







1.BST的基本概念
二叉树的其中一个重要应用,就是提供一种快速查找数据的方法,即将数据节点按照某种规律形成一棵二叉树,然后利用二叉树特殊的逻辑结构减少搜索数据的次数,提高查找效率。这种按照某中规律构建,用来提高搜索性能的二叉树,被称为搜索二叉树(Binary Search Tree),即BST。
具体而言,二叉树提高搜索效率的秘诀在于:按照"小-中-大"(当然"大-中-小"也是一样)的规律来存储数据,即对于任意一个节点,都可以明确找到其值大于或等于其左孩子节点,且小于或等于其有孩子节点,如图所示:
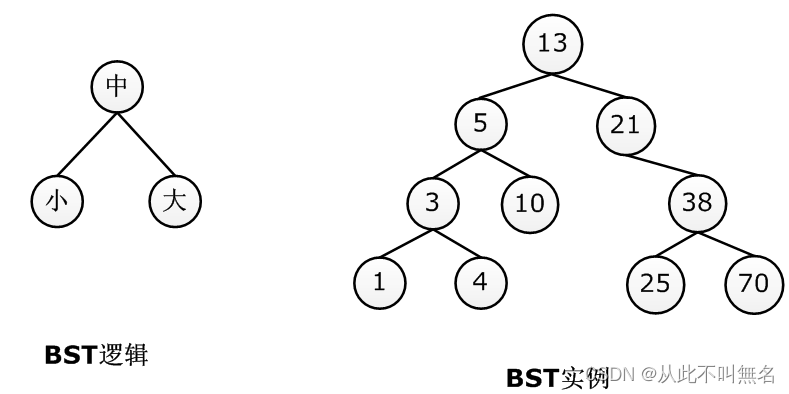
由于树中所有的节点均满足,“小-中-大”的规律因此当从根开始查找某个节点时速度比顺序查找要快的多,比如要找节点38,当发现38大于根节点13后,就可以确定13的左子树一定没有38,这就去掉了半边子树的节点
因此二叉搜索树又称为二叉排序树、二叉查找树。
实际上,对于一棵二叉树而言,其搜索节点的时间复杂度,最糟糕的情形是其退化成链表,最乐观的情形是完全二叉树,那么其搜索时间复杂度就是介于: 最差 : T(n)=O(n) 最优 : T(n)=O(log2n)
2.插入节点
对于BST而言,插入一个节点主要是要保持其"小-中-大"的逻辑不变,因此插入的的逻辑可以从根节点开始,一步一步寻找新节点的"最终归宿",比如在如下BST中,要插入新节点16,最终应该插入到节点17的左孩子处。
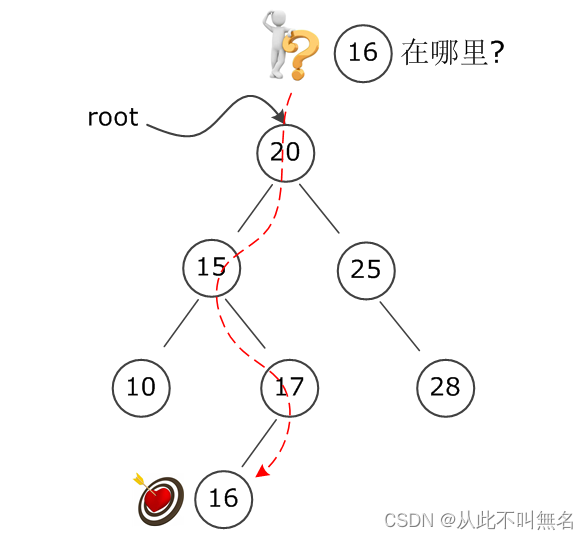
在实现插入算法的时候,由于树状结构本身是递归的,因此可以使用递归函数更优雅地实现插入算法。如下:
// 假设 BST 节点存储的数据类型是 int
node *newNode(int data)
{
// 准备好新节点,并将数据填入其中
node *new = (node *)malloc(sizeof(node));
if(new != NULL)
