







 SecureNN提出一种三服务器设置下的神经网络安全训练方案,通过加法秘密共享实现矩阵乘法、激活函数和最大池化等功能,相比现有技术在准确率、性能和安全性上均有显著提升。
SecureNN提出一种三服务器设置下的神经网络安全训练方案,通过加法秘密共享实现矩阵乘法、激活函数和最大池化等功能,相比现有技术在准确率、性能和安全性上均有显著提升。
SecureNN: 3-Party Secure Computation for Neural Network Training
论文在这种三个服务器的设置下,为神经网络中一些常用函数建立了特定的算法协议,像矩阵乘法,激活函数,最大池化函数这些。我们之前读过的论文中处理这些神经网络中的函数大多会使用同态加密、混淆电路、不经意传输这些,但是这篇论文都没有用到,只是通过三方安全计算的方法,用加法秘密共享进行计算,没有用到什么特别的密码学的技术
 三个方面突破
三个方面突破
第一点就是准确率的提高。
他们的技术能够在MNIST数据集上产生大于99%的推理准确率。而当时18年安全神经网络训练的最新技术SecureML准确率只有93.4%
第二点是性能上的
SecureNN比以往的这种在两个到三个服务器上方案,例如SecureML, MiniONN, Chameleon, 还有前不久读过的Gazelle 有6-113倍的提高
第三点是安全性
以往的协议只支持半成实敌手,这个不仅是半成实安全,还多了一个恶意敌手安全可确保恶意服务器即使从协议中任意偏离,也无法了解诚实客户端的输入或输出的任何信息(只要没有向敌手透露计算的输出
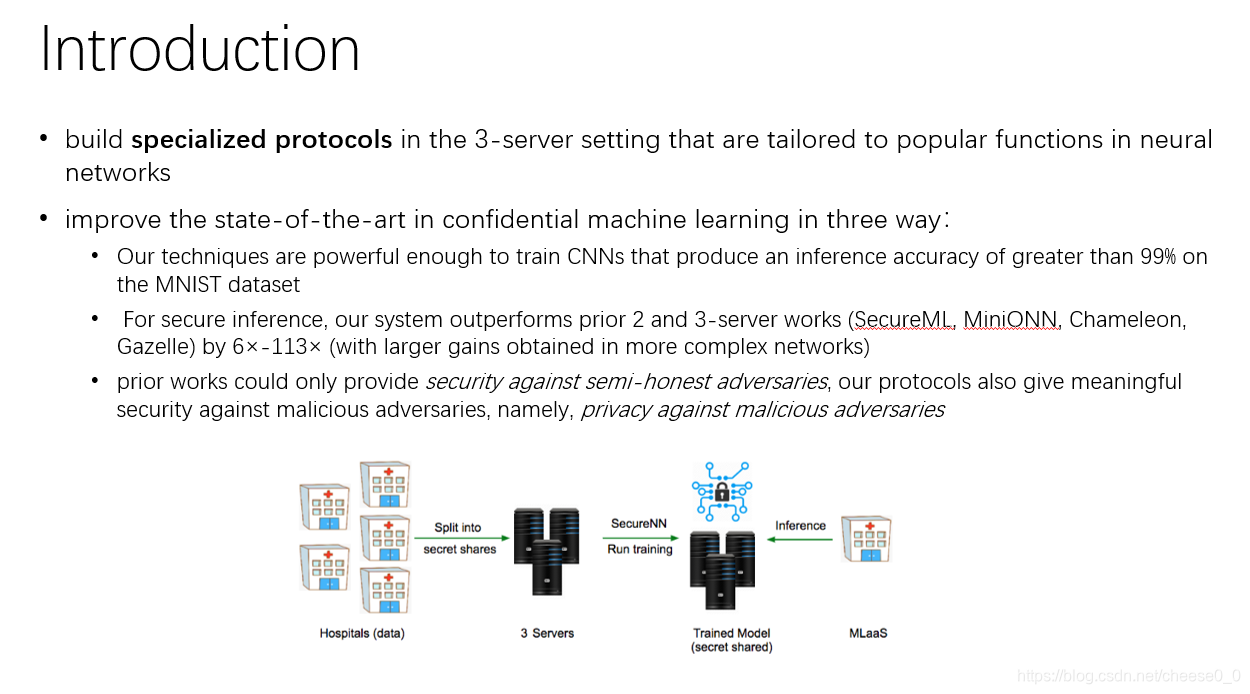
应用场景:
