







准则将靠近的点集归为一类,将相互紧凑且独立的点分为一类,从而对样本点进行分类。
(2) 根据每个聚类对象的均值(中心对象),计算每个对象与这些中心对象的距离dij;并根据最小距离重新对相应对象进行划分;
(3) 重新计算每个(有变化)聚类的均值(中心对象)
(4) 循环(2)到(3)直到每个聚类J不再发生变化为止
3、涉及命令和公式
(1)两点之间的距离 命令Y=pdist(X);
Y = pdist(X,'metric')
Y = pdist(X,distfun)
Y = pdist(X,'minkowski',p)
这里:
X:为数据矩阵
metric:各种距离方法
‘euclidean’:欧几里得距离Euclidean distance (default) ‘seuclidean’:标准欧几里得距离. ‘mahalanobis’:马氏 距离 ‘cityblock’:绝对值距离 ‘minkowski’:明可夫斯基距离
(2)求点群中心
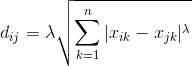
(3)类类距离计算命令
Z=linkage(Y)
Y:为pdist输出的结果,即点点的距离矩阵。
‘method’:为计算类类间距离的方法。它们有: ‘single': 最短距离法 (系统内定) ‘complete’:最长距离法。 ‘average’:平均距离法。 ‘weighted’:加权平均距离法。 ‘centroid’:中心距离法。 ‘median’:加权重心法。
(4)聚类命令cluster
T=cluster(z,'cutoff',c)
(5)做聚类图命令Z:为linkage输出的层次数据。
‘cutoff’:按某个值进行切割,值c取(0,1)之间的值。
H=dendrogram(z,p)
p为原始节点个数的设置,p=0时显示全部点,系统内定显示30点。
4、算法MATLAB实现:
(1)调用MATLAB自带K-means算法clear all;
close all;
clc;
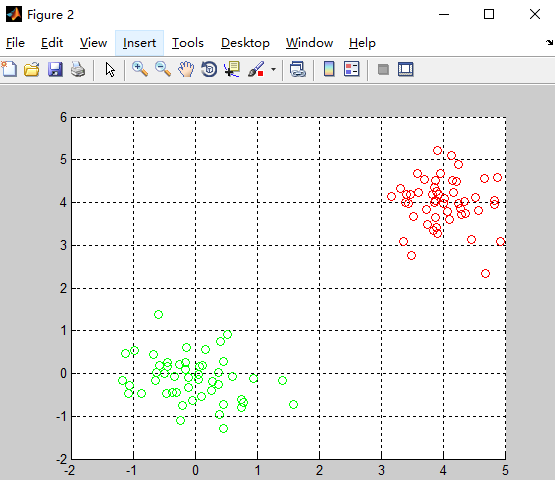
%第一类数据
mu1=[0 0 ]; %均值
S1=[0.3 0 ;0 0.3]; %协方差
data1=mvnrnd(mu1,S1,50); %产生高斯分布数据
%%第二类数据
mu2=[4 4];
S2=[0.3 0; 0 0.3];
data2=mvnrnd(mu2,S2,50);
%显示数据
plot(data1(:,1),data1(:,2),'+');
hold on;
plot(data2(:,1),data2(:,2),'+');
grid on;
%两类数据合成一个不带标号的数据类
data=[data1;data2]; %这里的data是不带标号的
%k-means聚类
[u re]=KMeans(data,2); %最后产生带标号的数据,标号在所有数据的最后,意思就是数据再加一维度
[m n]=size(re);
%最后显示聚类后的数据
figure;
hold on;
for i=1:m
if re(i,3)==1
plot(re(i,1),re(i,2),'ro');
else re(i,3)==2
plot(re(i,1),re(i,2),'go');
end
end
grid on;%N是数据一共分多少类
%data是输入的不带分类标号的数据
%u是每一类的中心
%re是返回的带分类标号的数据
function [u re]=KMeans(data,N)
[m n]=size(data); %m是数据个数,n是数据维数
ma=zeros(n); %每一维最大的数
mi=zeros(n); %每一维最小的数
u=zeros(N,n); %随机初始化,最终迭代到每一类的中心位置
for i=1:n
ma(i)=max(data(:,i)); %每一维最大的数
mi(i)=min(data(:,i)); %每一维最小的数
for j=1:N
u(j,i)=ma(i)+(mi(i)-ma(i))*rand(); %随机初始化,不过还是在每一维[min max]中初始化好些
end
end
while 1
pre_u=u; %上一次求得的中心位置
for i=1:N
tmp{i}=[];
for j=1:m
tmp{i}=[tmp{i};data(j,:)-u(i,:)];
end
end
quan=zeros(m,N);
for i=1:m %求解中心位置
c=[];
for j=1:N
c=[c norm(tmp{j}(i,:))];
end
[junk index]=min(c);
quan(i,index)=norm(tmp{index}(i,:));
end
for i=1:N %求各点到中心位置的距离平方和,如不变则算法收敛
for j=1:n
u(i,j)=sum(quan(:,i).*data(:,j))/sum(quan(:,i));
end
end
if norm(pre_u-u)<0.001 %不断迭代直到位置不再变化
break;
end
end
re=[];
for i=1:m
tmp=[];
for j=1:N
tmp=[tmp norm(data(i,:)-u(j,:))];
end
[junk index]=min(tmp);
re=[re;data(i,:) index];
end
end5、实验结果

①.算法流程
输入:聚类个数k,以及 n个数据。
输出:满足方差最小标准的k个聚类。
(1)从n个数据对象任意选择k个对象作为初始聚类中心
(2)计算每个对象与聚类中心的距离;并根据最小距离重新对相应对象进行划分
(3)重新计算每个聚类的均值作为新的聚类中心
(4)循环(2)到(3)直到每个聚类不再发生变化为止
②. 算法分析
K-Means的优化目标可以表示为:
整个算法通过迭代计算,找到合适的r_nk和μ_k来,使得J最小。
算法流程的第二步,固定μ_k,更新r_nk,将每个数据对象放到与其最近的聚类中心的类别中,自然这一步能够保证在固定μ_k的情况下,J的值降到了最小。
算法流程的第三步,固定r_nk,更新μ_k,此时J对μ_k(实际上是μ_0,μ_1,...分别求导)求导并令结果等于零,得到:
两个步骤,J的值都在下降,随着迭代次数增加J的值会下降到一个极小值。
③. 结束条件
· 每个聚类内部元素不在变化,这是最理想的情况了。
· 前后两次迭代,J的值相差小于某个阈值。
· 迭代超过一定的次数
改进方法:1.算法复杂度高O(nkt)2.不能发现非凸形状的簇,或大小差别很大的簇3.需样本存在均值(限定数据种类)4. 必须首先给出k(要生成的簇的数目),k值很难选择。事先并不知道给定的数据应该被分成什么类别才是最优的。5.对噪声和离群点敏感6.最重要是结果不一定是全局最优,只能保证局部最优。















 7013
7013











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