{
new->data = data;
new->lchild = NULL;
new->rchild = NULL;
}
return new;
}
// 将新节点new插入到一棵以 root 为根的 BST 中
// 插入节点后,返回新的 BST 的根
node *bstInsert(node *root, node *new)
{
// 若此时 BST 为空,则返回 new 使之成为二叉树的根节点
if(root == NULL)
return new;
// 若新节点比根节点小,那么新节点应该插入左子树中
// 至于插入到左子树的具体什么位置就不用管了,直接递归即可
if(new->data < root->data)
root->lchild = bstInsert(root->lchild, new);
// 若新节点比根节点大,那么新节点应该插入右子树中
// 至于插入到右子树的具体什么位置就不用管了,直接递归即可
else if(new->data > root->data)
root->rchild = bstInsert(root->rchild, new);
// 若已存在,则不处理
else
{
printf("%d已存在\n", new->data);
free(new);
}
return root;
}
「课堂练习3」
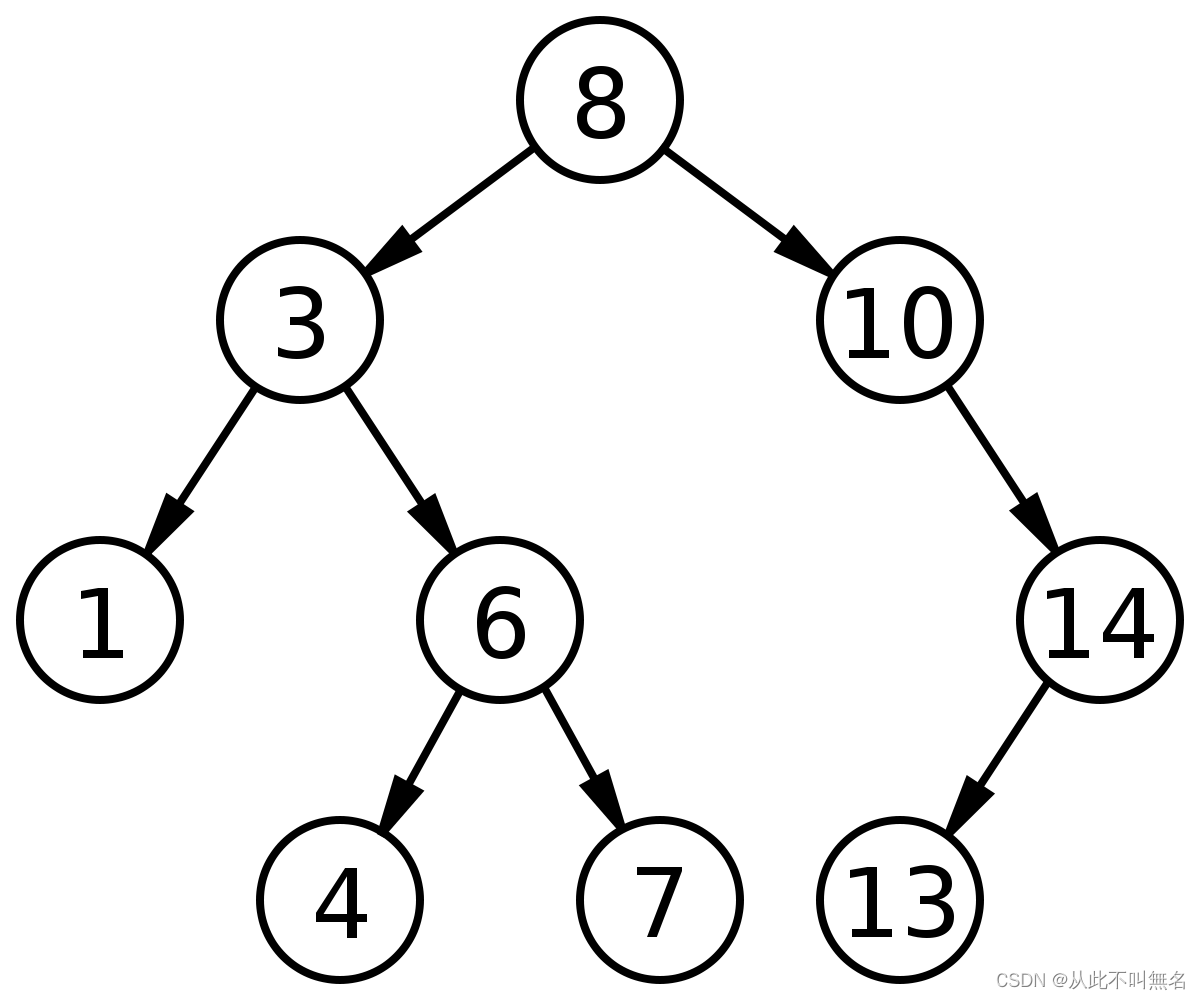
根据上述BST的插入算法,依次输入如下数据:8、3、1、6、4、7、10、14、13
创建如下二叉树:
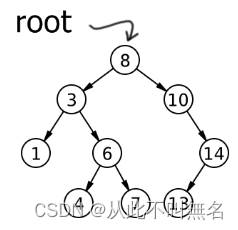
提示:
为了检验创建出来的二叉树是否正确,可以使用如下代码将二叉树以网页形式展现出来:
#define TREENODE node // 声明自定义的二叉树节点为TREENODE
#include "drawtree.h" // 包含画树代码
int main()
{
...
