










文章目录
论文: TalkingFlow: Talking facial landmark generation with multi-scale normalizing flow network
原文地址: TalkingFlow. 本文是在阅读原文时的简要总结和记录。

Abstract
1. 说话面部标志生成(talking facial landmarks generation)领域的两种模型
- 确定性模型:目前占主导地位;它以一种有监督的方式将语音信号直接映射到特定的唇形同步的面部标志序列,是一类回归问题。但它可能导致回归到“均值脸”的问题。
- 概率生成模型:更有利于处理复杂的数据空间和生成多样化的样本。
2. 本文工作:提出了基于流的概率网络TalkingFlow,以从语音数据中生成自然的、带有头部运动的说话面部标志。
通过以下两部分实现:
- 加权多尺度架构:提高模型表示能力
- 条件时间卷积网络(Conditional Temporal Convolutional Network, ConditionTCN):融合语音数据。
3. 实验结果表明TalkingFlow可以有效地从语音数据中生成多样化和自然的面部标志
Introduction
1. 什么是说话面部标志生成(talking facial landmarks generation)
说话面部标志生成任务旨在从语音信号中合成面部标志。面部标志是一种高级面部表示,包括语音相关信息(例如嘴唇运动和表情)和与语音无关的信息(例如身份和头部姿势)。
2. 先前的说话面部标志生成工作
大多数工作都基于确定性模型,即从一个语音片段中预测特定的面部标志序列。
- Eskimez等人:提出了一个多层LSTM网络用来从语音中生成面部标志,并在数据预处理时事先将面部标志与固定的头部姿势和眼部坐标对齐。
- Chen等人:提出了ATNet,将语音数据转换到用PCA成分表示的面部标志序列上,并进一步添加了一个额外的头部姿势learner
- Ji等人:将上述工作拓展到一个EVP模型,利用语音的内容编码和情感编码生成面部标志序列
上述方法不能捕捉到自然的具有头部运动的面部标志。
3. 序列生成的三种概率生成模型
确定性模型存在一些问题和局限。概率生成模型可以更好地建模整个空间。用于序列生成的概率生成模型通常有3种:
- GAN:对数据流形建模很有效,但经常遭受模式崩溃并且无法正确泛化
- VAE:通常使用自回归框架对序列数据进行建模,但仍会受到后向崩溃的影响
- Normalizing Flows(NF):由一串反函数组成,直接最大化数据似然性,避免了上述缺点,便于训练 。
4. 本文的主要工作
TalkingFlow:将基于流的生成模型扩展到说话面部标志生成的任务中,这是第一个用于说话面部标志生成任务的概率流模型。
- 采用加权多尺度架构设计,对不同尺度数据分布的方差进行建模,其中每个尺度的网络包括多个归一化流步骤
- 在每个流步骤中引入条件时间卷积网络(ConditionTCN)模块,以逐次融合语音信号和隐变量,提高模型的表示能力。
TalkingFlow
