









文章目录
论文:VCVTS: Multi-speaker video-to-speech synthesis via cross-modal knowledge transfer from voice conversion
原文地址:VCVTS。本文是在阅读原文时的简要总结和记录。

Abstract
1.什么是Multi-speaker VTS(video-to-speech)
在同一个系统内,将静默视频(silent video)映射为语音的同时,允许灵活控制说话人的身份。
2.本文提出的系统VCVTS: 基于从VC(Voice Conversion)迁移来的跨模态知识
- VC的内容编码器:VQCPC(vector quantization with contrastive predictive coding),用于产生离散的类似于音素的声学单元
- Lip2Ind:推断声学单元的index序列,从VC的内容编码器迁移而来
- 用Lip2Ind代替VC的内容编码器,构成一个VTS系统:将静默视频转换为声学单元,用以重构准确的语音内容
- VTS系统继承了VC系统的优点——话者编码器:生成话者表示用以控制生成语音的说话人身份
3. 本文提出的系统在受限词汇和开放词汇的条件下都可以达到SOTA水平
demo: https://wendison.github.io/VCVTS-demo/
Introduction
1.什么是VTS(video-to-speech)
- 根据两个模态之间的对应关系从静默视频中重构语音信号
- 应用场景很多:帮助无法发声的病人交流、恢复视频会议受损或丢失的语音信号
- 先前的VTS工作
1. 统计模型:将视觉特征映射为声学特征 (HMM/非负矩阵分解/极大似然估计/深度学习等)
2. 声码器:生成波形
3. 大多基于小数据集, 单一说话人,受限词汇(GRID数据集) - 先前的Multi-speaker VTS系统:使用话者表示捕捉说话人特征从而控制说话人身份
1. Lip2Wav:使用预训练的语音识别任务最优的说话人编码器提取说话人表示
2. XTS:使用对抗学习解耦说话人信息
这些方法直接将唇形映射到语音,将深度学习方法视作一个黑箱,对于模型所学习到的中间表示的可解释性不强;而且对比其他语音生成任务(TTS/VC),这些方法生成语音的自然度不高。
2.本文的VCVTS(Voice Conversion-based Video-To-Speech)系统
- 首先训练一个包含四部分的VC系统
1. 内容编码器:VQCPC,用以产生离散的类似于音素的声学单元
2. 话者编码器:提取有效的话者表示用以控制话者身份
3. 基音(pitch)预测器:预测基频 F 0 F_0 F0来控制pitch contour
4. 解码器:将声学单元、话者表示和 F 0 F_0 F0映射到梅尔谱 - 训练一个Lip2Ind网络