一组医院,每个医院都有敏感数据(如患者的心率读数、血型、血糖水平等),把这些数据分给服务器,然后就可以使用作者提出的方案secureNN来训练模型,就可以进行这个机器学习服务(MLaaS),帮助预测某些疾病或不健康行为。系统可以设置为患者的敏感输入和预测输出只向患者显示,而对其他人隐藏。

Overview
前面也说此前大多数技术会使用混淆电路来处理非线性层,就是最大池化和激活函数,而这篇论文是使用布尔计算来处理这些,可以带来更低的通信开销,更好的性能
用P0、P1和P2表示这三个服务器,这三个服务器不是完全等价的。
在所有子协议开始时,三方中的两方P0和P1持有协议输入的2/2加法秘密共享,在协议结束时,同样还是P0和P1持有2/2的输出份额。
尽管对于所有的协议, 只有P0和P1拥有输入和输出的份额,但P2也在协议期间参与了真正的计算,也是不能不要的
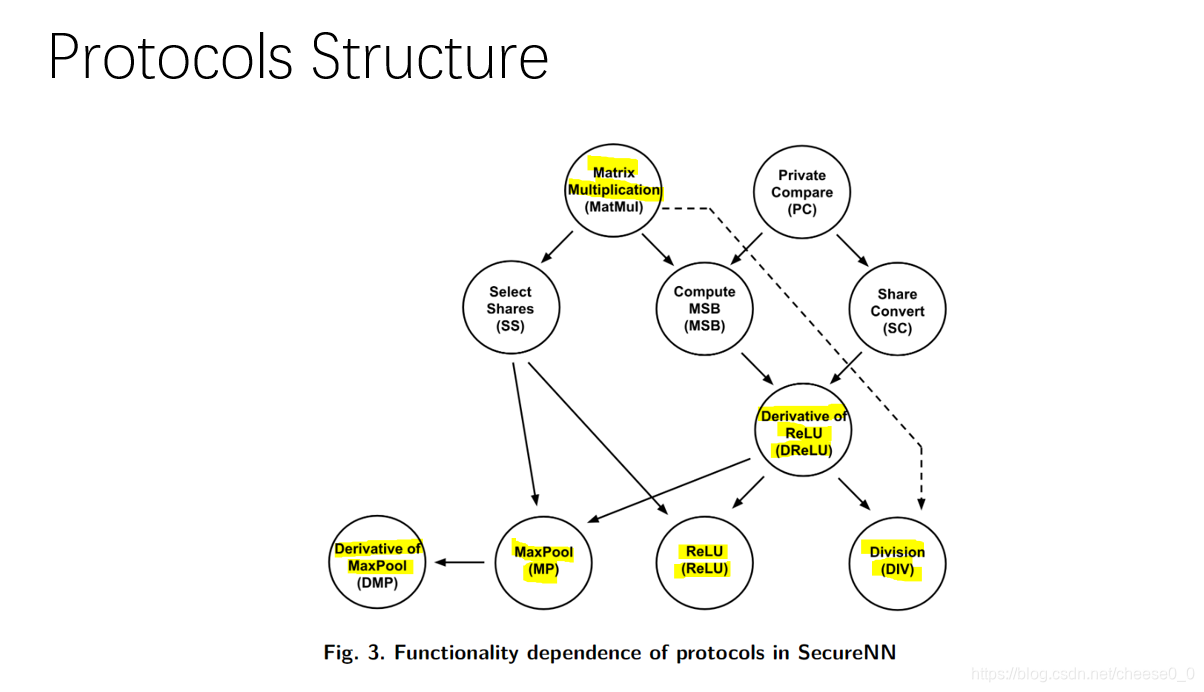
Protocols Structure
这是协议的结构,标注黄色的这几个是主要部分,线性层的矩阵乘法、非线性层的池化、激活函数,这都是神经网络里面函数,需要实现的功能,剩下的这四个其实包括矩阵乘法是子协议,下面的算法会对他们进行调用,这种结构和之前读过NDSS2020的一片很相似。也是一层一层的。
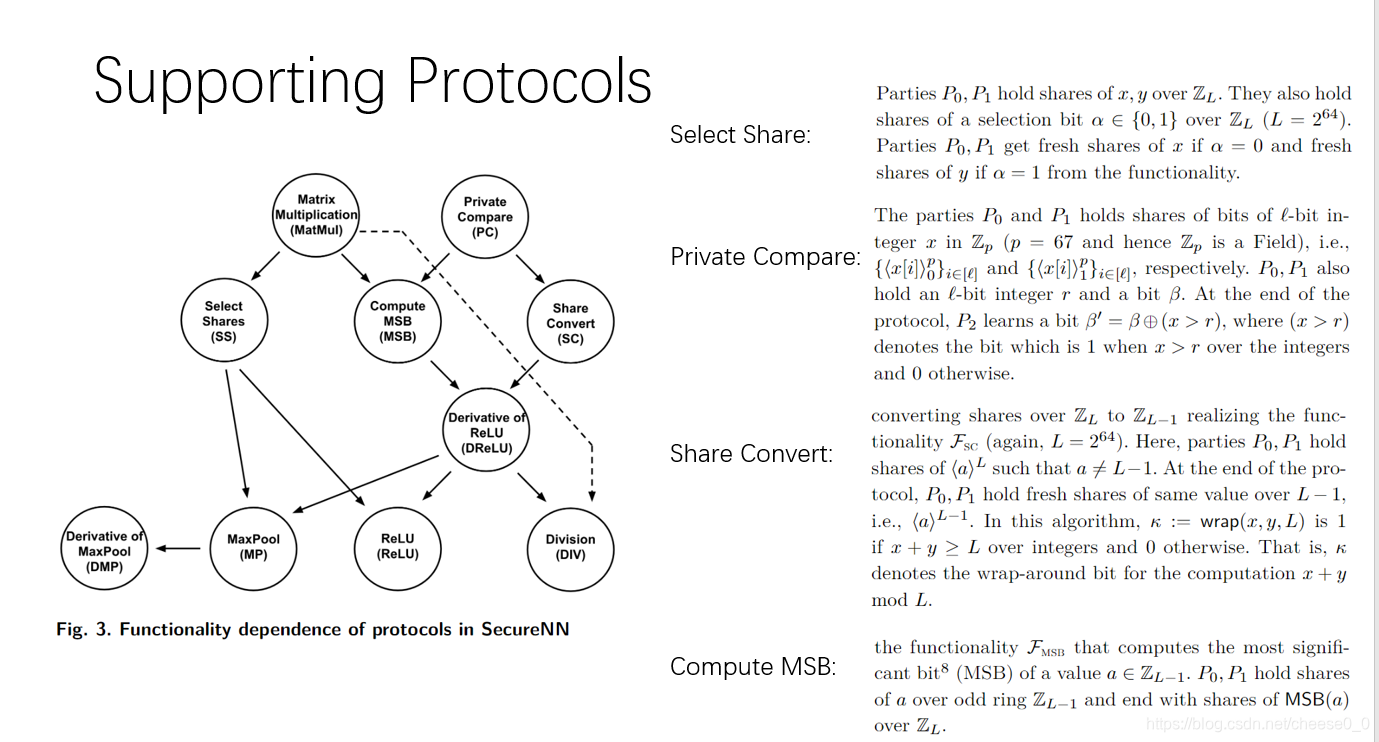
Supporting Protocols
这四个叫Supporting Protocols,论文中都给出了算法,有的是作者提出的,有的是作者在前人的工作上面改动的。我就简单说一下这些Supporting Protocols的实现的功能,算法细节我就不展开了。
Select Share:
