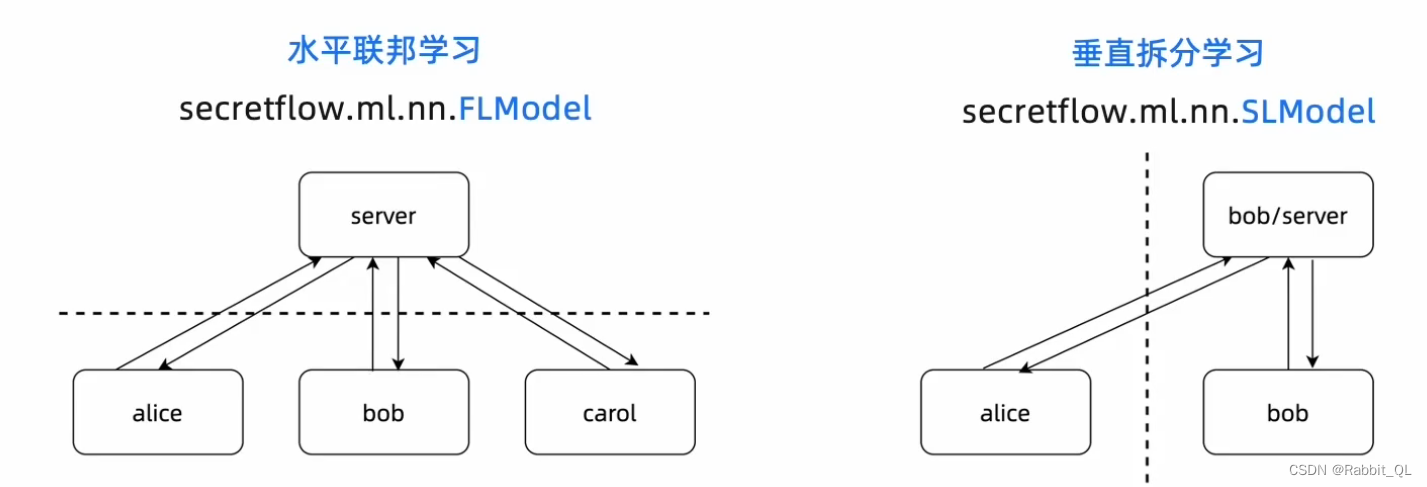
根据使用场景不同,隐语提供了两种神经网络算法:水平联邦学习、垂直拆分学习。
-
注意:水平联邦学习和垂直拆分学习都属于非可证安全算法,其安全性需要根据场景具体分析。可以通过一些安全加固组件(安全聚合、差分隐私、稀疏化等)加强安全性。
1. 水平联邦学习
-
隐语提供的水平联邦学习 FLModel是一个通用的范式,而不是一个具体的模型或算法,您可以自由的定义模型和训练参数
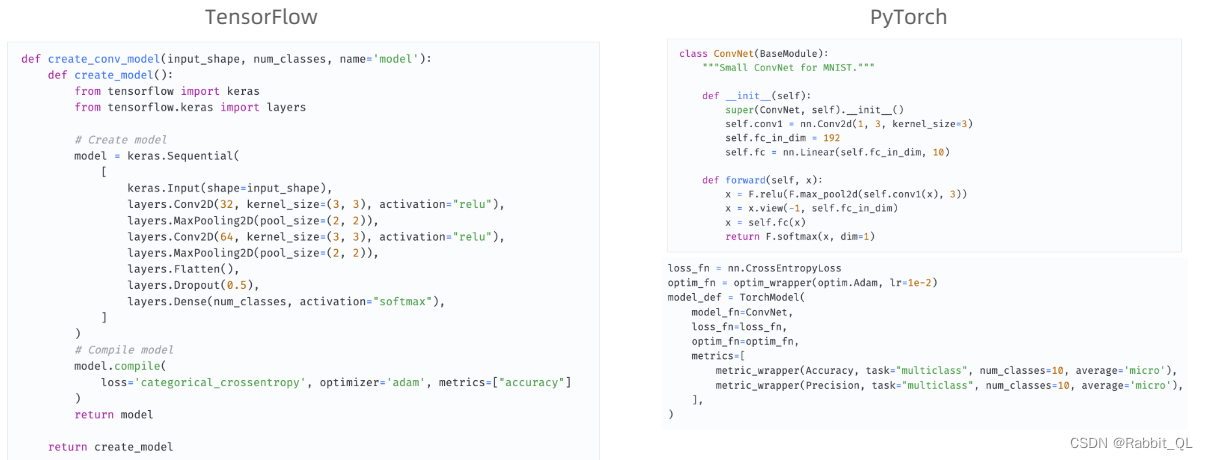
(1) 原生TensorFlow和PyTorch后端定义模型
目前 FLModel 支持 TensorFlow 和 PyTorch 两种后端,您可以使用 tf 或 torch 原生的方式编写模型代码,然后使用FLModel 训练。
-
标准的模型定义
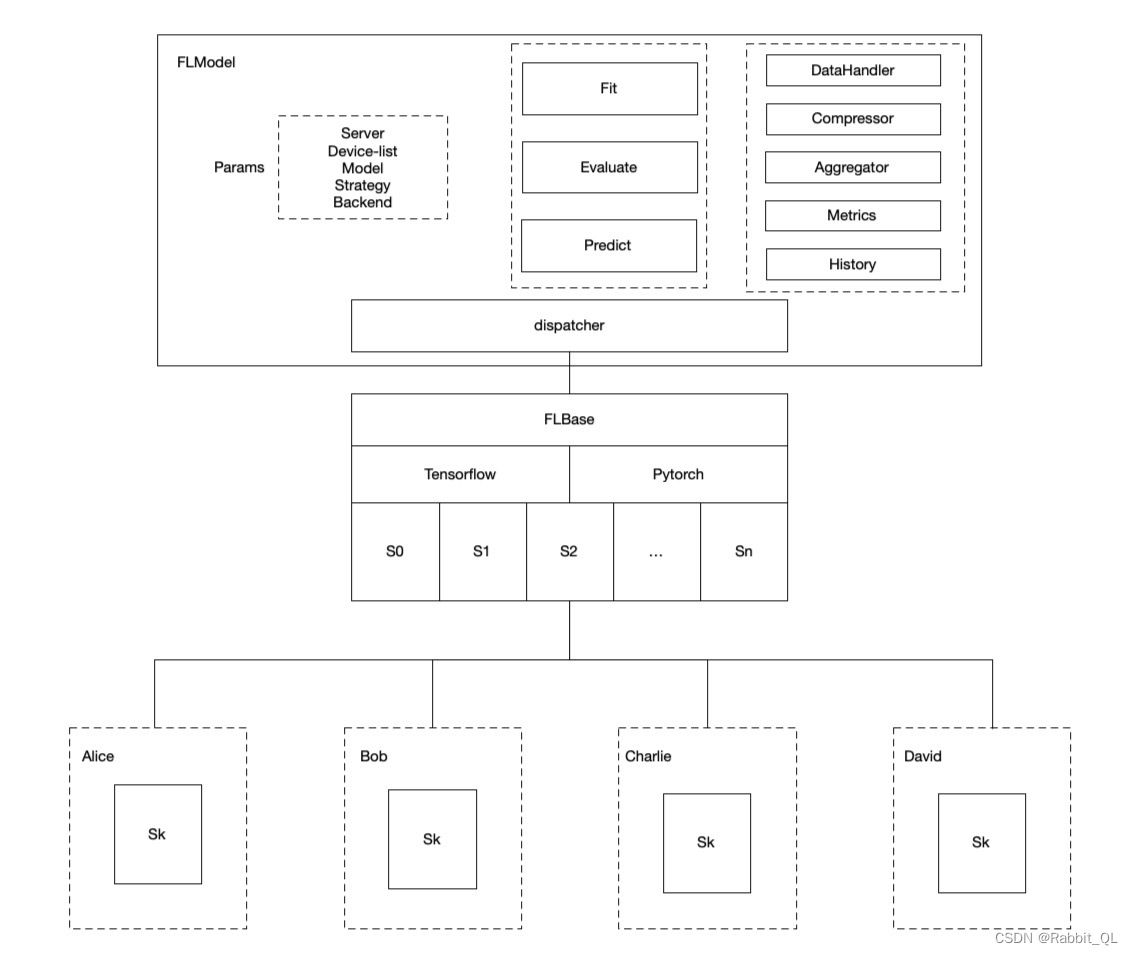
(2) FLModel
FLModel 是隐语封装好的水平联邦模型训练器,他提供了丰富的选项。
FLModel 是 SecretFlow 提供的联邦学习的逻辑抽象,也是对用户的统一接口。FLModel 封装了联邦学习框架下所需的各类能力,包括数据处理、训练策略、聚合逻辑等。SecretFlow 提供了友好的用户接口,用户可以通过 FLModel 接口轻松快速地迁移已有的明文计算模型,通过简单的迁移快速形成联邦学习能力,实现多方联合建立联合模型,学习成本低。
SecretFlow 从中心化的角度提供了 FLModel 模块,联邦的整体逻辑流程由 FLModel 来编排,FLModel 根据参数来决定由哪些 worker 执行,这些 backend 会相互配合完成联邦计算。
secretflow/secretflow/ml/nn/fl/fl_model.py at v1.6.1b0 · secretflow/secretflow · GitHub
fed_model = FLModel(
server=charlie,
device_list=[alice,bob],
model=model_def,