1. 用来从视频预测声学单元的index序列,index对应于从VQ码本中获得的声学单元
2. 离散的类似音素的声学单元被视为知识,从语音跨模态迁移到图像 - 多说话人VTS系统——VCVTS
1. 将Lip2Ind与VQ码本、话者编码器、pitch预测器和VC解码器连接起来
2. 视频到语音的映射关系的可解释性更强、继承了VC的优点(控制话者身份和pitch contour)
3.本文的主要贡献
- 在VC框架下使用VQCPC预测离散的类似于音素的声学单元
- 通过跨模态知识迁移构建Lip2Ind网络,将唇部视频映射到声学单元,以重建语言内容
- 开发一种新的多说话人VTS系统VCVTS,该系统可以处理开放词汇和复杂的图像场景(LRW数据集)
Proposed Approach
1. 数据说明
- K个视频,每个视频包含两个数据流(语音和图像)
- 语音流
1. 帧率:100fps,即帧移为10ms
2. 表示为 X k = { x k , 1 , x k , 2 , … , x k , T } X_k=\{x_{k,1},x_{k,2}, \dots, x_{k,T}\} Xk={xk,1,xk,2,…,xk,T} - 图像流
1. 帧率:25fps
2. 表示为 Y k = { y k , 1 , y k , 2 , … , y k , T / 4 } Y_k=\{y_{k,1},y_{k,2}, \dots, y_{k,T/4}\} Yk={yk,1,yk,2,…,yk,T/4},长度为 T 4 \frac{T}{4} 4T
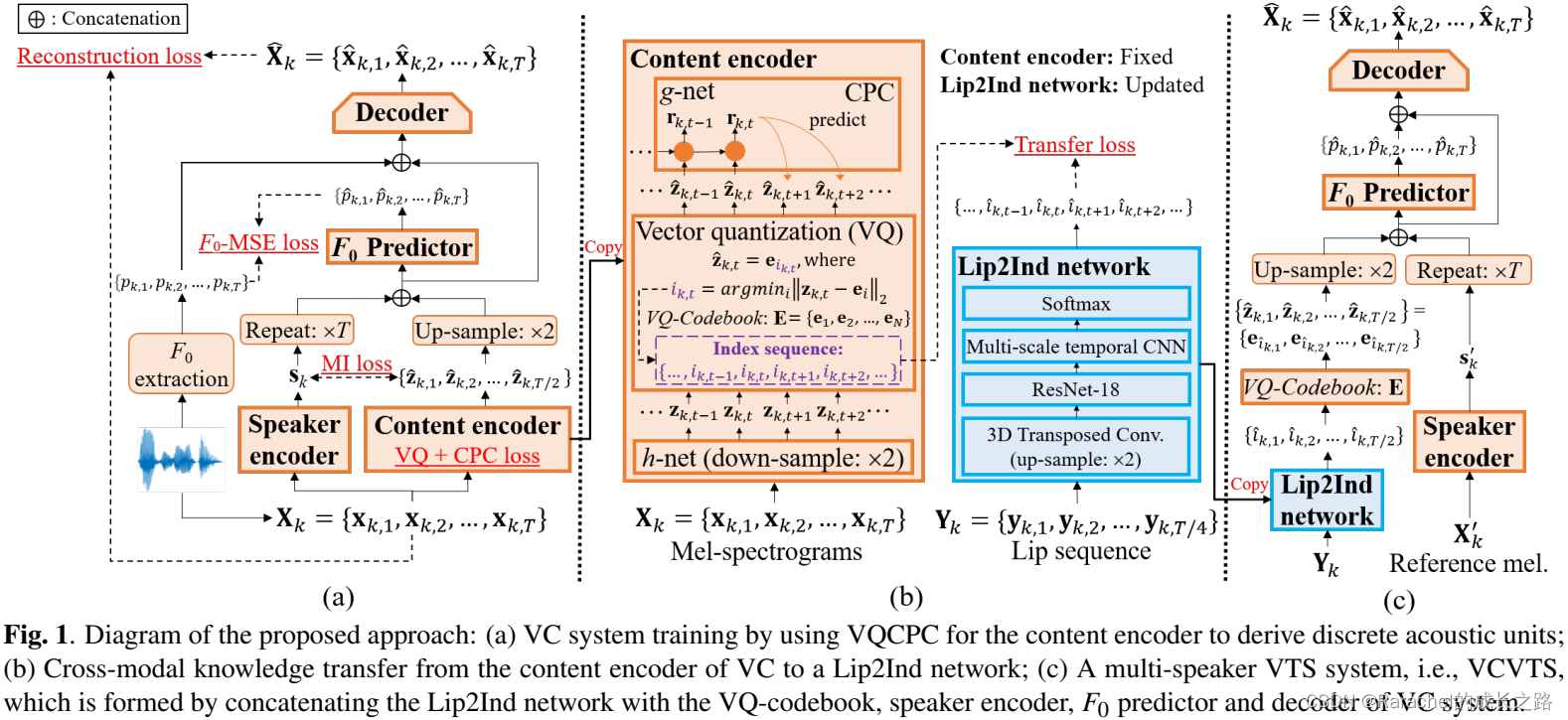
2. VC系统的训练
- 主要结构从VQMIVC系统修改而来, 如下图所示,新加入了pitch predictor:推断难以从视觉特征中预测的
F
0
F_0
F0值
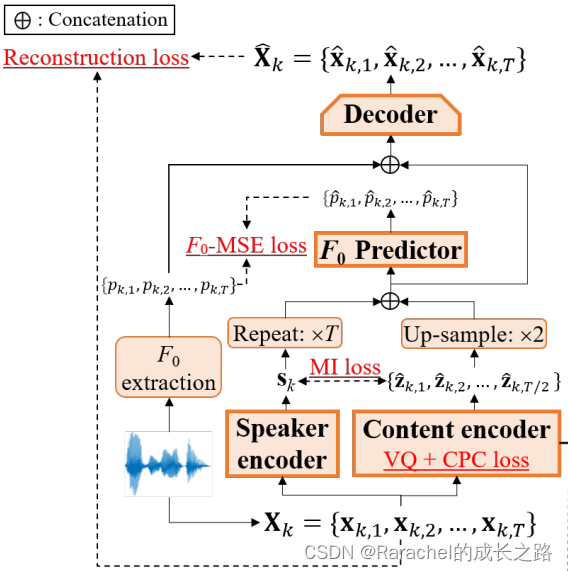
- VQCPC: 编码内容,如下图所示

1. h-net:将 X k = { x k , 1 , x k , 2 , … , x k , T } X_k=\{x_{k,1},x_{k,2}, \dots, x_{k,T}\} Xk={xk,1,xk,2,…,xk,T}映射到 Z k = { z k , 1 , z k , 2 , … , z k , T / 2 } Z_k=\{z_{k,1},z_{k,2},\dots,z_{k,T/2}\} Zk={zk,1,zk,2,…,zk,T/2},同时下采样2倍
2. 对 Z k Z_k Zk进行矢量量化获得 Z ^ k \hat{Z}_k Z^k,具体做法是:
(1).VQ的码本记作 E = { e 1 , e 2 , … , e N } E=\{e_1,e_2,\dots,e_N\} E={e1,e2,…,eN};