选择共享
P0和P1拥有x和y,还有一个比特阿尔法的加法共享(这里的x和y是这个池化函数和激活函数算法中计算过程的一步,所以在这里不考虑他的实际意义)
它实现的功能是,如果这个α为0,那就把x的加法共享更新一下,比如之前是r,x-r的方式加法共享,这里换一个新的r,也就是r’,x-r’这样子的加法共享。如果α为1,就对y的加法共享更新一下
Private Compare:
这个就是一个比较,P0和p1拥有x的加法共享,已知整数r和一个比特β,这个算法实现的就是对x和r的一个比较,如果x<=r,p2得到β,如果x>r,参与方p2得到β非。
Share Convert:
它的作用是把l环上的秘密共享转换成l-1(奇数环)上的秘密共享,转化的目的是,下面的MSB算法需要在奇数环上实现。
Compute MSB:
MSB就是the most significant bit也就是取最高比特位

Linear and Convolutional Layer
这里是一个卷积的实现,看这个的例子
例子是一个两维的卷积,3x3的输入矩阵与2X2的过滤器,过滤器在矩阵上面扫描时,是先扫描x1x2x4x5这样一个2X2的范围,对应位相乘在求和,然后是x2x3x5x6,也是对应位相乘再求和。所以作者把他们这样的扫描相乘求和的过程,转化成右边这样矩阵和向量相乘的形式
转换成矩阵乘法之后,就有右图的算法,输入是矩阵和向量的加法共享大x和大y,输出是相乘后的结果的加法共享
这过程中,p2会生产两个随机矩阵a和b以及其乘积c,并将其加法共享发送给p0和p1。这个其实就是一个常见的,掩码的作用,在最后的计算中可以抵消掉。

ReLU
这个relu的激活函数是当 a为正数时,结果为它本身,否则,结果为0,。