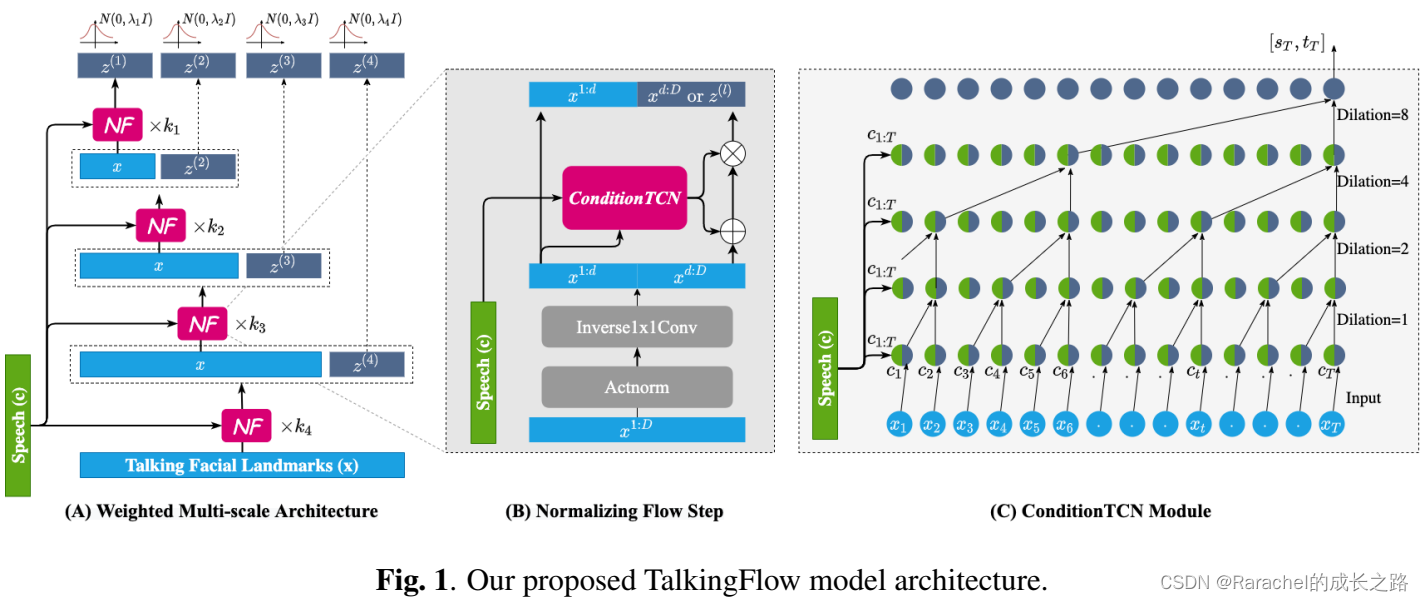
TalkingFlow的模型模型结构如上图1所示。模型的主体由包含一系列归一化流(NF)步骤的加权多尺度架构构成;其中每个NF都采用Glow网络;此外在每个Glow网络中都集成了一个ConditionTCN模块,用于融合语音信号和隐变量。通过结合Glow和ConditionTCN,在模型中建立了将多尺度高斯噪声映射到想要的说话面部标志的分层双射(bijection),这使得模型能够从语音数据中生成自然的具有头部运动的唇形同步的说话面部标志。
考虑给定语音序列
c
=
{
c
1
,
c
2
,
…
,
c
T
}
c=\{c_1,c_2,\dots,c_T\}
c={c1,c2,…,cT},其对应的面部标志序列为
x
=
{
x
1
,
x
2
,
…
,
x
T
}
x=\{x_1,x_2,\dots,x_T\}
x={x1,x2,…,xT},
t
t
t时刻的面部标志
x
t
x_t
xt与
t
t
t时刻前的面部标志
x
<
t
x_{<t}
x<t及t时刻及之前的语音信号
c
≤
t
c_{\leq t}
c≤t有关,因此从
c
c
c生成
x
x
x的概率可以表示为
p
(
x
∣
c
)
=
∏
t
=
1
T
p
(
x
t
∣
x
<
t
,
c
≤
t
)
p(x|c)=\prod_{t=1}^Tp(x_t|x_{<t},c_{\leq t})
p(x∣c)=∏t=1Tp(xt∣x<t,c≤t)。
1.利用归一化流(NF)对 p ( x ∣ c ) p(x|c) p(x∣c)进行建模
NF可以将一个未知的复杂分布映射到一个简单的分布。首先假设存在一个双向映射
ϕ
:
R
d
→
R
d
\phi:R^d \rightarrow R^d
ϕ:Rd→Rd,它可以从随机变量
z
∼
p
(
z
)
z\sim p(z)
z∼p(z)中生成
x
=
ϕ
(
z
,
c
)
x=\phi(z,c)
x=ϕ(z,c);它的逆映射可以恢复
z
=
ϕ
−
1
(
x
,
c
)
z=\phi^{-1}(x,c)
z=ϕ−1(x,c)。因此,在此假设下有
x
t
∣
x
<
t
,
c
≤
t
=
ϕ
(
z
t
,
c
≤
t
)
x_t|_{x<t,c\leq t}=\phi(z_t,c_{\leq t})
xt∣x<t,c≤t=ϕ(zt,c≤t),从而当
p
(
z
t
)
p(z_t)
p(zt)与语音信号独立的条件时有:
p
(
x
t
∣
x
<
t
,
c
≤
t
)
=
p
(
z
t
)
∣
d
e
t
∂
ϕ
∂
z
t
∣
−
1
p(x_t|x_{<t},c_{\leq t})=p(z_t)|det\frac{\partial\phi}{\partial z_t}|^{-1}
p(xt∣x<t,c≤t)=p(zt)∣det∂zt∂ϕ∣−1。
在实际中
ϕ
\phi
ϕ由K步可逆变换复合而成,因此
x
,
z
x,z
x,z之间的关系可以被表示为
x
t
=
ϕ
K
(
ϕ
K
−
1
(
…
ϕ
1
(
z
t
,
0
,
c
≤
t
)
)
)