(2). i k t = arg min i ∥ z k , t − e i ∥ 2 , z ^ k , t = e i k , t i_{kt}=\mathop{\arg\min}_{i} \| z_{k,t}-e_i\|_2, \hat{z}_{k,t}=e_{i_{k,t}} ikt=argmini∥zk,t−ei∥2,z^k,t=eik,t;
(3). 码本 E E E的训练使用VQ Loss: L V Q = 2 K T ∑ k = 1 K ∑ t = 1 T 2 ∥ z k , t − z ^ k , t ∥ 2 2 L_{VQ}=\frac{2}{KT}\sum^{K}_{k=1}\sum^{\frac{T}{2}}_{t=1}\|z_{k,t}-\hat{z}_{k,t}\|^2_2 LVQ=KT2k=1∑Kt=1∑2T∥zk,t−z^k,t∥22其中 s g ( ) sg() sg()表示stop-gradient operator;
3. g-net: 从 Z ^ k \hat{Z}_k Z^k中获得 R k = r k , 1 , r k , 2 , … , r k , T / 2 R_k={r_{k,1},r_{k,2},\dots,r_{k,T/2}} Rk=rk,1,rk,2,…,rk,T/2, 训练目标是通过最小化CPC Loss区分正负样本
L C P C = − 1 K T ′ M ∑ k = 1 K ∑ t = 1 T ∑ m = 1 M log [ exp z ^ k , t + m T W m r k , t ∑ z ~ ∈ Ω k , t , m exp z ~ T W m r k , t ] L_{CPC}=-\frac{1}{KT'M}\sum_{k=1}^K\sum_{t=1}^T\sum_{m=1}^M\log{[\frac{\exp{\hat{z}_{k,t+m}^TW_{m}r_{k,t}}}{\sum_{\tilde{z}\in\Omega_{k,t,m}}\exp{\tilde{z}^TW_mr_{k,t}}}]} LCPC=−KT′M1k=1∑Kt=1∑Tm=1∑Mlog[∑z~∈Ωk,t,mexpz~TWmrk,texpz^k,t+mTWmrk,t]
其中 T ′ = T 2 − M T'=\frac{T}{2}-M T′=2T−M, W m ( m = 1 , 2 , … , M ) W_m(m=1,2,\dots,M) Wm(m=1,2,…,M)是一个可以训练的投影矩阵, z ^ k , t + m \hat{z}_{k,t+m} z^k,t+m是 m m m个时刻后的正样本, Ω k , t , m \Omega_{k,t,m} Ωk,t,m是负样本集. CPC损失会使得离散声学单元 Z ^ k \hat{Z}_k Z^k捕捉’slow features, 例如音素.