作者在实现这个激活函数之前,引入了一个relu撇
if MSB(a) = 0(也就是a为正数)ReLU′(a) = 1, else ReLU′(a) = 0
P0和p1输入a的加法共享
首先计算c = 两倍的a,这一步的原因是在奇数环中,a的最高位等于2a的最低位,这是为下面计算msb做准备的。
进而调用Share Convert:和msb得到最高位阿尔法
第四部pj输出 γj = j – αj+uj 其实就是γ = 1-α
接下来的激活函数计算 ,就是这个式子ReLU(a) =ReLU′(a)·a
先调用左边的算法,分别得到ReLU′(a)·a
然后调用乘法算法得到最后的结果

Maxpool & Derivative of Maxpool
在神经网络中,池化函数(Pooling Function)一般在卷积函数的下一层。在经过卷积层提取特征之后,得到的特征图代表了 比 像素 更高级的特征,已经可以交给 分类器 进行训练分类了。但是我们 每一组卷积核 都生成 一副与原图像素相同大小的 卷积图,节点数一点没少。如果使用了 多个卷积核 还会使得通道数比之前多的多!这维度不一下子上去了嘛。所以卷积之后我们需要进行池化,也就是进行降维。最大池化操作是利用一个矩阵窗口在张量上进行扫描,将每个矩阵中的通过取最大值等来减少元素的个数
Maxpool的作用是取一组数中最大的,例如【2895877】 maxpool : 9
输入就是p0和p1的这组数的加法共享
第二步这里是个循环对于每一个xi
P0和p1首先把xi与目前的最大值maxi-1的相减,得到差值wi,然后使用前面的relu’ 判断差值w是否大于0,进而得到x与max的大小关系,用β表示,然后用secretshare对他们进行选择其中较大的一个,如果β=0,取max,否则取xi