x_t=\phi_K(\phi_{K-1}(\dots\phi_1(z_{t,0},c_{\leq t})))
xt=ϕK(ϕK−1(…ϕ1(zt,0,c≤t)))
z
t
,
0
=
ϕ
1
−
1
(
ϕ
2
−
1
(
…
ϕ
K
−
1
(
x
<
t
,
c
≤
t
)
)
)
z_{t,0}=\phi^{-1}_1(\phi_2^{-1}(\dots\phi_K^{-1}(x_{<t}, c_{\leq t})))
zt,0=ϕ1−1(ϕ2−1(…ϕK−1(x<t,c≤t)))
其中
z
t
,
0
z_{t,0}
zt,0表示第0步时刻t的隐变量,定义
z
k
=
ϕ
k
(
z
k
−
1
,
c
)
z_k=\phi_k(z_{k-1},c)
zk=ϕk(zk−1,c),则
z
t
,
0
=
z
t
,
z
t
,
K
=
x
t
z_{t,0}=z_t, z_{t,K}=x_t
zt,0=zt,zt,K=xt。由此
p
(
x
t
∣
x
<
t
,
c
≤
t
)
p(x_t|x_{<t,c_{\leq t}})
p(xt∣x<t,c≤t)可以重新表示为
log
p
(
x
t
∣
x
<
t
,
c
≤
t
)
=
log
p
(
z
t
,
0
)
−
∑
k
=
1
K
∣
log
det
∂
ϕ
k
∂
z
t
,
k
−
1
∣
\log p(x_t|x_{<t},c_{\leq t})=\log p(z_{t,0})-\sum_{k=1}^K|\log \det\frac{\partial \phi_k}{\partial z_{t,k-1}}|
logp(xt∣x<t,c≤t)=logp(zt,0)−k=1∑K∣logdet∂zt,k−1∂ϕk∣
2. 加权多尺度架构:用于实现 ϕ \phi ϕ
如上图(A)所示,隐变量
z
=
c
a
t
[
z
(
1
)
,
z
(
2
)
,
…
,
z
(
L
)
]
z=cat[z^{(1)},z^{(2)},\dots,z^{(L)}]
z=cat[z(1),z(2),…,z(L)]由不同尺度的变量
z
(
l
)
z^{(l)}
z(l)堆叠而来,每个尺度
l
l
l的变量
z
(
l
)
z^{(l)}
z(l)通过
k
l
k_l
kl步的NF网络生成;
z
(
l
)
z^{(l)}
z(l)在给定语音条件的情况下编码了说话人脸标志的一部分分布,这是从每个尺度网络最后的仿射耦合层获得的。由此
z
(
l
)
z^{(l)}
z(l)的概率可以写作
p
(
z
(
l
)
∣
c
)
=
∏
t
=
1
T
p
(
z
t
(
l
)
∣
z
<
t
(
<
l
)
,
c
≤
t
)
p(z^{(l)}|c)=\prod_{t=1}^Tp(z_t^{(l)}|z_{<t}^{(<l)},c_{\leq t})
p(z(l)∣c)=∏t=1Tp(zt(l)∣z<t(<l),c≤t)。与WaveGlow和VideoGlow不同之处在于,本方法为每个尺度的分布引入了加权方差
p
(
z
(
l
)
)
∼
N
(
0
,
λ
l
I
)
p(z^{(l)})\sim N(0,\lambda_lI)