// 以网页形式展现二叉树
draw(root);
}
其中,node是自己定义的二叉树的节点的类型,在包含 drawtree.h 之前定义 TREENODE 这个宏为 node ,即可展示对应二叉树。
遍历代码
以上述练习中的二叉树为例,采用前、中、后序遍历的算法示例代码如下:
// 前序遍历
void preOrder(node *root)
{
if(root == NULL)
return;
// 先访问根节点
printf("%d", root->data);
// 再依次使用前序算法,遍历其左、右子树
preOrder(root->lchild);
preOrder(root->rchild);
}
「课堂练习4」
将下面这棵二叉树,按照前序、中序、后序方式,编程实现输出其各个节点的值。
删除节点
删除一个BST的节点要比插入困难一点,但同样是要遵循一个原则,即:删除节点后仍然要保持“小-中-大”的逻辑关系。
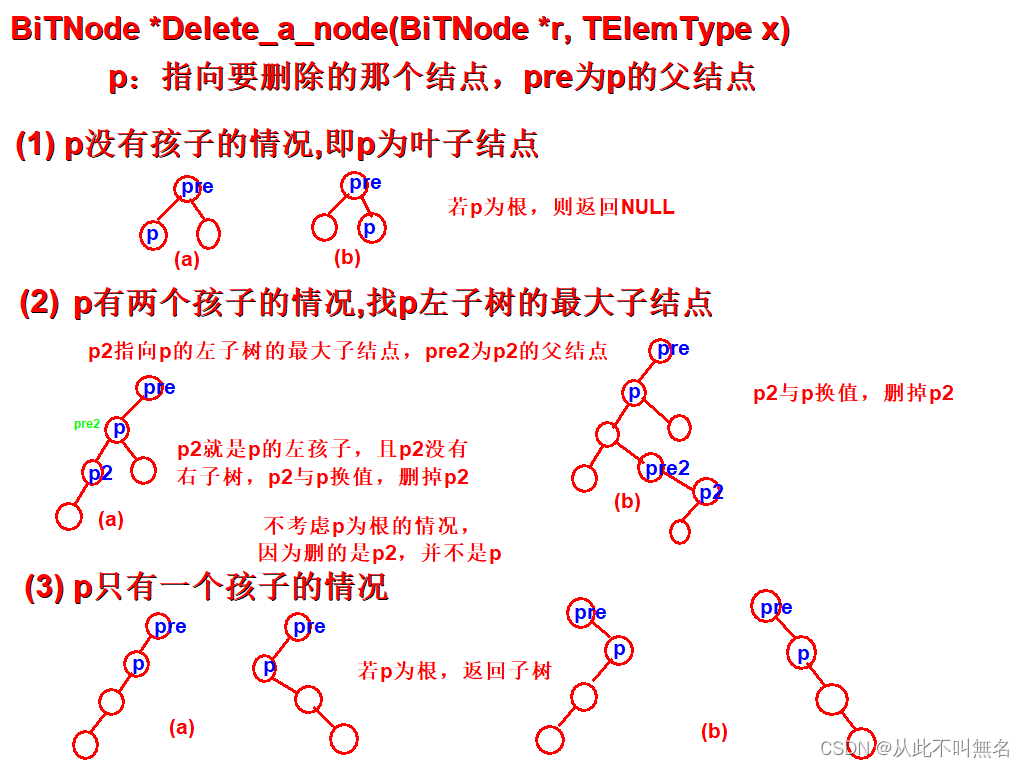
假设要删除的节点是x,大体思路如下:
-
若要删除的节点小于根节点,则递归地在左子树中删除x
-
若要删除的节点大于根节点,则递归地在右子树中删除x
-
若要删除的节点恰好就是根节点,则分如下几种情况:
a. 根节点若有左子树,则用左子树中最大的节点max替换根节点,并在左子树中递归删除max
b. 否则,若有右子树,则用右子树中最小的节点min替换根节点,并在右子树中递归删除min
c. 否则,直接删除根节点
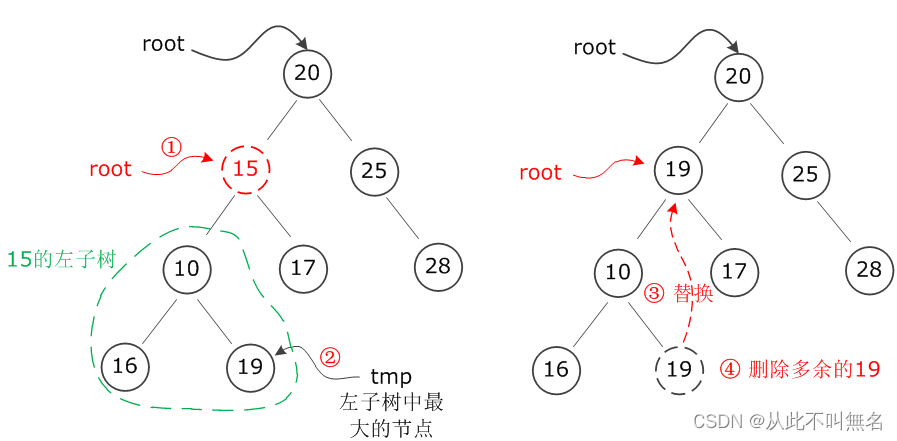
以下图为例,假设在一棵二叉树中要删除节点15,在找到节点之后,判断其有左子树,那么就沿着其左子树找到最右下角(最大)的节点19,替换要删除的节点15,然后再将多余的节点19删掉:
删除一个有左子树的节点过程
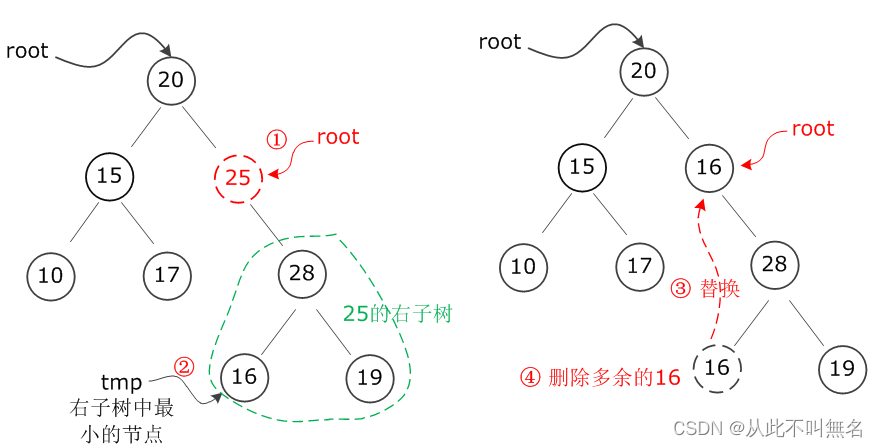
而如果要删除的节点没有左子树,只有右子树,那么情况是完全对称的,如下图所示,假设要删除节点25,由于25没有左子树,因此找到其右子树中最左下角(最小)的节点16,替换要删除的节点25,然后再将多余的节点16删掉:
删除一个只有右子树的节点过程
代码如下:
// 将数据(以整型为例)data从二叉树中删除
// 并返回删除之后的二叉树的根
node *bstRemove(node *root, int data)
{
if(root == NULL)
return NULL;
// 若data小于根节点,则递归地在左子树中删除它
if(data < root->data)
root->lchild = bstRemove(root->lchild, data);
// 若data小于根节点,则递归地在左子树中删除它
else if(n > root->data)
root->rchild = bstRemove(root->rchild, data);
// 若data恰好就是根节点,则分如下几种情况:
else
{
// a. 根节点若有左子树,则用左子树中最大的节点max替换根节点
// 并在左子树中递归删除max
if(root->lchild != NULL)
{
node *max;
for(max=root->lchild; max->rchild!=NULL;
max=max->rchild);
root->data = max->data;
root->lchild = bstRemove(root->lchild, max->data);
}
// b. 否则,若有右子树,则用右子树中最小的节点min替换根节点
// 并在右子树中递归删除min
else if(root->rchild != NULL)
{
for(tmp=root->rchild; tmp->lchild!=NULL;
tmp=tmp->lchild);
root->data = tmp->data;
root->rchild = bst_remove(root->rchild, tmp->data);
}
// c. 否则,直接删除根节点
else
{
free(root);
return NULL;
}
}
return root;
}















 1258
1258











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