3. 为了将 Z ^ k \hat{Z}_k Z^k和话者表示 s k s_k sk分离开, 训练期间还会最小化二者之间的互信息 L M I L_{MI} LMI
VC系统总的训练损失是: L V C = L V Q + L C P C + L M I + L F 0 − M S E + L m e l L_{VC}=L_{VQ}+L_{CPC}+L_{MI}+L_{F_0-MSE}+L_{mel} LVC=LVQ+LCPC+LMI+LF0−MSE+Lmel
3.跨模态知识迁移
- 梅尔谱图和声学单元的可视化
- 从GRID数据集中选择四个话者读"red"一词, 对应音素序列为"R EH1 D", 其梅尔谱和由内容编码器获得的声学单元索引序列的可视化如下图所示, 其中声学单元索引序列由
i
k
t
=
arg
min
i
∥
z
k
,
t
−
e
i
∥
2
i_{kt}=\mathop{\arg\min}_{i} \| z_{k,t}-e_i\|_2
ikt=argmini∥zk,t−ei∥2获得; 在同一音素内的四个索引序列中至少出现两次的公共索引标记为橙色.
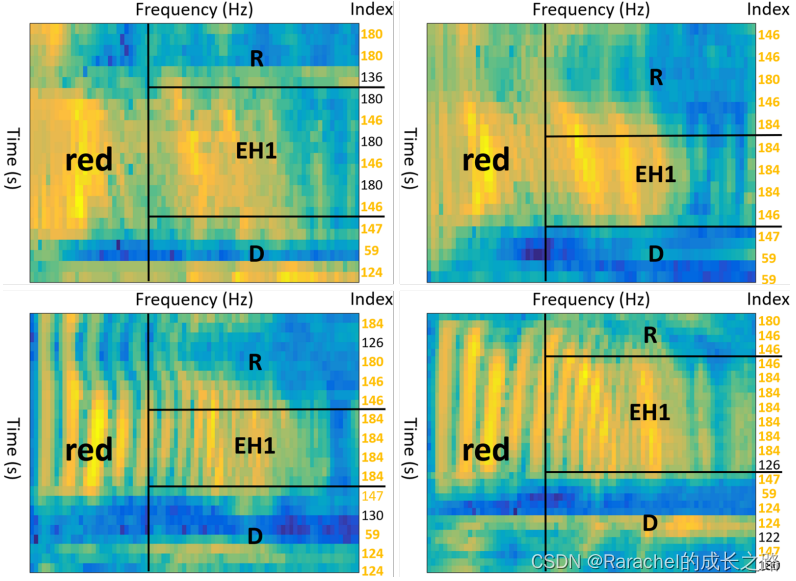
- 可以观察到相同的索引倾向于出现在相同的音素中,不同的索引倾向于出现在不同的音素中,这表明索引序列与底层语言内容(例如音素)密切相关
知识,即索引,可以转移到VTS任务中,从而可以从嘴唇特征中适当地推断出准确的口语内容。
- 从GRID数据集中选择四个话者读"red"一词, 对应音素序列为"R EH1 D", 其梅尔谱和由内容编码器获得的声学单元索引序列的可视化如下图所示, 其中声学单元索引序列由
i
k
t
=
arg
min
i
∥
z
k
,
t
−
e
i
∥
2
i_{kt}=\mathop{\arg\min}_{i} \| z_{k,t}-e_i\|_2
ikt=argmini∥zk,t−ei∥2获得; 在同一音素内的四个索引序列中至少出现两次的公共索引标记为橙色.
