










文章目录
论文: Cross-Layer Similarity Knowledge Distillation for Speech Enhancement
原文地址: Cross-Layer Similarity Knowledge Distillation for Speech Enhancement. 本文是在阅读原文时的简要总结和记录。

Abstract
本文工作:提出了一种用于语音增强(Speech Enhancement, SE)的知识蒸馏(Knowledge Distillation, KD)框架,以压缩SE模型(如DCCRN)的大小
- Strategy: cross-layer connection path,将teacher的多层信息融合后转移给student
- Loss: 帧级相似性的蒸馏损失
Introduction
1. Motivation:为什么要对SE模型进行KD
- 越大的模型可以实现越好的性能,但同时具有高计算复杂度和内存消耗,难以部署到实际应用中;因此需要进行模型压缩,KD是一种常用的压缩手段
2.通用的KD方法:对中间特征表示进行变换
- PKT: 通过匹配特征空间的概率分布进行KD
- SPKD: 通过pairwise相似性建模知识
- knowledge review: 学习teacher-student模型的跨阶段联系(cross-stage connection paths)
3. 已有用于SE的KD工作:没有学习中间特征的表示
- 通过直接减小teacher和student输出的差异进行KD,如论文Teacher-Student Learning for Low-Latency Online Speech Enhancement Using Wave-U-Net
- 通过训练通用的sub-band增强模型进行KD,如论文Sub-Band Knowledge Distillation Framework for Speech Enhancement
4. 本文工作:为SE提出了一种cross-layer的KD框架
- 参考knowledge review,融合teacher的多层特征表示以知道student的一层进行学习
- 采用了帧级pairwise相似性距离(frame-level pairwise similarity distance)作为蒸馏损失
- 在DCCRN框架上有良好的蒸馏表现
Methodology
1. 框架综述
-
DCCRN
encoder/decoder: complex convolution/deconvolution layers
complex LSTM layers: 在encoder和decoder之间,用于建模时间相关性 -
KD: 总结构如下图所示
-
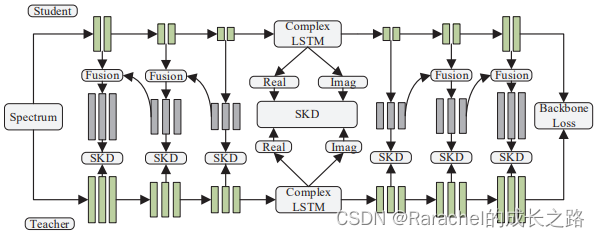
encoder/decoder: 采用residual learning strategy,通过融合多层teacher输出逐步提取有效信息
LSTM: 分别对实部和虚部的输出执行帧级相似度蒸馏(frame-level similarity distillation)
2. 特征融合(即encoder/decoder采取的KD策略)
- 基本说明
- 在实部和虚部的拼接后的输出上进行融合
- 为了保存teacher的有效信息,只对student的特征进行变换