aggregator=secure_aggregator,
strategy="fed_avg_w",
backend = "tensorflow")fed_model = FLModel(
server=charlie,
device_list=[alice,bob],
model=model_def,
aggregator=secure_aggregator,
strategy="fed_avg_w",
backend = "tensorflow")参数:
-
server: 哪个PYU对象作为Server
-
device_list:参与方列表
-
model:定义的模型列表
-
aggregator: 用于安全聚合
-
strategy: 可以选择内置或者自定义的安全聚合算法,隐语内置了多种安全聚合策略
-
backend: 可以选择训练后端 TensorFlow 或者 PyTorch
-
可以自定义数据加载器,隐语支持 DataFrame、文件、图片等各种数据加载器
-
可以选择内置或者自定义的安全聚合算法,隐语内置了多种安全聚合策略
-
在FLModel中,根据策略名决定在服务端如何计算。可以选择内置或者自定义的联邦学习策略,隐语内置了多种联邦策略(fed-average)用于优化训练效率、non-iid 等问题。
(3) 可以使用成熟的模型库
您也可以直接使用各种封装好的模型库,比如:torchvision 和 tf.keras.applications
2. 垂直拆分学习
隐语提供的垂直拆分学习 SLModel 同样是一个通用的范式,您可以自由的定义模型和训练参数。
SLModel 同样支持 TensorFlow 和 PyTorch 两种后端,您可以使用 tf 或 torch 原生的方式编写模型代码,然后使用SLModel 训练。
与水平联邦相比,垂直拆分学习的架构略有不同,他的模型被拆分成 2 份、3 份或者更多,分别分布在不同的参与方。建模时需要针对拆分学习架构重新设计模型结构。下面是两方场景下常见的两种结构。
-
为此,隐语提供了一个拆分好的模型库:
sf.ml.nn.applications
-
两类Split Learning