- Lip2Ind网络: 从唇形视频中推断声学单元的索引序列; 对于包含N个码字的VQ码本E, 这是一个 N 路分类问题, 如下图所示

- 给定梅尔谱 X k X_k Xk和唇形视频 Y k Y_k Yk,内容编码器输入 X k X_k Xk, 输出索引序列 { i k , 1 , i k , 2 , … , i k , T / 2 } \{i_{k,1}, i_{k,2}, \dots, i_{k,T/2}\} {ik,1,ik,2,…,ik,T/2}
- Lip2Ind网络输入 Y k Y_k Yk, 学习目标为索引序列 { i k , 1 , i k , 2 , … , i k , T / 2 } \{i_{k,1}, i_{k,2}, \dots, i_{k,T/2}\} {ik,1,ik,2,…,ik,T/2}
- 最小化以下知识迁移损失(即交叉熵), 其中
q
i
k
,
t
q_{i_{k,t}}
qik,tLip2Ind网络在时刻t的输出,表示索引
i
k
,
t
i_{k,t}
ik,t的后验概率。
L T r a n s = − 2 K T ∑ k = 1 K ∑ t = 1 T / 2 log q i k , t L_{Trans}=-\frac{2}{KT}\sum_{k=1}^K\sum_{t=1}^{T/2}\log{q_{i_{k,t}}} LTrans=−KT2k=1∑Kt=1∑T/2logqik,t
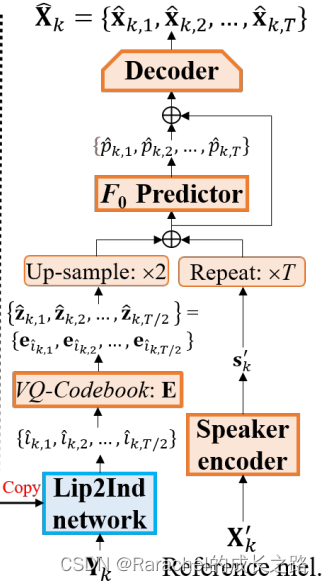
4. 多说话人 VTS系统
- 如下图所示, 其中带有VQ码本的训练好的Lip2Ind网络可以为语音内容重建产生准确的声学单元,因此它可以与 VC 的话者编码器、pitch预测器和解码器连接形成多扬声器VTS系统,其中话者身份由话者编码器根据参考语音生成的话者表示
s
k
′
s_k'
sk′控制。
Experiment
1. 数据集
- GRID: 33个说话人, 每人1K个视频, 52个词汇
- 测试集包含说话人s1, s2, s4, s29
- 训练集包含两种情况: 全部的33个说话人/除测试集外的29个说话人, 以此分别测试VTS系统对集内和集外说话人的性能
- 每个说话人的视频按8:1:1的比例分到train/dev/test
- LRW: 百余个说话人, 词汇量超过500
- 按照默认划分数据集, 均为集外说话人
- 声学特征
- 80维梅尔谱, 400点FFT, 帧移为10ms
- 基频 F 0 F_0 F0的参数设置同上
- 图像特征
- 使用Dlib工具获得面部landmarks
- 根据landmarks裁剪唇部区域大小到96x96
2.VCVTS系统结构设置
- VC系统
GRID和LRW数据集分别训练了两个VC系统, 使用Adam优化, 共训练了150个epoch, 前15个epoch学习率采用warmup策略从1e-6到1e-3, batch_szie=256.
绝大部分设置与VQMIVC的设置相同, 不同之处在于:- 话者编码器来自Resemblyzer, 输出是256维
- 内容编码器的VQ码本包含200个160维码字
- 基频预测器包含2层1D卷积(channels=384, kernel_size=3)+ReLU+LayerNorm+线性层, 输出为1维 F 0 F_0 F0值
- VC解码器基于Conformer, 包含4个block, 每个block包含: 384维2头attention+1536维FFN层+31x1卷积核大小
- Lip2Ind: 参考Lipreading using temporal convolutional networks
使用Adam优化方法训练了80epochs, 使用cosine scheduler, 初始学习率为3e-4, weight decay为1e-4, batch_size=32. 训练时也采用了一些数据增强方法, 比如将唇部视频大小随机裁剪到88x88, 水平翻转等等.- 3D-Transposed CNN: 上采样唇部视频序列2倍
- ResNet-18
- 4层多尺度时域CNN, 每个时域卷积包含3个分支, 卷积核大小分别为3, 5, 7
- softmax层: 预测索引的概率分布
- 声码器
- Griffin-Lim(GL)
- Parallel WaveGAN(PWG)
3.实验结果
- 基线系统: Lips2Wav和XTS, XTS仅在GRID数据集上训练.