p(z(l))∼N(0,λlI),以提高其表示能力,其中
λ
l
\lambda_l
λl是尺度
l
l
l的隐变量
z
(
l
)
z^{(l)}
z(l)分布的方差。
在每一个NF步骤中,都采用了如图(B)所示的Glow模型,以使用条件神经网络
C
o
n
d
i
t
i
o
n
N
e
t
ConditionNet
ConditionNet将条件语音信号合并到仿射耦合层中(即图中的ConditionTCN)。 在仿射耦合层中,D维输入
z
t
,
k
(
l
)
z_{t,k}^{(l)}
zt,k(l)被分为两部分
z
t
,
k
1
:
d
z_{t,k}^{1:d}
zt,k1:d和
z
t
,
k
d
:
D
z_{t,k}^{d:D}
zt,kd:D,其中
d
=
D
2
d=\frac{D}{2}
d=2D,
z
t
,
k
+
1
(
l
)
z_{t,k+1}^{(l)}
zt,k+1(l)按照如下步骤更新:
[
z
t
,
k
1
:
d
,
z
t
,
k
d
:
D
]
=
s
p
l
i
t
(
z
t
,
k
(
l
)
)
[z_{t,k}^{1:d}, z_{t,k}^{d:D}]=split(z_{t,k}^{(l)})
[zt,k1:d,zt,kd:D]=split(zt,k(l))
[
s
t
,
k
,
t
t
,
k
]
=
C
o
n
d
i
t
i
o
n
N
e
t
(
z
t
,
k
1
:
d
,
c
t
)
[s_{t,k},t_{t,k}]=ConditionNet(z_{t,k}^{1:d}, c_t)
[st,k,tt,k]=ConditionNet(zt,k1:d,ct)
z
t
,
k
+
1
(
l
)
=
[
z
t
,
k
1
:
d
,
exp
(
s
t
,
k
)
⊙
z
t
,
k
d
:
D
+
t
t
,
k
]
z_{t,k+1}^{(l)}=[z_{t,k}^{1:d}, \exp(s_t,k)\odot z_{t,k}^{d:D}+t_{t,k}]
zt,k+1(l)=[zt,k1:d,exp(st,k)⊙zt,kd:D+tt,k]
其中
⊙
\odot
⊙为哈达玛积,
C
o
n
d
i
t
i
o
n
N
e
t
ConditionNet
ConditionNet是将语音数据融合到主干的条件神经网络。在尺度
l
l
l的最后一个仿射耦合层中,
z
t
,
k
+
1
(
l
)
z_{t,k+1}^{(l)}
zt,k+1(l)将被划分为2部分:一个更高尺度的变量
z
t
,
k
+
1
(
l
+
1
)
z_{t,k+1}^{(l+1)}
zt,k+1(l+1)作为下一个 Glow 步骤的输入,和一个新的高级变量
z
t
(
l
+
1
)
z_{t}^{(l+1)}
zt(l+1)用于建模加权方差分布, 可以表述为
[
z
t
,
k
+
1
(
l
+
1
)
,
z
t
(
l
+
1
)
]
=
[
z
t
,
k
1
:
d
,
exp
(
s
t
,
k
)
⊙
z
t
,
k
d
:
D
+
t
t
,
k
]