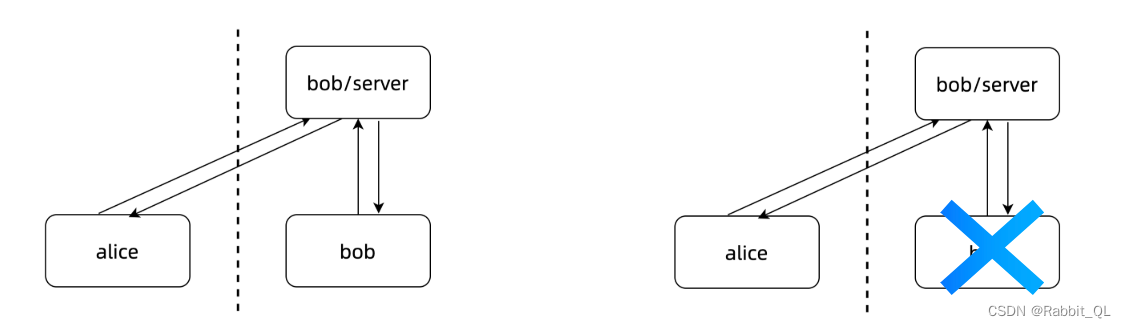
-
左图每个特征都拥有特征,其中一方有label
-
一方有所有特征,一方只有label
-
-
SLModel 作为隐语封装好的垂直拆分模型训练器,他也提供了丰富的选项:
-
可以自定义数据加载器,隐语支持 DataFrame、文件、图片等各种数据加载器
-
可以选择内置或者自定义的通信优化算法,隐语内置了多种稀疏化和量化压缩算法
-
可以选择内置或者自定义的垂直拆分策略,隐语内置了多种加速训练的策略算法
-
可以选择训练后端 TensorFlow 或者 PyTorch
-
3. 策略
(1) Strategy介绍
在联邦学习中,Strategy主要由两部分组成:
-
本地部分的局部训练策略,包括损失函数的控制(如何对齐服务器端等)、如何将梯度或参数传到上游;
-
服务器部分的策略,包括如何聚合Client上传的梯度或参数、如何更新、如何分发到下游
SecretFlow在FLModel下封装了一层Strategy,用于控制联邦场景下模型的学习策略。lingo提供了Strategy Zoo,目前支持涵盖Non-iid和通信优化等各种策略,并不断迭代更新。用户只需传递不同策略的别名(fed_avg_w、fed_avg_g、fed_prox、fed_scr等)即可完成调用。同时Strategy框架支持用户自定义策略的开发、注册和使用。
-
在Worker中定义如何进行本地计算,计算完要上传哪些参数(g/w),是否压缩等。
-
为用户二次开发新策略提供友好的界面,用户只需要定义train_step并提供聚合逻辑即可完成策略的开发。同时,用户只需要一行代码即可完成注册。
(2) Strategy的组成
strategy由三部分组成:
-
Local_strategy:训练步骤本地部分的计算逻辑,以及需要传输的张量内容
-
Compressor:上下游数据传输的压缩方法
-
Server Strategy:服务器部分的聚合逻辑















 1749
1749











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