- 客观和主观评估

结果分析如下: - 与集外说话人的结果相比,所有VTS系统都在集内说话人上实现了更好的性能,这表明VTS系统集外说话人的敏感性
- 本文的VCVTS系统在使用GL声码器的情况下, 在各项指标上对集内和集外说话人都取得了最高分; 这表明Lip2Ind网络可以准确地推断离散声学单元的索引,以生成更高质量的语音; 并且所提出的基频预测器可用于推断真实的 F 0 F_0 F0值,以控制音高轮廓更接近原始语音的轮廓
- 虽然使用PWG声码器 VCVTS在大多数指标上都优于基线,但它不如使用GL声码器的VCVTS,因为PWG基于神经网络并且倾向于引入会降低客观性能的声学伪影。
- 对于LRW数据集,使用GL或PWG声码器的VCVTS优于最先进的VTS系统(Lip2Wav),这表明在开放词汇的条件下,所提出的系统仍然可以使用Lip2Ind和VQ码本获得准确的声学单元,用于恢复语音内容。
- 在GRID数据集是上, 所有VTS系统的集外说话人的话者相似度都比集内说话人的话者相似度差,这是由于GRID用于训练的说话人数量有限, 导致对集外说话人的概括能力很差。 使用数百个说话人进行训练的LRW数据集可以缓解这个问题,
- VCVTS具有更高的MOS-SN和MOS-SS,这表明所提出的VCVTS继承了VC的优势,可以生成具有更高自然度和语音相似度的语音
- 对于所提出的 VCVTS,在主观评估上PWG优于GL,这表明PWG倾向于生成听起来更逼真的波形,从而提高了人类的感知质量。
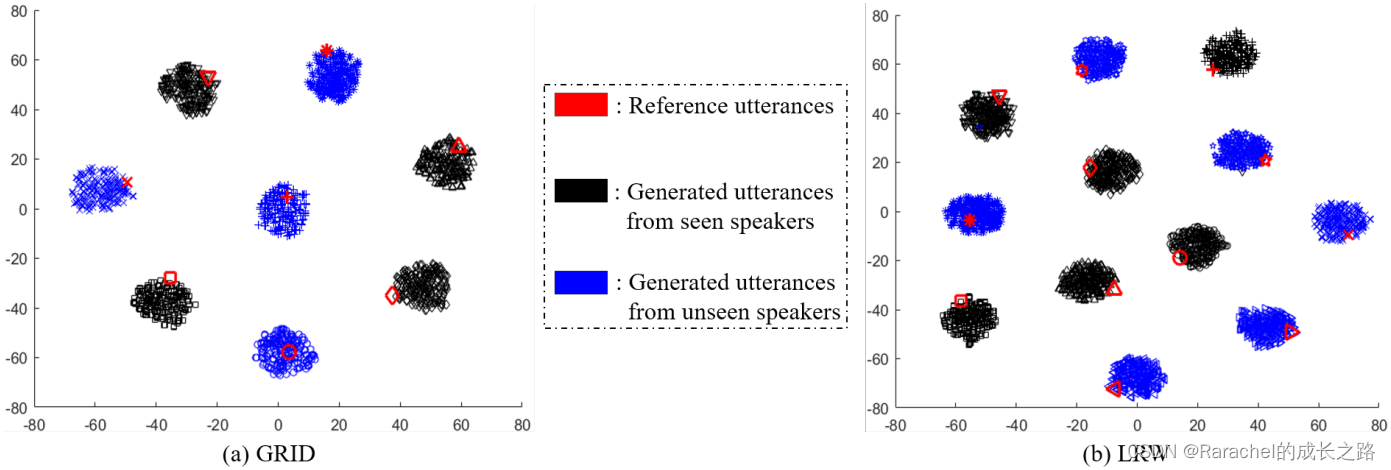
- 话者表示的可视化
从训练期间的不同说话人中选择参考语音来控制生成语音的说话人身份,生成语音的唇部视频序列是从测试说话人中随机选择的. 然后通过使用所提出的VCVTS中话者编码器提取参考和生成语音的话者表示,并通过嵌入空间中的t-SNE进行可视化.
总结
本文提出了VCVTS系统, 从唇部视频中恢复语音内容, 同时灵活控制生成语音的话者身份. 通过VC中的VQCPC内容编码器引导Lip2Ind网络的学习, 并利用VC中的话者编码器生成话者表示, 从而将VC的知识迁移到VTS系统中. 所提出的VCVTS系统, 唇部视频和语音之间的映射关系更加明显, 并且在受限和开放词汇下的效果都优于SOTA.















 459
459











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