[z_{t,k+1}^{(l+1)}, z_{t}^{(l+1)}]=[z_{t,k}^{1:d}, \exp(s_t,k)\odot z_{t,k}^{d:D}+t_{t,k}]
[zt,k+1(l+1),zt(l+1)]=[zt,k1:d,exp(st,k)⊙zt,kd:D+tt,k]
3. ConditionTCN模块
Glow模型中仿射耦合层的数学性质 log det ( ∂ ϕ k ∂ z k ) = s u m ( log ( ∣ s ∣ ) ) \log \det(\frac{\partial\phi_k}{\partial z_k})=sum(\log(|s|)) logdet(∂zk∂ϕk)=sum(log(∣s∣))使得 C o n d i t i o n N e t ConditionNet ConditionNet不必是可逆的,这意味着它可以是任何神经网络。在本方法中,通过条件时间卷积网络(ConditonTCN)作为 C o n d i t i o n N e t ConditionNet ConditionNet来融合条件语音数据和潜在变量,如上图(C)所示。 该模块沿时间轴堆叠四个1-D膨胀卷积层,分别具有1、2、4 和8的膨胀因子,并集成因果卷积以确保输出 h t h_t ht独立于任何未来的面部标志和语音信息。在每一层中,通过类似于PixelCNN和WaveGlow的门控激活单元将隐变量与条件语音数据时间步长合并。
4. 损失函数
本方法的损失函数设计为 min − log p ( x ∣ c ) = − 1 L × T ∑ t = 1 T [ ∑ l = 1 L log p ( z t ( l ) ) + ∑ k = 1 K ∑ l = 1 L ∣ log det ∂ ϕ k ( l ) ∂ z t , k − 1 ( l ) ∣ ] \min -\log p(x|c)=-\frac{1}{L\times T}\sum_{t=1}^T[\sum_{l=1}^L\log p(z_t^{(l)})+\sum_{k=1}^K\sum_{l=1}^L|\log \det \frac{\partial \phi_k^{(l)}}{\partial z_{t,k-1}^{(l)}}|] min−logp(x∣c)=−L×T1t=1∑T[l=1∑Llogp(zt(l))+k=1∑Kl=1∑L∣logdet∂zt,k−1(l)∂ϕk(l)∣],其中 p ( z t ( l ) ) ∼ N ( 0 , λ l I ) p(z_t^{(l)})\sim N(0,\lambda_lI) p(zt(l))∼N(0,λlI)是每个尺度 l l l输出的分布。
Experiments
本模型是在Obama数据集(17h)上训练,并在Obama数据集和GRID数据集上评估。在数据预处理阶段,首先提取每个视频帧的2D面部标志,然后将数值归一化为0∼1以进行稳定的训练。同时,从每个视频中分离出同步的音频信号,并提取其梅尔谱特征作为条件语音数据。通过hype-parameters grid search实验,将多尺度架构的尺度数量 L L L设置为4,四个尺度的权重 λ 1 ∼ λ 4 \lambda_1 \sim \lambda_4 λ1∼λ4分别设置为0.25、0.5、0.75和1.0。