- 记teacher网络第i层的输出为 F T i \bf{F}_T^i FTi,student网络每层的输出为 F s i \bf{F}_s^i Fsi
- one-to-one(即不采用特征融合)的蒸馏损失
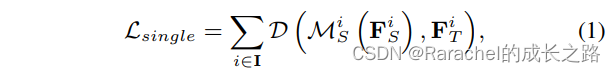
- M \mathcal{M} M表示特征变换
- D \mathcal{D} D表示中间特征的距离
- I \bf{I} I表示student模型需要蒸馏的中间特征表示的集合
- one-to-many的蒸馏损失
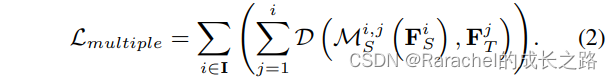
对于encoder来说,teacher的前i层指导student的第i层;对于decoder,teacher的后i层指导student的第i层 - 为了避免one-to-many蒸馏损失的复杂计算和多层特征之间的互相干扰,采用residual learning strategy
- 假设有
n
n
n层特征需要蒸馏,交换(2)式中的求和顺序,从而变换如下
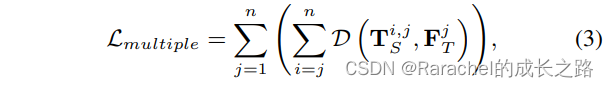
其中 T s i , j = M s i , j ( F s i ) \bf{T}_s^{i,j}=\mathcal{M}_s^{i,j}(\bf{F}_s^i) Tsi,j=Msi,j(Fsi); - 使用融合特征的距离近似距离对的和
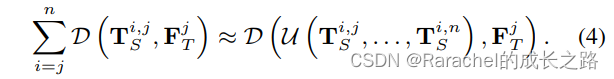
其中 U \mathcal{U} U是一个n维运算符,表示融合运算; - 将融合运算重新定义为递归函数
U
′
(
⋅
,
⋅
)
\mathcal{U}'(·,·)
U′(⋅,⋅),则融合蒸馏损失可以写作
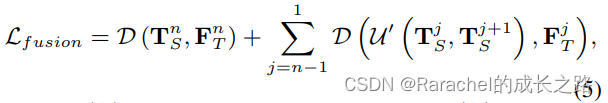
其中 T s j + 1 \bf{T}_s^{j+1} Tsj+1表示从 T s n \bf{T}_s^{n} Tsn到 T s j + 1 \bf{T}_s^{j+1} Tsj+1的融合
- 假设有
n
n
n层特征需要蒸馏,交换(2)式中的求和顺序,从而变换如下
- 递归融合过程如下图所示
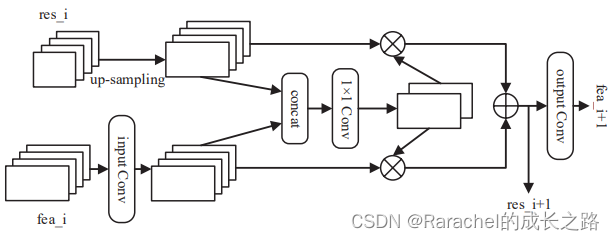
首先,使用上采样方法将高级特征调整为与低级特征相同的形状。
然后,使用1×1卷积对当前层特征和递归特征进行加权,并添加到更新中。
3. Frame-level Similarity Knowledge Distillation Loss: 同时实现维度压缩和相似性信息传递
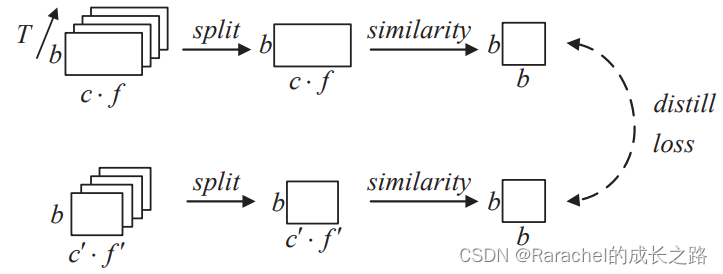
- 首先执行帧级的特征图分割
- 将每帧的特征图展平为2维,即第l层第j帧变换后的特征记作 Q T ( l , j ) ∈ R b × f ′ Q_T^{(l,j)}\in \bf{R}^{b \times f'} QT(l,j)∈Rb×f′
- 分别计算teacher和student的相似度矩阵,然后对矩阵的每一行进行L2归一化:
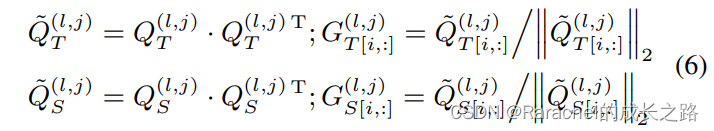
其中 [ i , : ] [i,:] [i,:]表示矩阵的第i行;相似度矩阵 G T ( l , j ) G_T^{(l,j)} GT(l,j)和 G S ( l , j ) G_S^{(l,j)} GS(l,j)的大小是 b × b b\times b b×b. - 第l层的蒸馏损失定义为所有帧相似距离的累加:
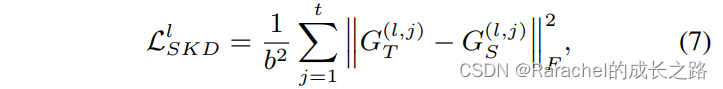
4. 训练过程
- 首先,利用多分辨率(MRSTFT)STFT Loss训练teacher模型,并在训练student模型的时候冻结teacher的参数
- 训练student的时候除了MRSTFT外,进行KD
- 给定编码器和解码器,student的特征首先进行特征融合,得到融合后的特征
T
S
l
\bf{T}_S^l
TSl,对应的teacher特征为
F
T
l
\bf{F}^l_T
FTl,利用相似度蒸馏损失计算Loss,
M
,
N
M,N
M,N表示编码器和解码器的层数
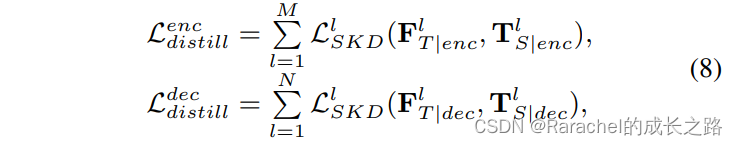
- 对于LSTM层,student的特征为
F
S
l
\bf{F}^l_S
FSl,teacher的特征为
F
T
l
\bf{F}^l_T
FTl,计算相似度蒸馏损失
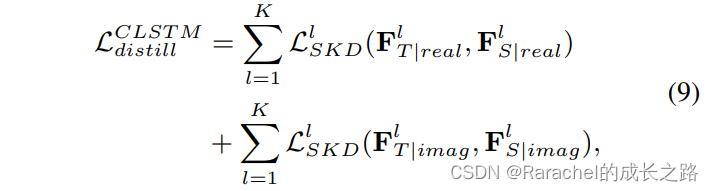
- 给定编码器和解码器,student的特征首先进行特征融合,得到融合后的特征
T
S
l
\bf{T}_S^l
TSl,对应的teacher特征为
F
T
l
\bf{F}^l_T
FTl,利用相似度蒸馏损失计算Loss,
M
,
N
M,N
M,N表示编码器和解码器的层数
- student训练的总损失是
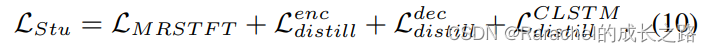
Experiments and Analysis
1. 数据集
2020 DNS Challenge Dataset: 500 hours of clean clips from 2150 speakers, 65,000 noise clips in a total of 180 hours.
2. 模型设置
- Baseline: DCCRN模型
- teacher model: kernel_size=(5,2), stride=(2,1), channels={32,64,128,256,256,256}, LSTM with128 units, 3.7M parameters
- student model: kernel_size=(5,2), stride=(2,1), channels={8,16,32,64,64,64}, LSTM with 32 units, 0.23M parameters
- feature fusion: kernel_size=(5,1)
3. 实验结果
- 未蒸馏 SE baseline: NSNet, RNNoise, DTLN
- 蒸馏方法baseline: 通过直接减小teacher和student输出的差异进行KD;PKT;SPKD;knowledge review
- 评价指标:WB-PESQ, STOI
- 实验结果
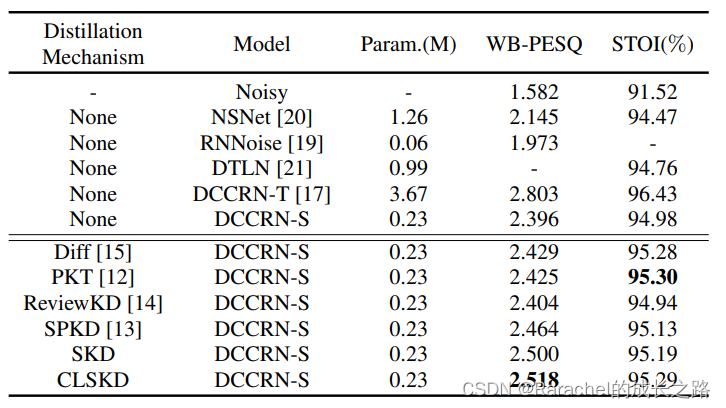
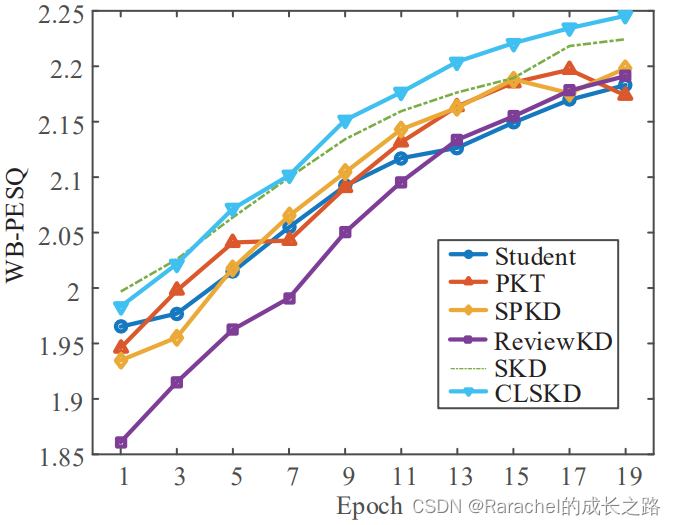
- 分析
- 与直接缩小输出距离的Diff方法相比,所提出的CLSKD对WB-PESQ有改进,这是由中间特征表示的蒸馏所带来的
- 作为特征蒸馏方法中的一种,PKT方法在STOI指标上表现出优势,但对WB-PESQ的改进有限
- SPKD在测试集和验证集上的综合表现略好于PKT,说明相对于概率分布,利用pairwise similarity以建模来自teacher的知识更适合SE领域
- 与SPKD相比,本文提出的帧级相似度蒸馏方法(SKD)在各项指标上都有进一步的提升
- 以HCL作为蒸馏损失的ReviewKD方法未能在两个指标上都取得优势, 这可能是由于 HCL 的下采样操作丢失了帧级有效信息
- CLSKD在WB-PESQ上排名第一,相当于STOI上的PKT,反映出在SKD的基础上引入跨层信息可以实现进一步的改进
Conclusion
本文为SE提出了一个新的知识蒸馏框架: teacher中多层的中间特征用于指导student中的一层,并计算帧级成对相似性距离作为蒸馏损失。 实验结果表明,所提出的跨层相似度蒸馏方法可以显着提高学生模型的增强效果优于其他蒸馏方法。

















 1652
1652

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