第6和7步是为maxpool衍生算法做准备,是为了取max最大的数的索引。对于pi,Ki=i是当前位置,如果当前的数xi大于之前的max,那么取当前的索引,否则仍然保留之前的索引
第九步,输出最大值和最大值的索引的加法共享
Dmaxpool实现的是让最大值的位置为1,其他的为0
【2895877】Dmaxpool : 【0010000】
第一步,调用maxpool,得到最大值的索引
然后p0和p1把索引的共享发送给p2,并加上随机值r ,这里假设r=3
P2对共享进行重建,得到t就是索引+r 然后p2构建向量,会在索引+r的位置设置为1,也就是得到【0000010】,并把他们分成加法共享发送给p0和p1
P0和p1对他们进行循环移位 r次,得到这样的结果
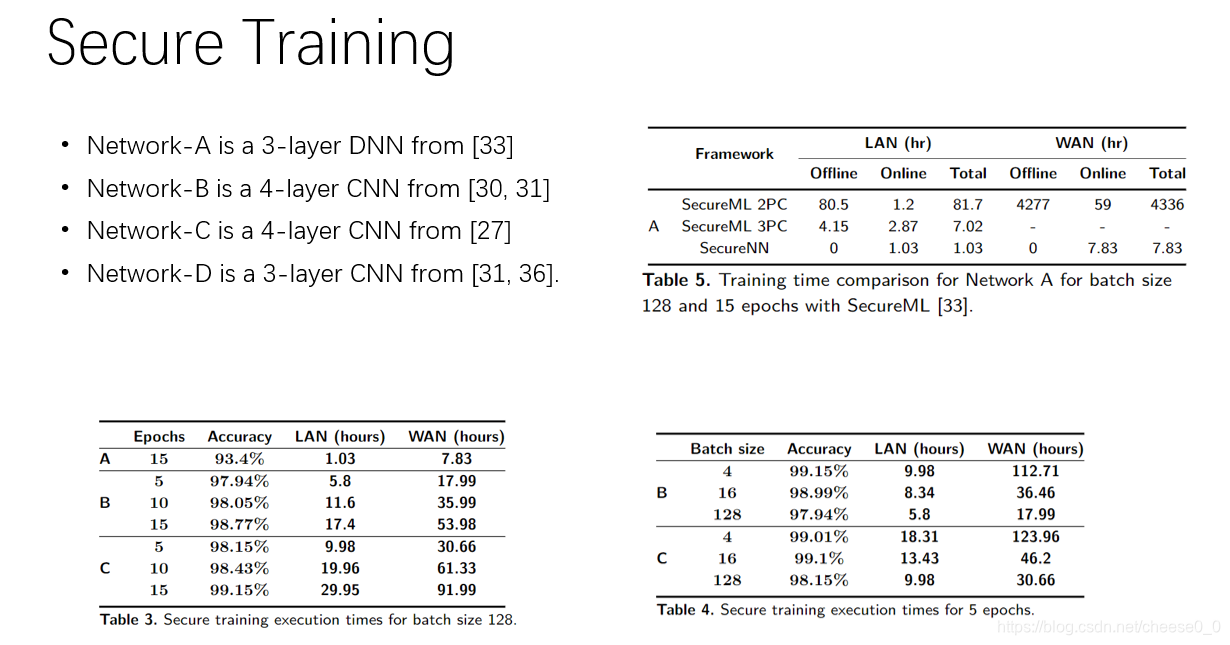
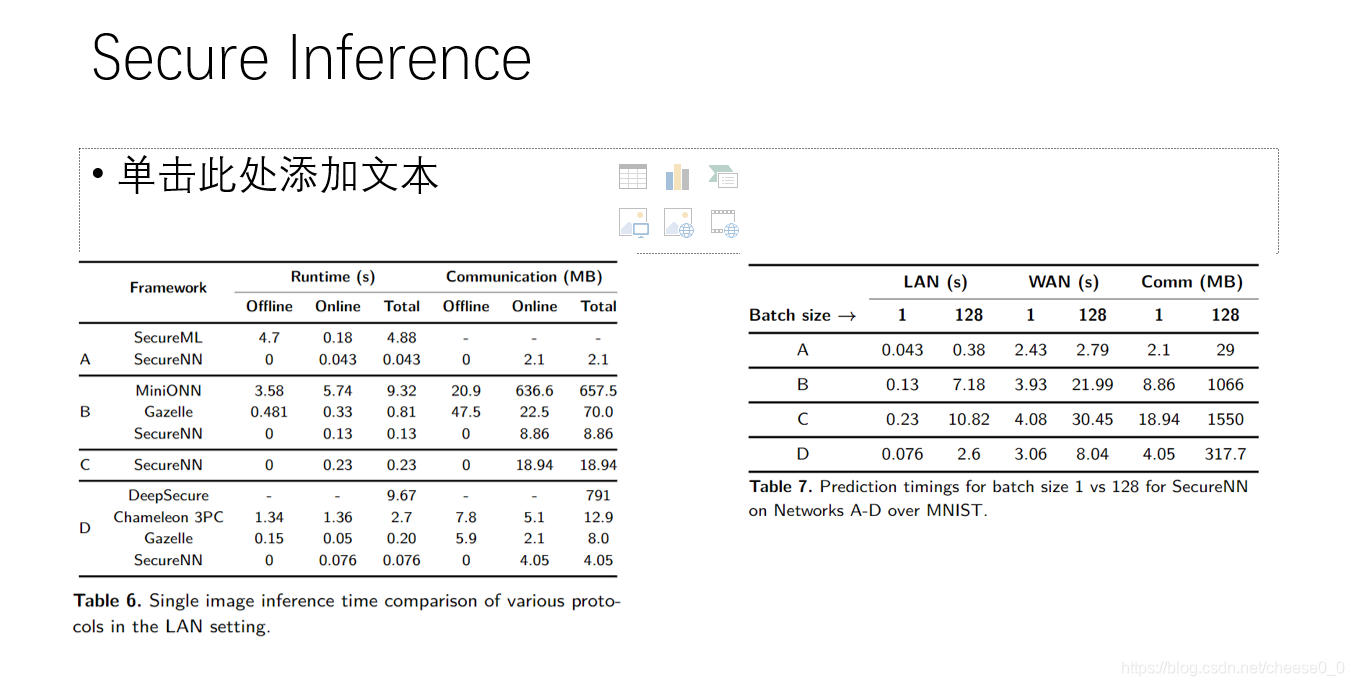
表3是在局域网/广域网设置中的结果,并将其作为培训时段数的函数(批量大小固定为128)
表4是批量大小变化且时段数固定为5时的结果。
表5
在局域网环境下,作者的协议大约比他们的三方协议快6.8倍,比他们的二方协议快79倍。在广域网环境中,更为显著,并且我们比2方协议改进了553倍。
表6可以看到和之前的工作比较
表7总结了我们在局域网和广域网设置下,在不同网络上进行1次预测和128次预测的安全推理结果。

















 630
630

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