1. 定量结果
- Baseline
- 评价指标
- MOS:评估唇音同步性和生成动作的质量
- SyncNet Score,由SyncNet模型修改而来,通过计算唇部面部标志嵌入与其相应语音信号嵌入的相似性来衡量面部唇-音频同步性的指标
- 张嘴率距离( L M O R L_{MOR} LMOR),即每帧推断的张嘴率与真实值之间的距离
- 结果
- Obama数据集上的比较结果下表1所示,这表明本方法在所有三个指标上都取得了最佳性能
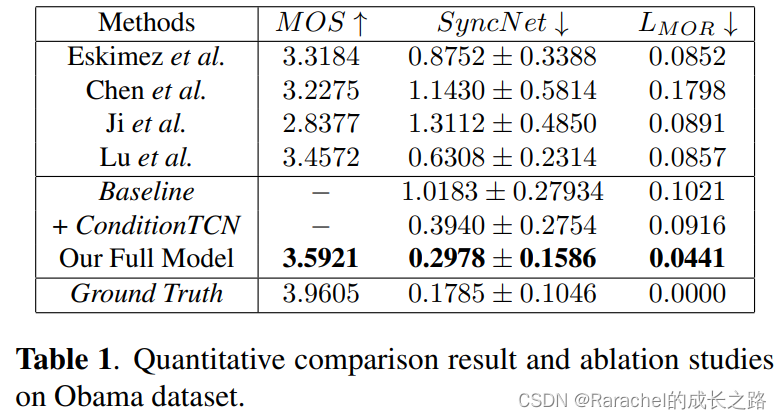
- 在GRID数据集上的比较结果如下表2所示。在
L
M
O
R
L_{MOR}
LMOR上较差的原因可能可能是其他Baseline在GRID数据集上进行训练,但本方法在Obama数据集上进行训练。这实际上反映了本方法良好的泛化能力。
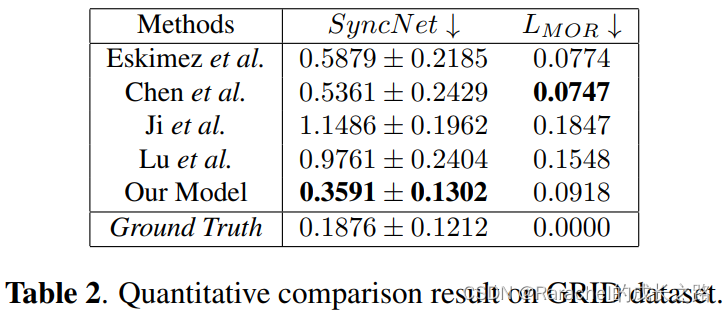
- Obama数据集上的比较结果下表1所示,这表明本方法在所有三个指标上都取得了最佳性能
2. 定性结果
定性结果如下图所示,这表明本方法能够生成具有更好的唇同步性和自然头部运动的高质量说话面部标志。很明显,本方法的唇形最接近基本事实。 具体来说,只有本方法可以反映t=43处所示的噘嘴动作。

3. 消融实验
进行了定量消融研究以探索加权多尺度架构和ConditionTCN模块的意义,结果如上表1所示。Baseline模型没有多尺度架构和ConditionTCN模块,+ConditionTCN只包括ConditionTCN模块。结果表明,即使是Baseline也已经获得了比某些Baseline更好的性能。这证明了归一化流NF在此任务上的有效性。此外,+ConditionTCN显着降低了SyncNet分数,这表明ConditionTCN在模型中起着更重要的作用。
Discussion
从语音信号中生成说话面部标志是talking-head研究领域的核心问题。现有的方法将其作为一个有监督的回归问题来解决,但经常遭受回归到平均人脸的问题,并且无法正确处理与语音无关的信息。本文是第一个使用基于流方法的概率生成模型来解决此问题的,它在训练阶段比GAN和VAE更具优势。
多尺度架构是最近基于流方法的常见做法,例如Real-NVP、WaveGlow和VideoFlow。Real-NVP让一半的变量使用挤压操作直接建模为高斯;WaveGlow使用早期输出运算符实现多尺度架构,以提前输出一些维度以在多个时间尺度上添加信息;VideoFlow为每个尺度的变量添加了一个潜在的先验。这些作品将每个尺度的变量建模为正态分布。因此,本方法为每个尺度增加了权重,以增加模型的表示能力。尽管此操作带来了额外的超参数,但可以在未来的工作中通过自适应多尺度加权对其进行优化。














 2095
2095











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









