







文章目录
论文:Online Clustered Codebook
原文地址:Online Clustered Codebook。本文是在阅读原文时的简要总结和记录。

Abstract
1.本文解决的任务
尽可能消除矢量量化(Vector Quantization, VQ)中出现的码本崩溃(codebook collapse)问题:即码本中只有一小部分码向量(codevectors)接收对其优化有用的梯度(称为活(alive)码向量),而其余码向量从未更新或使用(称为死(dead)码向量)。这一问题限制了码本在需要大容量表示的任务上的有效性。
2.本文提出的方法:Clustering VQ-VAE (CVQ-VAE)
选择编码特征作为锚点(achor)来更新“死”码向量,同时通过原始损失优化“活”码向量。
3. 本文得到的结果
- 所提出的CVQ策略使“死”码向量在分布上更接近编码特征,从而增加了被选择和优化的可能性。
- 在各种数据集、任务(例如重建和生成)和架构(例如 VQ-VAE、VQGAN、LDM)上验证了CVQ的泛化能力。 只需几行代码,CVQ-VAE 就可以轻松集成到现有模型中。
4. 本文的代码和模型地址
https://github.com/lyndonzheng/CVQ-VAE
Introduction
1.动机
在VQ的过程中,量化操作阻止梯度反向传播到代码向量,导致码本崩溃(即只有一小部分码向量与可学习的特征一起进行了优化,而码本中大多数码向量根本没有被使用)。 这一问题极大地限制了VQ的有效性,导致码向量利用率低而无法充分利用码本的表达能力,特别是当码本大小很大时。
2.本文贡献:CVQ-VAE
- CVQ的基本做法:仿照经典的聚类算法(例如k-means和k-means++),通过从学习到的特征中重新采样来动态初始化未优化的码本。
- CVQ的结果:避免码本崩溃,并通过优化所有码向量显着提高较大码本的使用率。
- CVQ的具体做法:计算不同minibatch的特征的运行平均值(running average),并使用它们来改进“死”码向量的动态重新初始化。
3. 实验结果
- CVQ-VAE 在相同设置下的各种数据集上显着优于以前的模型VQ-VAE和SQ-VAE。
- 对该方法的变体进行了彻底的消融实验,以证明CVQ设计的有效性并分析各种设计因素的重要性。
- 将 CVQ-VAE 合并到大型模型中(例如 VQ-GAN 和 LDM),进一步证明了其在各种应用中的通用性和潜力。
Related Work
Jukebox、HVQ-VAE、SQ-VAE、VQ-WAE。
Proposed Approach
考虑一张 x ∈ R H × W × c x\in\mathbb{R}^{H\times W\times c} x∈RH×W×c的图片,编码器输出特征为 z ^ = E ϕ ( x ) \hat{z}=\mathcal{E}_{\phi}(x) z^=Eϕ(x),被量化为离散码字 z q ∈ R h × w × n q z_q\in\mathbb{R}^{h\times w\times n_q} zq∈Rh×w×nq, n q n_q nq是码向量的维度,码本大小为 K K K。
1. 运行平均更新
- 首先累计计算每个training minibatch中码向量的平均使用情况:
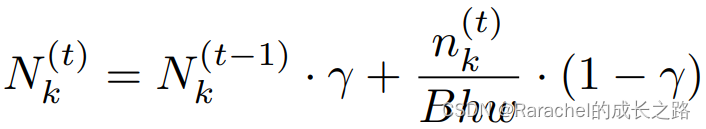
其中 n k ( t ) n_k^{(t)} nk(t)是training minibatch中将被量化为码向量 e k e_k e
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1225
1225

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









